







一、知识梳理

二、问题总结
多分类SVM损失函数:

问题:为什么要选择加上1这个数?
其实在一定程度上是一个任意的选择,这实际上就是一个出现在损失函数中的常数,我们并不真正关心损失函数中分数的绝对值,关心的只是这些分数的相对差值,需要的是正确的分数远远大于不正确的分数,所以实际上如果把整个W参数放大或缩小,那么所有的分数都会放大或缩小。
三、重点补充
四、作业
1. Hinge Loss 表达式


2. 加正则的目的
正则化的宏观理念就是对模型做的任何事情主要目的是为了减轻模型的复杂度,而不是去试图拟合数据
L1正则化:更倾向于选择W1(倾向于让大部分元素接近0),使权重矩阵更为稀疏
L2正则化:它更能够传递x中不同元素值的影响,它的鲁棒性可能更好一点。它更倾向于是权重分布变得简单(即分布均匀且都较小,但极少出现等于0的情况)
3. Softmax 与交叉熵损失公式,分析交叉熵,分析交叉熵损失的最大值与最小值
1)Softmax:

交叉熵:
![]()
2)交叉熵的本质是使样本在正确类别上的评分最大 (因为是损失所以加了负号)
3)交叉熵损失的最大值与最小值:
答:最小值是0,最大值是无穷大。当对应的正确类别的概率为1时,log函数里的自变量就会是1,即真实类别所对应的概率,损失函数值就为0;同样,当对应的正确类别的概率为0时,log函数里的值是0时,损失函数值就趋向于无穷大,但基本不会出现这样的情况。
4. Hinge loss与Softmax的区别
步骤上:svm是求解正确分类分值和不正确分类分分值的差距,而softmax是将评分转化为个概率分布,损失为交叉熵其本质是时样本对应的正确类别的概率最大:
思想上:svm会得到这个数据点超过阈值要正确分类,然后不再关心这个样本,而softmax总是试图不断提高每一个样本。
五、作业
1. 梯度下降策略的公式与描述(sgd, adam)
1)SGD
由于批量梯度下降法在更新每一个参数时,都需要所有的训练样本,所以训练过程会随着样本数量的加大而变得异常的缓慢。随机梯度下降法(Stochastic Gradient Descent,简称SGD)正是为了解决批量梯度下降法这一弊端而提出的。
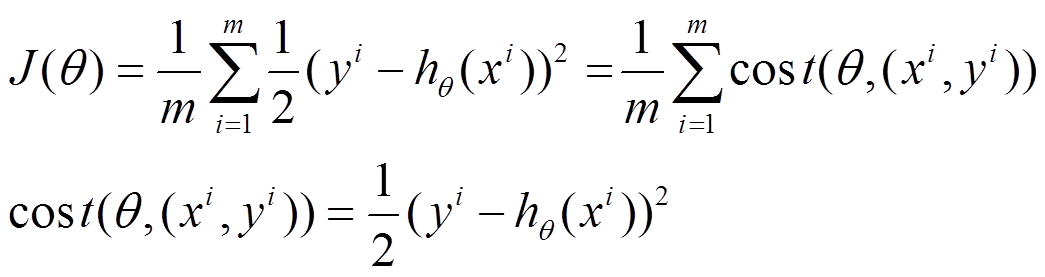
利用每个样本的损失函数对求偏导得到对应的梯度,来更新:
伪代码:

随机梯度下降是通过每个样本来迭代更新一次,如果样本量很大的情况(例如几十万),那么可能只用其中几万条或者几千条的样本,就已经将theta迭代到最优解了,对比上面的批量梯度下降,迭代一次需要用到十几万训练样本,一次迭代不可能最优,如果迭代10次的话就需要遍历训练样本10次。但是,SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。
2)Adam:
本质:Adam 算法和传统的随机梯度下降不同。随机梯度下降保持单一的学习率(即 alpha)更新所有的权重,学习率在训练过程中并不会改变。而 Adam 通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率。

2.图像识别两步走策略的步骤 ,输入图像特征的动机
步骤:提取特征,分类器分类;
动机:直接输入原始像素值传递给分类器的表现不是很好,通过特征提取将特征转化为线性可分或更加简单的分布形式,最后通过分类器使其达到较好的分类效果。
3. 常见的图像特征有哪些,任意选择两个进行描述(复习hog与sift)
1)方向梯度直方图:测量图像中边缘的局部方向并作为特征

2)词袋:从图像中进行小的随机快的采样,然后用K均值等方法将它们聚合成簇,得到不同的簇中心,这些簇中心可能代表了图像中视觉单词的不同类型;接着就可以利用这些视觉单词给图像进行编码,记录它们出现在图像中的次数。

4. 传统方式与神经网络处理图像问题有哪些不同点
传统方式是人工求解特征,神经网络是通过数据训练自主得到像素的特征。相比于传统方式,卷积神经网络的方法会更直接更有效率。
六、SVM代码——作业
1) Svm.ipynb softmax.ipynb每个函数的作用,及代码运行逻辑
SVM与softmax代码类似,因此放在一张图中。函数与代码逻辑对应(在标注中):

2) Hinge loss ,softmax loss梯度如何计算
Hinge loss:

softmax loss:

3) Svm ,softmax训练的损失函数及测试结果 权重可视化结果
SVM:
1)训练

2)测试

3)权重可视化:

softmax:
1)训练

2)测试

3)权重可视化















 6052
6052











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









