



“他山之石,可以攻玉”,站在巨人的肩膀才能看得更高,走得更远。在科研的道路上,更需借助东风才能更快前行。为此,我们特别搜集整理了一些实用的代码链接,数据集,软件,编程技巧等,开辟“他山之石”专栏,助你乘风破浪,一路奋勇向前,敬请关注。
作者:limzero地址:https://www.zhihu.com/people/lim0-34
最近深入了解了下pytorch下面余弦退火学习率的使用.网络上大部分教程都是翻译的pytorch官方文档,并未给出一个很详细的介绍,由于官方文档也只是给了一个数学公式,对参数虽然有解释,但是解释得不够明了,这样一来导致我们在调参过程中不能合理的根据自己的数据设置合适的参数.这里作一个笔记,并且给出一些定性和定量的解释和结论.说到pytorch自带的余弦学习率调整方法,通常指下面这两个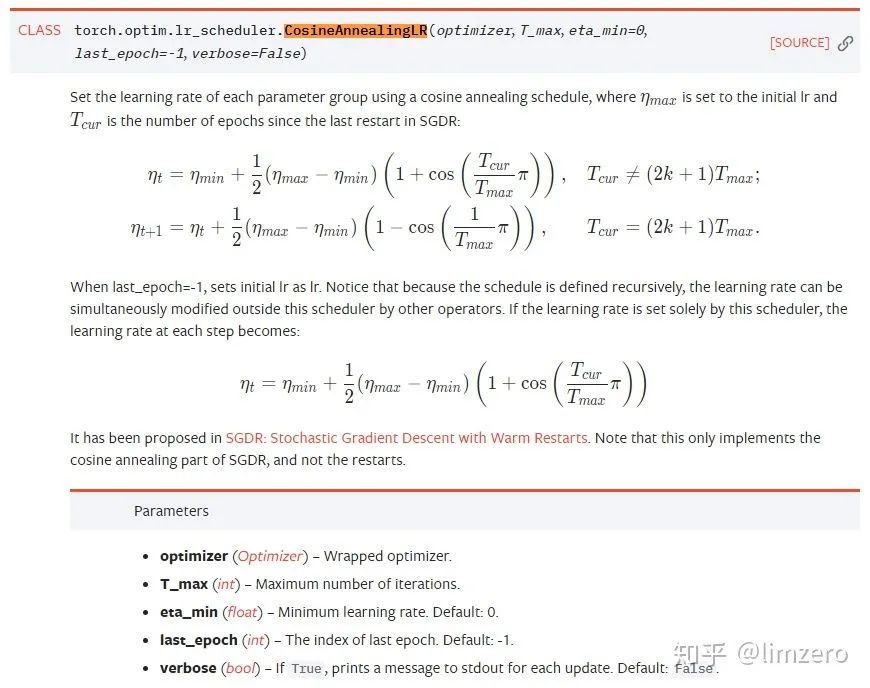 CosineAnnealingLR
CosineAnnealingLR CosineAnnealingWarmRestarts
CosineAnnealingWarmRestartsCosineAnnealingLR
这个比较简单,只对其中的最关键的Tmax参数作一个说明,这个可以理解为余弦函数的半周期.如果max_epoch=50次,那么设置T_max=5则会让学习率余弦周期性变化5次.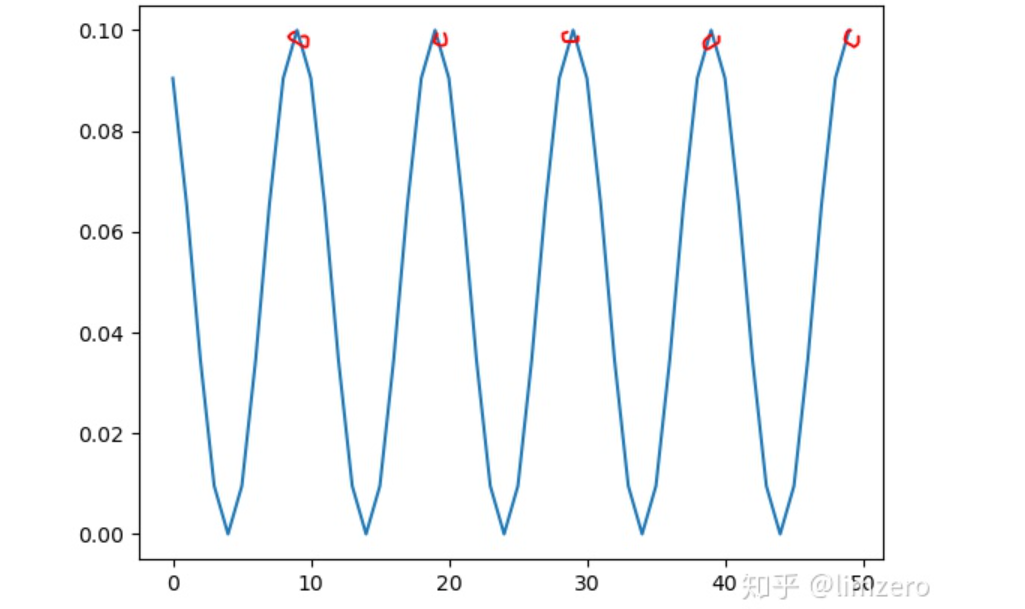
CosineAnnealingWarmRestarts
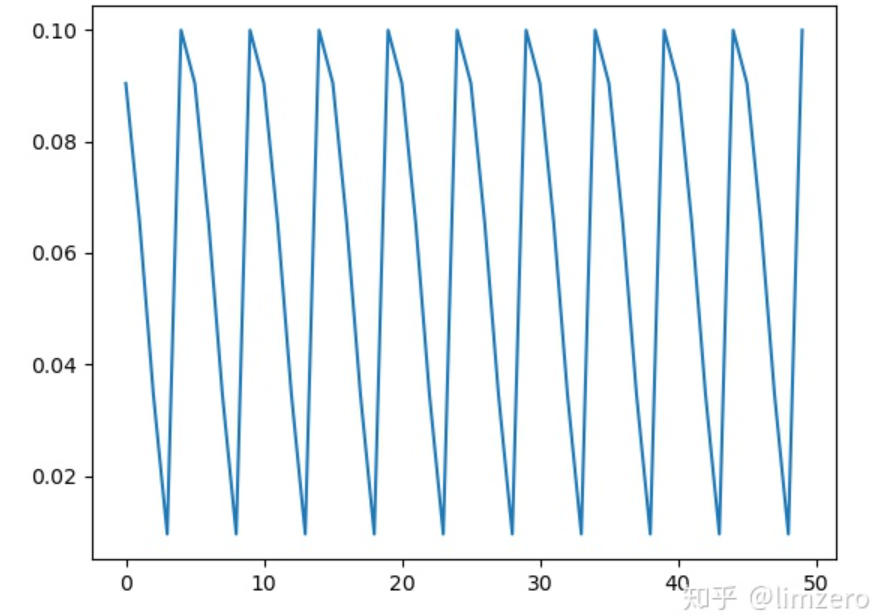
这个最主要的参数有两个:- T_0:学习率第一次回到初始值的epoch位置
- T_mult:这个控制了学习率变化的速度
- 如果T_mult=1,则学习率在T_0,2T_0,3T_0,....,i*T_0,....处回到最大值(初始学习率)
- 5,10,15,20,25,.......处回到最大值
- 如果T_mult>1,则学习率在T_0,(1+T_mult)T_0,(1+T_mult+T_mult**2)T_0,.....,(1+T_mult+T_mult2+...+T_0i)*T0,处回到最大值
- 5,15,35,75,155,.......处回到最大值
- 如果T_mult=1,则学习率在T_0,2T_0,3T_0,....,i*T_0,....处回到最大值(初始学习率)
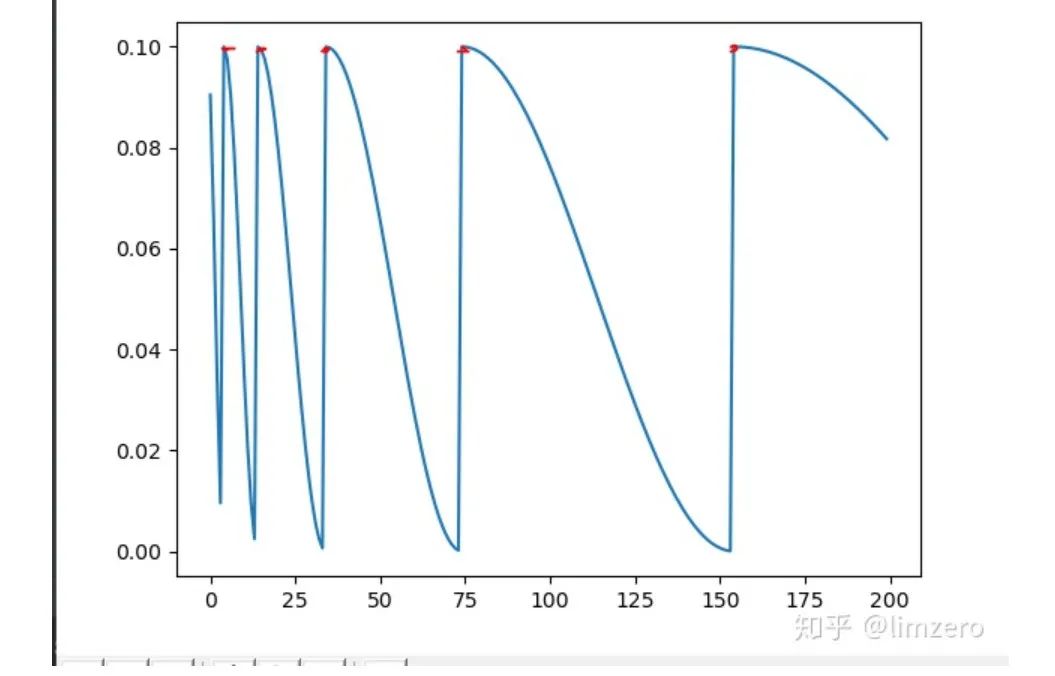
所以可以看到,在调节参数的时候,一定要根据自己总的epoch合理的设置参数,不然很可能达不到预期的效果,经过我自己的试验发现,如果是用那种等间隔的退火策略(CosineAnnealingLR和Tmult=1的CosineAnnealingWarmRestarts),验证准确率总是会在学习率的最低点达到一个很好的效果,而随着学习率回升,验证精度会有所下降.所以为了能最终得到一个更好的收敛点,设置T_mult>1是很有必要的,这样到了训练后期,学习率不会再有一个回升的过程,而且一直下降直到训练结束。
下面是使用示例和画图的代码:import torchfrom torch.optim.lr_scheduler import CosineAnnealingLR,CosineAnnealingWarmRestarts,StepLRimport torch.nn as nnfrom torchvision.models import resnet18import matplotlib.pyplot as plt#model=resnet18(pretrained=False)optimizer = torch.optim.SGD(model.parameters(), lr=0.1)mode='cosineAnnWarm'if mode=='cosineAnn': scheduler = CosineAnnealingLR(optimizer, T_max=5, eta_min=0)elif mode=='cosineAnnWarm': scheduler = CosineAnnealingWarmRestarts(optimizer,T_0=5,T_mult=1) ''' 以T_0=5, T_mult=1为例: T_0:学习率第一次回到初始值的epoch位置. T_mult:这个控制了学习率回升的速度 - 如果T_mult=1,则学习率在T_0,2*T_0,3*T_0,....,i*T_0,....处回到最大值(初始学习率) - 5,10,15,20,25,.......处回到最大值 - 如果T_mult>1,则学习率在T_0,(1+T_mult)*T_0,(1+T_mult+T_mult**2)*T_0,.....,(1+T_mult+T_mult**2+...+T_0**i)*T0,处回到最大值 - 5,15,35,75,155,.......处回到最大值 example: T_0=5, T_mult=1 '''plt.figure()max_epoch=50iters=200cur_lr_list = []for epoch in range(max_epoch): for batch in range(iters): ''' 这里scheduler.step(epoch + batch / iters)的理解如下,如果是一个epoch结束后再.step 那么一个epoch内所有batch使用的都是同一个学习率,为了使得不同batch也使用不同的学习率 则可以在这里进行.step ''' #scheduler.step(epoch + batch / iters) optimizer.step() scheduler.step() cur_lr=optimizer.param_groups[-1]['lr'] cur_lr_list.append(cur_lr) print('cur_lr:',cur_lr)x_list = list(range(len(cur_lr_list)))plt.plot(x_list, cur_lr_list)plt.show()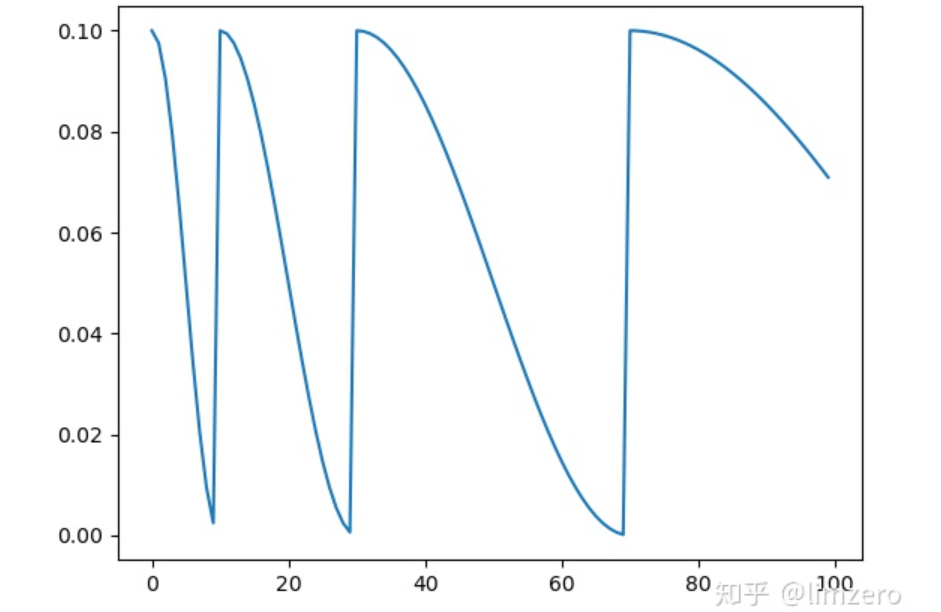
import torchfrom torch.optim.lr_scheduler import CosineAnnealingLR,CosineAnnealingWarmRestarts,StepLRimport torch.nn as nnfrom torchvision.models import resnet18import matplotlib.pyplot as plt#model=resnet18(pretrained=False)optimizer = torch.optim.SGD(model.parameters(), lr=0.1)mode='cosineAnnWarm'if mode=='cosineAnn': scheduler = CosineAnnealingLR(optimizer, T_max=5, eta_min=0)elif mode=='cosineAnnWarm': scheduler = CosineAnnealingWarmRestarts(optimizer,T_0=2,T_mult=2) ''' 以T_0=5, T_mult=1为例: T_0:学习率第一次回到初始值的epoch位置. T_mult:这个控制了学习率回升的速度 - 如果T_mult=1,则学习率在T_0,2*T_0,3*T_0,....,i*T_0,....处回到最大值(初始学习率) - 5,10,15,20,25,.......处回到最大值 - 如果T_mult>1,则学习率在T_0,(1+T_mult)*T_0,(1+T_mult+T_mult**2)*T_0,.....,(1+T_mult+T_mult**2+...+T_0**i)*T0,处回到最大值 - 5,15,35,75,155,.......处回到最大值 example: T_0=5, T_mult=1 '''plt.figure()max_epoch=20iters=5cur_lr_list = []for epoch in range(max_epoch): print('epoch_{}'.format(epoch)) for batch in range(iters): scheduler.step(epoch + batch / iters) optimizer.step() #scheduler.step() cur_lr=optimizer.param_groups[-1]['lr'] cur_lr_list.append(cur_lr) print('cur_lr:',cur_lr) print('epoch_{}_end'.format(epoch))x_list = list(range(len(cur_lr_list)))plt.plot(x_list, cur_lr_list)plt.show()本文目的在于学术交流,并不代表本公众号赞同其观点或对其内容真实性负责,版权归原作者所有,如有侵权请告知删除。

直播预告

“他山之石”历史文章
Pytorch转ONNX-实战篇(tracing机制)
联邦学习:FedAvg 的 Pytorch 实现
PyTorch实现ShuffleNet-v2亲身实践
详解凸优化、图神经网络、强化学习、贝叶斯方法等四大主题
史上最全!近千篇机器学习&自然语言处理论文!都这儿了
训练时显存优化技术——OP合并与gradient checkpoint
详解凸优化、图神经网络、强化学习、贝叶斯方法等四大主题
浅谈数据标准化与Pytorch中NLLLoss和CrossEntropyLoss损失函数的区别
在C++平台上部署PyTorch模型流程+踩坑实录
libtorch使用经验
系统梳理 Tensorflow、PyTorch 等深度学习框架,洞悉 AI 底层原理和算法
深度学习模型转换与部署那些事(含ONNX格式详细分析)
如何支撑上亿类别的人脸训练?显存均衡的模型并行(PyTorch实现)
NLP高阶实战必读:一文走遍完整自然语言处理流程
PyTorch trick 集锦

分享、点赞、在看,给个三连击呗!

















 8761
8761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









