






自学Python差不多已经半个多月了,这次拿《西游记》来做一个简单的统计分析,主要巩固基本语法和命令
- 导入数据
从网上找到《西游记》的txt文件,打开之后发现有大量的空白和标点符号,直接导入python中:
file_在读取文件的时候发生了点小错误,如果不加 encoding='utf-8',则会报错:
UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 2: illegal multibyte sequence经查询原来是因为gbk无法解码汉字。然后遍历文件,将每一个字作为一个单独的字符放在一个列表中:
l1=[]
l2=[]
#第一次循环得到每一行
for x in file_:
x=x.strip()
l1.append(x)
#第二次循环的到每一行的每一个字
for t in range(len(l1)-1):
for i in l1[t]:
l2.append(i)2. 用pandas进行分析
这里用pandas分析一是因为熟练一下pandas中的基本操作,二是因为经过测试发现用pandas要比python直接分析快很多(我用python中的字典分析会跑死)
import pandas as pd
data=pd.DataFrame(l2)
data=data.dropna()
print(len(data) )创建名为data的DataFrame,里面包含了所有的汉字和标点符号以及回车符,len(data)=716640,这说明里面总共有716640个字符,接着进行清洗:
data1=data.drop_duplicates() #删除重复值
count=pd.DataFrame(data.loc[:,0].value_counts()) #计算每个字符出现的次数
data2=pd.merge(data1,count,left_on=0,right_index=True,how='left') #将字符和次数联合
data2.columns=['name','counts'] #修改列名
data3=data2.sort_values(by='counts',ascending=False) #按照出现次数降幂排列
print(data3)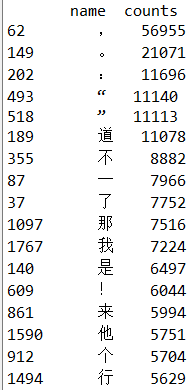
从表中可以发现出现最多的标点符号是逗号,出现最多的汉字是“道”,data3共有4511行,说明有4511个不同的字符
接着进行进一步的清洗,去除标点符号(这里一定要记得引入np,np.nan只属于numpy库):
import numpy as np
#先将标点符号转化为缺失值
data4=data3.replace([',','。',':','!',':','“','”','?','-'],np.nan)
#删除缺失值
data4=data4.dropna()
print(data4)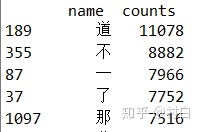
这样便得到了没有标点符号的数据库,data4共有4503行,说明大概有4503个不同的汉字(有可能一些数量较少的标点符号没有统计到)。这样的数据库可以方便检索,类似于字典一样,比如查找“我”字出现的次数:
br=data4['name']=='我' #返回name为 ‘我’的布尔数组
data4[br] #用布尔值进行检索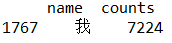
做索引时最开始想到的时用index,但是发现index只能用于字符串,不能用于DataFrame,所以只能用布尔索引来解决
3. 结论
(1)《西游记》共有716640个字符(包括标点)
(2)《西游记》约有4503个不同的汉字
(3)出现最多的汉字是“道”,出现最多的标点符号是逗号
4. 总结
本次练习难度不大,但是对于新手来说会出现各种小错误,本次统计还有很多可以改进的地方,后续会练习使用正则表达式来过滤字符串















 210
210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









