






理想情况下,如果我们拥有无限多的样本,就可以训练出近乎完美的模型。但是绝大多数情况下这是不现实的,我们拿到的是有限的样本,样本量不足会导致模型过分的专注于这些样本的学习而不能够得到鲁棒性好、泛化能力强的模型,即会产生过拟合问题。
实际上,在深度学习的训练中,过拟合倒不是问题,因为我们在训练模型时都要将之训练到过拟合来查看当前模型当前样本的极限在哪里,我们只需保存到loss最低效果最好的模型权重即可。那真正的问题在哪里呢?问题在于过拟合之后我们得到的模型极限效果也还是达不到我们的预期要求。在样本无法继续采集的情况下,在现有样本的情况下进行数据增强就是一条很重要的解决之道了。
在此,我们专注讨论图片的数据增强问题。
imgaug库

imgaug库是专门用于图片增强的库,它有很多种图片增强方法,包括常规的水平翻转、竖直翻转、裁剪、旋转、模糊、增加噪点及其他的方法
下面给的是官网上的使用例子,更多使用方法请参考文档:https://imgaug.readthedocs.io/en/latest/index.html
import imgaug as ia
from imgaug import augmenters as iaa
import numpy as np
ia.seed(1)
seq = iaa.Sequential([
iaa.Fliplr(0.5), # 0.5的概率水平翻转
iaa.Crop(percent=(0, 0.1)), # random crops
#sigma在0~0.5间随机高斯模糊,且每张图纸生效的概率是0.5
iaa.Sometimes(0.5,
iaa.GaussianBlur(sigma=(0, 0.5))
),
# 增大或减小每张图像的对比度
iaa.ContrastNormalization((0.75, 1.5)),
# 高斯噪点
iaa.AdditiveGaussianNoise(loc=0, scale=(0.0, 0.05*255), per_channel=0.5),
# 给每个像素乘上0.8-1.2之间的数来使图片变暗或变亮
#20%的图片在每个channel上乘以不同的因子
iaa.Multiply((0.8, 1.2), per_channel=0.2),
# 对每张图片进行仿射变换,包括缩放、平移、旋转、修剪等
iaa.Affine(
scale={"x": (0.8, 1.2), "y": (0.8, 1.2)},
translate_percent={"x": (-0.2, 0.2), "y": (-0.2, 0.2)},
rotate=(-25, 25),
shear=(-8, 8)
)
], random_order=True) # 随机应用以上的图片增强方法将图片增强方法放到了sequence里,每次按顺序或随机在其中选择增强方法对图片进行增强,同时如果选择了此方法又可以用Sometimes方法以一定的概率应用此增强。
在做深度学习的图片任务时,通常需要处理大量的图片,常规来讲有三种方法进行图片的载入和训练:
- 将全部图片转成ndarray并全部载入内存,然后全部“喂进”模型训练。此种方法占用很大且显存占用很大;
- 将全部图片转成ndarray并全部载入内存,然后分批读取“喂进”模型训练。此种方法内存占用很大,显存占用不是很大;
- 分批读入图片并训练,此种方法内存占用不大显存占用也不大。
第一种方法不太可取,我们需要很大的显存来一次性训练所有图片数据,所以我们本文来讨论第2、3种,以笔者了解的方法为例。
自己写读入图片并返回ndarray的生成器,以生成器的方式分批进行图片的读取和训练:
def get_img(img_paths, img_size):
X = np.zeros((len(img_paths),img_size,img_size,3),dtype=np.uint8)
i = 0
for img_path in img_paths:
img = cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img,(img_size,img_size),interpolation=cv2.INTER_AREA)
X[i,:,:,:] = img
i += 1
return X
def get_X_batch(X_path, batch_size, img_size):
while 1:
for i in range(0, len(X_path), batch_size):
X = get_img(X_path[i:i+batch_size], img_size)
yield X以上两个函数即可不停地分批生成图片的ndarray,shape为(batch_size, height, width, channel)。
配合已经写好的图片增强函数,来看下效果:
from glob import glob
img_paths = glob('train/*') #得到所有图片的路径列表
images = get_X_batch(img_paths,16,300) #得到一个batch的图片,形式为generator
images = next(images) #next(generator),得到一个batch的ndarray
images_aug = seq.augment_images(images) #得到增强后的图片ndarray先来看下原图:
import matplotlib.pyplot as plt
%matplotlib inline
fig,axes = plt.subplots(4,4,figsize=(10,10))
j = 0
for i,img in enumerate(images):
axes[i//4,j%4].imshow(img)
j+=1
来看看增强后的图片:
fig,axes = plt.subplots(4,4,figsize=(10,10))
j = 0
for i,img in enumerate(images_aug):
axes[i//4,j%4].imshow(img)
j+=1
ImageDataGenerator
keras里定义了一个集成了生成器和图片增强的方——ImageDataGenerator。很多情况下使用它可以大幅度简化我们的图片处理和模型训练流程。以下是keras中文文档中列出的图片增强的选项参数,当然,考虑到文档的更新进度可能会慢于源码的进度很多,推荐阅读源码。

这里使用几个常用的仿射变换增强:
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator( #实例化
rotation_range = 90, #图片随机转动的角度
width_shift_range = 0.2, #图片水平偏移的幅度
height_shift_range = 0.2, #图片竖直偏移的幅度
zoom_range = 0.3) #随机放大或缩小先来看看flow方法
flow(X, y, batch_size=32, shuffle=True, seed=None, save_to_dir=None, save_prefix='', save_format='png')接收numpy数组和标签为参数,生成经过数据提升或标准化后的batch数据,并在一个无限循环中不断的返回batch数据,其生成方式大致如下:
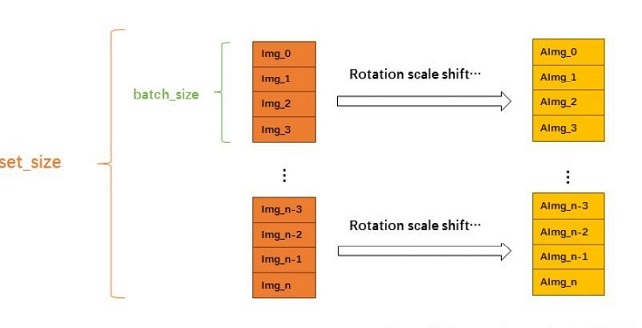
其需要我们将图片载入成(nub_samples, height, width, channel)的numpy矩阵。以一张图片为例:
img = cv2.imread('train/00afb07c10e8f614f6e66db73a4bc09a6d630d6d.jpg')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img,(300,300))
plt.imshow(img)
x = np.expand_dims(img, axis=0) #扩展成4维
gen = datagen.flow(x, batch_size=1)
# 显示生成的图片
plt.figure(figsize=(10,10))
for i in range(3):
for j in range(3):
x_batch = next(gen)
idx = (3*i) + j
plt.subplot(3, 3, idx+1)
plt.imshow(x_batch[0]/255)
flow方法需要我们先将图片读入内存,而flow_from_directory可直接从图片路径得到batch数据。此方法对图片的存储方式有要求,在根目录文件夹下,每个种类的图片单独存在到各自种类的文件夹内,形如:
|——train
|——class1
|——class2
|——class3
...其函数参数为:
flow_from_directory(directory, target_size=(256, 256), color_mode='rgb', classes=None, class_mode='categorical', batch_size=32, shuffle=True, seed=None, save_to_dir=None, save_prefix='', save_format='png', follow_links=False, subset=None, interpolation='nearest')参数中class_mode需特别注意,其可选"categorical", "binary", "sparse"或None之一. 默认为"categorical。该参数决定了返回的标签数组的形式, "categorical"会返回2D的one-hot编码标签,"binary"返回1D的二值标签,"sparse"返回1D的整数标签,如果为None则不返回任何标签。
一个使用flow_from_directory的例子:
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
test_datagen = ImageDataGenerator(rescale=1./255) #测试集不做增强
train_generator = train_datagen.flow_from_directory(
'data/train',
target_size=(150, 150),
batch_size=32,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
'data/validation',
target_size=(150, 150),
batch_size=32,
class_mode='binary')
model.fit_generator(
train_generator,
steps_per_epoch=2000,
epochs=50,
validation_data=validation_generator,
validation_steps=800)生成器要配合fit_generator函数来使用,其中如果使用的是keras自带的flow或flow_from_directory得到的生成器,steps_per_epoch参数可以不用填写,默认即可。如果自己写的生成器,此参数必须填写,一些写为steps_per_epoch = len(X_train)//batch_size,但是考虑到python中整除是向下取整,所以如果不能整除的话就不能得到全部图片,考虑到此问题可以写成steps_per_epoch = math.ceil(len(X_train)/batch_size),ceil函数向上取整。
对本文做下总结:
- 对于能够将不同类别的图片分到不同的文件夹内的图片集,我们可以直接采用
flow_from_directory进行图片的增强和生成器的读取。此方法不需要将图片读入内存,分批训练也可以根据自己的显存来选择batch_szie,小的显存选择小一些的batch_size。 - 如果数据集无法较好地将图片分至各自类别的文件夹,优先考虑自己写生成器函数和图片增强方法。其次如果内存足够可以将图片读入内存然后使用
flow方法。
——————————————————————————————————————
喜欢我的文章,或者希望了解更多机器学习、人工智能等相关知识、动态的小伙伴可以关注公众号,并进交流群。这里有一群志同道合的小伙伴可以一起交流学习、转行、打比赛等诸多经验。
















 4591
4591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









