







 本文详细探讨了如何构建和优化多元线性回归模型,结合Python实战案例,介绍了数据探索、模型建立、虚拟变量设置、方差膨胀因子检测等关键步骤,旨在解决多元共线性问题,提高模型精度。
本文详细探讨了如何构建和优化多元线性回归模型,结合Python实战案例,介绍了数据探索、模型建立、虚拟变量设置、方差膨胀因子检测等关键步骤,旨在解决多元共线性问题,提高模型精度。
文章来源: 早起Python
作者:萝卜
前言
「多元线性回归模型」非常常见,是大多数人入门机器学习的第一个案例,尽管如此,里面还是有许多值得学习和注意的地方。其中多元共线性这个问题将贯穿所有的机器学习模型,所以本文会「将原理知识穿插于代码段中」,争取以不一样的视角来叙述和讲解「如何更好的构建和优化多元线性回归模型」。主要将分为两个部分:
- 详细原理
- Python 实战
Python 实战
Python 多元线性回归的模型的实战案例有非常多,这里虽然选用的经典的房价预测,但贵在的流程简洁完整,其中用到的精度优化方法效果拔群,能提供比较好的参考价值。
数据探索
本文的数据集是经过清洗的美国某地区的房价数据集
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv('house_prices.csv')
df.info();df.head()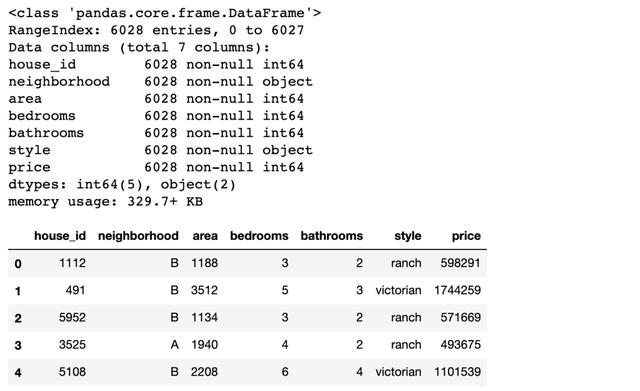
参数说明:
- neighborhood/area:所属街区和面积
- bedrooms/bathrooms:卧室和浴室
- style:房屋样式
多元线性回归建模
现在我们直接构建多元线性回归模型
from statsmodels.formula.api import ols
# 小写的 ols 函数才会自带截距项,OLS 则不会
# 固定格式:因变量 ~ 自变量(+ 号连接)
lm = ols('price ~ area + bedrooms + bathrooms', data=df).fit()
lm.summary()红框为我们关注的结果值,其中截距项Intercept的 P 值没有意义,可以不用管它
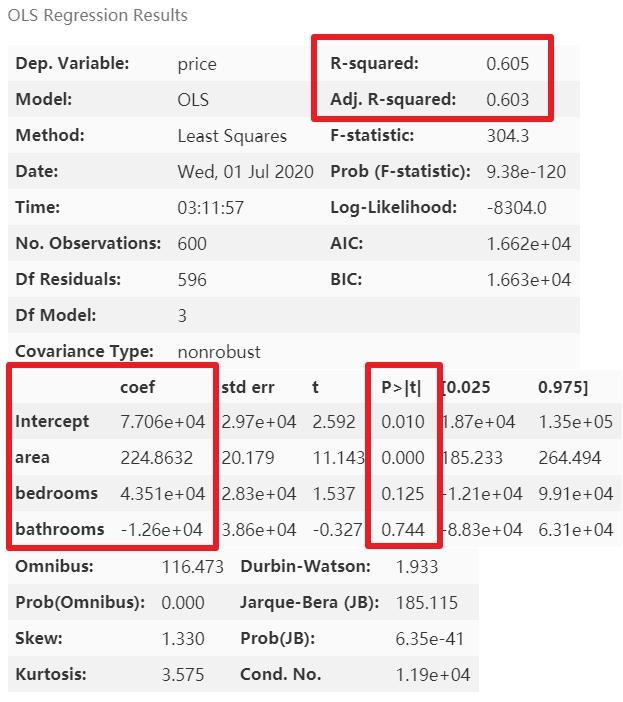
模型优化
从上图可以看到,模型的精度较低,因为还有类别变量
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









