



 本文通过面板数据模型分析了中国东部、中部和西部地区进出口贸易、外商直接投资与经济增长之间的关系。首先进行面板单位根检验,发现变量存在一阶面板单位根。接着进行面板协整检验,揭示三大地区之间存在稳定的协整关系。在东部地区,出口对经济增长的拉动作用最为显著,其次是进口,而西部和中部地区的进出口和外资对经济增长的促进作用相对更强。最后,讨论了地区发展阶段、技术差异和资金产品丰富程度等因素对结果的影响。
本文通过面板数据模型分析了中国东部、中部和西部地区进出口贸易、外商直接投资与经济增长之间的关系。首先进行面板单位根检验,发现变量存在一阶面板单位根。接着进行面板协整检验,揭示三大地区之间存在稳定的协整关系。在东部地区,出口对经济增长的拉动作用最为显著,其次是进口,而西部和中部地区的进出口和外资对经济增长的促进作用相对更强。最后,讨论了地区发展阶段、技术差异和资金产品丰富程度等因素对结果的影响。
实证分析——以上海区级医院和社区卫生服务中心医生分布为例
面板数据模型建立过程遵循三个步骤。
首先,通过单位根检验,检验各面板数据序列的平稳性,以避免伪回归。
第二,开展协整检验或模型修正,防止出现伪回归问题。
第三,在前两步的基础上,进行模型设定检验,以确定选用哪一种面板数据模型。
3.1.2 面板数据模型的基本理论
面板数据模型的一般形式
面板数据模型的一般模型如下:

其中,i表示个体,t表示时间。横截面的个数为N,时间序列的维数为T。γit是被解释变量的第i个个体的第t时期观测值,χkit是第k个解释变量的第i个个体第t时期的观测值,βki是待估计参数,uit为随机误差项。用矩阵形式表示为

混合回归模型
混合回归模型是将面板数据混合在一起采用普通最小二乘法进行参数估计的面板数据模型,主要应用于不同个体在时间上不存在显著差异并且在不同截面之间也不存在显著差异的情况,即混合回归模型建立在解释变量对被解释变量的影响与个体无关的假设基础之上,这种模型在实际问题的研究当中应用较少。模型用公式表示为

用矩阵形式表示为

固定效应模型
固定效应模型是指斜率系数相同,而截距存在一定差异的模型。固定效应模型按截距的不同形式可以分为三种类型:个体固定效应模型、时间固定效应模型和时间个体固定效应模型。
固定效应模型一般采用LSDV估计法(The Least Sauare Dummy Variable Estimation)或者是ANCOVA估计法(The Analysis of Covariance Estimation)进行参数估计。
(1)个体固定效应模型
个体固定效应模型是指斜率系数相同而不同纵剖面(个体)截距不同的模型。用公式表示为

写成矩阵形式为

(2)时间固定效应模型
时间固定效应模型是指斜率系数相同而横剖面(时间点)截距不同的模型。用公式表示为

(3)时间个体固定效应模型
时间个体固定效应模型是指斜率相同而纵剖面(个体)和横剖面(时间点)都具有不同截距的模型。用公式表示为

随机效应模型
由于解释被解释变量的信息不够充分,固定效应模型往往通过设定虚拟变量来反映个体特征或者时间特征,或者是通过对模型截距项进行分解。但是固定效应模型存在一些不足,如固定效应模型是建立在一定的假设基础之上的。而实际情况并不能满足,并且虚拟变量的存在大大降低了模型的自由度,固定效应模型只考虑了确定性信息的效应,对于随机信息的效应未能得到有效考虑。随机效应模型可以在一定程度上弥补固定效应模型的这种不足。
随机效应模型将混合回归模型的随机误差项进行了分解,将其分解为三个部分:uit=ui+vt+wit,其中,ui表示个体分量,vt表示时间分量,wit表示混合分量。
随机误差模型又称为双因素误差分解模型。随机效应模型采用的参数估计方法为FGLS估计法(Feasible Generalized Least Square Estimation)。
变系数模型
混合回归模型、固定效应模型和随机效应模型都是建立在个体解释变量系数相同的基础之上,在一定程度上符合了实际情况,满足了分析的需要,但绝大多数情况并不满足这个假设。变系数模型是面板数据模型的一般形式,不但截距项不同,并且斜率系数也存在一定的差异。变系数模型经常采用的参数估计方法为广义最小二乘法(GLS)。
模型设定检验
有关面板数据模型设定的检验方法是许多学者关注的问题,不同学者提出了几种不同检验方法,下面简要介绍常见的模型设定检验方法。
(1)混合模型设定检验
混合模型的原假设为
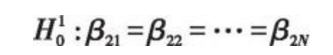
经常采用的检验统计量为Chow检验的F统计量:
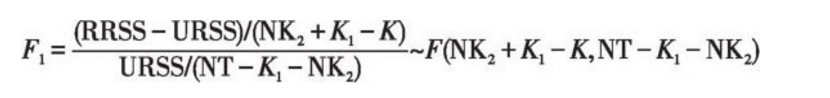
其中,URSS为无约束模型Yi=X1iβ1 +X2iβ2i+Ui, i=1,2, …, N的残差平方和,X1为前K1个解释变量,其系数与个体无关,X2为后K2个解释变量,其系数随个体变化。RRSS为有约束模型Y=Xβ+U的残差平方和。
(2)个体固定效应模型设定检验
(3)时间固定效应模型设定检验
(4)时间个体固定效应模型设定检验
(5)个体随机效应模型设定检验
(6)个体时间随机效应模型设定检验
(7)Hansman检验
3.2.6 模型建立与模型选择
本小节采用SAS软件的The TSCSREG Procedure模块进行分析,主要采用固定效应模型和随机效应模型进行分析,通过进行一系列模型设定检验,最后选择合适的分析模型。、
1. 混合回归模型
首先,在不考虑约束条件的情况下,进行混合回归分析,利用SAS软件建立模型,见表3-6~表3-8。
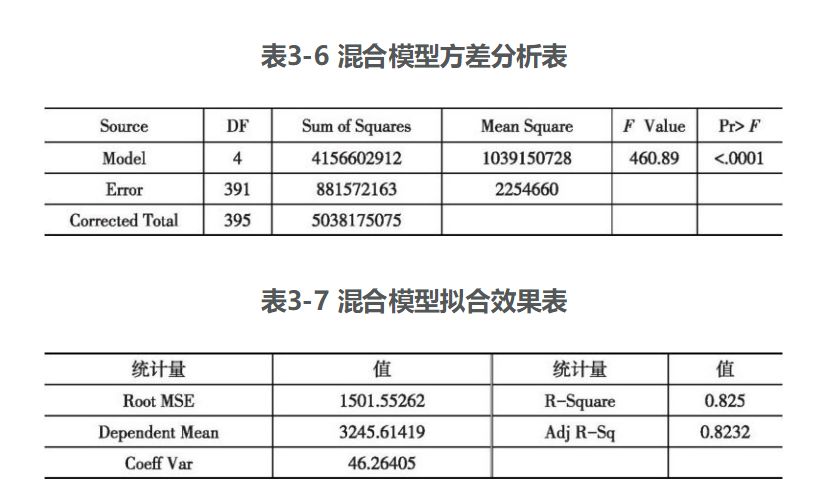
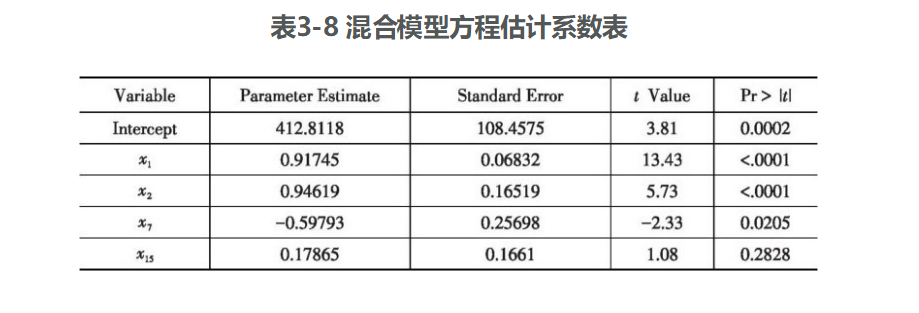
得出的混合回归方程为

但从表3-6、表3-7和表3-8来看,建立混合回归模型是不合适的,尽管R2和调整后的R2均大于0.82,并且方程F检验的p值小于0.001,方程整体上通过了显著性检验,但是方程中χ15的系数不显著。作者以为这主要是因为各个行业之间存在较大差距造成的,不适合做混合回归。下面将尝试建立固定效应模型和随机效应模型。
2. 固定效应模型
由于不适合采用混合回归模型,下面尝试建立固定效应模型,首先建立行业固定效应模型,利用SAS软件得以下数据。
(1)行业固定效应模型
利用SAS软件建立行业固定效应模型,见表3-9~表3-12。
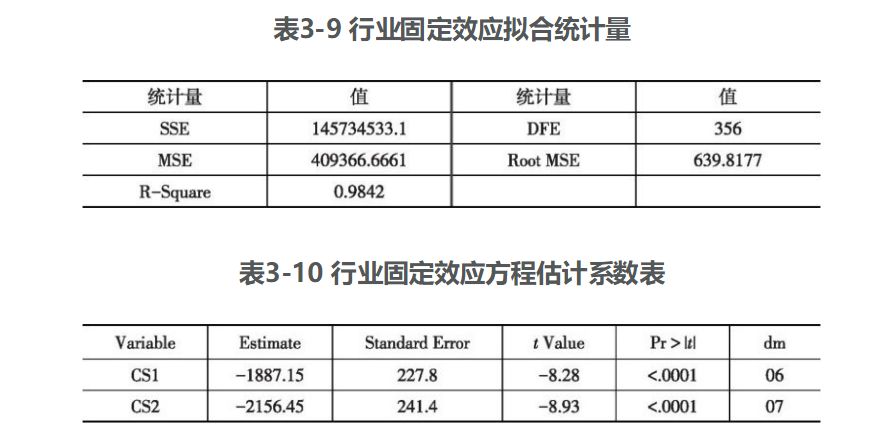
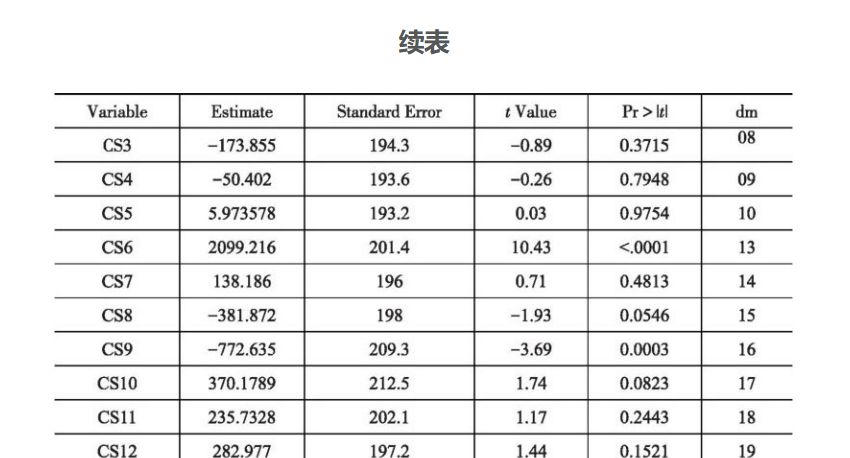
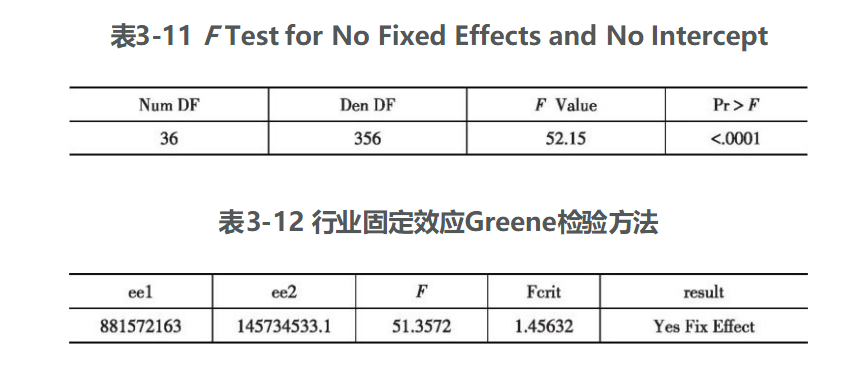
由表3-9和表3-10可以看出,模型拟合效果不错,R2达到0.9842,各变量系数基本上都通过了显著性检验。由表3-11和表3-12可以看出,SAS软件自动输出的固定效应检验的F统计量为52.15,对应p值小于0.001。为了保持研究结果的严谨性,编写SAS程序估计依据Greene方法构造的固定效应检验的F统计量为51.3572,大于临界值1.45632,说明存在行业固定效应,建立行业固定效应模型比建立混合模型更为合适。
由行业固定效应模型可以看出,制造业各行业出口的发展推动了制造业各行业的经济发展,出口每增长1个单位,工业总产值将增加0.53059个单位,出口贸易的发展不但为各行业提供了更广阔的市场,并且由于国外消费者更为挑剔,促使各行业不断提高生产技术水平,加速了各行业的产业升级。各个行业的截距不同,说明出口对各行业的影响存在一定的差距。
(2)时间固定效应模型
为寻找最优模型,下面建立时间固定效应模型。
模型拟合效果不错,R2达到0.9156。由表3-15和表3-16可以看出,SAS软件自动输出的固定效应检验的F统计量为6.11,对应p值小于0.001。为了保持研究的严谨性,编写SAS程序估计依据Greene方法构造的固定效应检验的 F统计量为5.11559,大于临界值1.85558,说明存在时间固定效应。但χ7和χ15的系数t统计量的p值大于0.05,没有通过显著性检验,因此建立时间固定效应模型是不合适的。
3.随机效应模型
(1)行业随机效应模型
前面建立了混合回归模型和固定效应模型,但前面建立的模型是否就是最优模型仍未可知,下面建立行业随机效应模型,利用SAS软件得以下数据,见表3-17~表3-20。
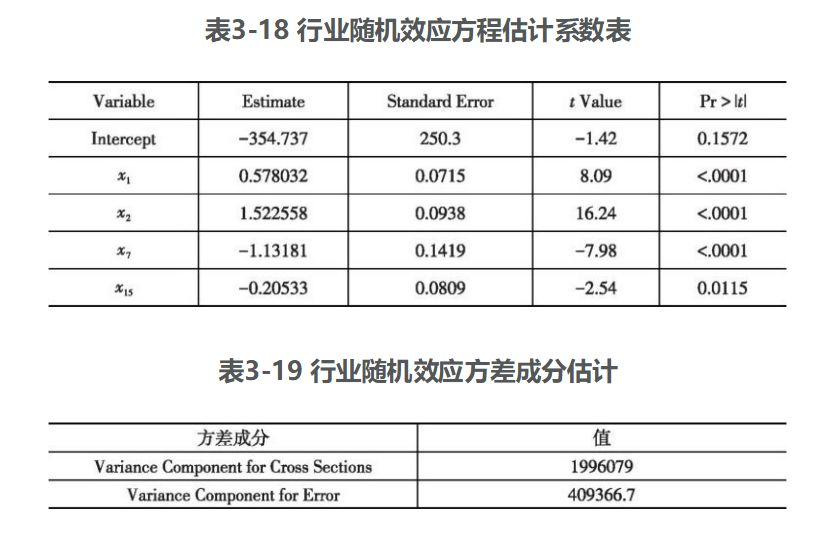
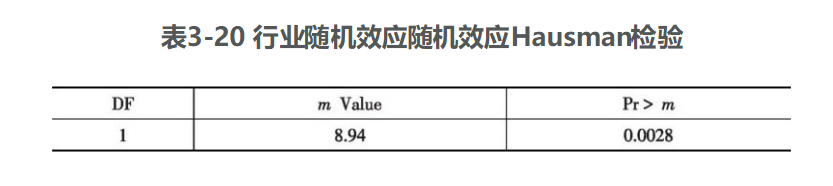
由表3-17可以看出,模型拟合效果不错,R2达到0.9131(小于行业固定效应R2)。由表3-19和表3-20可以看出,检验随机效应的Hansman-m统计量为14.68,对应p值为0.0028,小于0.01,说明存在行业随机效应。由表3-18可以看出,各变量系数t统计量的p值都小于0.05。
(2)时间随机效应模型
利用SAS软件建立时间随机效应模型。
由表3-21可以看出,模型拟合效果不错,R2达到0.8095(小于行业固定效应模型的R2)。由表3-24可以看出,检验随机效应的Hausman-m统计量为13.63,对应p值为0.0035,小于0.01,说明存在时间随机效应。由表3-22可以看出,χ7和χ15的t统计量的p值均大于0.05,没有通过显著性检验,因此建立时间随机效应模型是不合适的。
综上,行业固定效应模型是比较合理的模型,应该采用固定效应模型进行分析。
3.4 本章小结
本章主要利用面板数据模型对我国的行业数据进行了研究,首先分析了我国制造业各行业出口对制造业各行业经济的影响,通过模型选择和模型检验,建立了行业固定效应模型,发现出口贸易对我国制造业各行业产生了积极的推动作用,促进了制造业各行业的经济发展,出口每增长1个单位,工业总产值将增加0.53059个单位,但不同行业之间的截距不同,说明不同行业的出口对行业经济的影响存在一定的差异。相对处于优势地位的行业包括食品加工业、石油加工及炼焦业、有色金属冶炼及压延加工业、纺织业、金属制品业、电气机械及器材制造业、皮革毛皮羽绒及其制品业、木材加工及竹藤棕草制品业、服装及其他纤维制品制造业、食品制造业、塑料制品业、家具制造业和非金属矿采选业等行业,其中大部分为劳动密集型行业和资源型行业。相对来说,技术密集型行业和资本密集型行业仍处于劣势地位,说明我国的出口仍以劳动密集型产品和资源密集型产品为主,生产技术水平有待提高,加工工艺仍需改进,产业升级势在必行。
本章还对制造业各行业外商直接投资与制造业各行业出口的关系进行了探讨,通过模型选择和模型检验,建立了行业固定效应模型,通过分析发现外商直接投资是影响行业出口的重要因素之一,港澳台资本和外商资本的进入推动了我国制造业各行业的出口发展,并通过开展国际贸易进一步带动了制造业各行业的发展,但不同行业间的截距存在一定差异。处于相对优势地位的行业包括电子及通信设备制造业、仪器仪表及文化办公用机械制造业、煤炭采选业和烟草加工业等行业。
4.1.1 面板协整模型的提出和发展
面板数据模型相对于时间序列模型和横截面模型来说具有一定的优势,在一定程度上解决了样本量不足的问题,在经济研究中得到了广泛推广和应用。但随着经济社会的发展,面板数据的搜集越来越健全,面板数据的时期越来越长,与时间序列存在的不平稳性间题类似,当面板数据的时期较长时,面板数据模型也会面临非平稳的问题,此时,如果仍利用普通面板数据模型来处理非平稳数据便存在一定的劣势,据此得出的结论也值得商榷。
面板单位根检验和面板协整模型正是基于这种非平稳面板数据提出的,可以在一定程度上解决面板数据的非平稳性问题,是一种处理非平稳面板数据的有效方法。
面板单位根检验和面板协整检验是20世纪末兴起的一种统计分析方法,有效地改进了普通面板数据模型在处理非平稳面板数据时的劣势,通过对面板数据进行面板单位根检验、面板协整检验和面板协整估计,有效地提高了估计的准确性,可以在一定程度上防止出现伪回归问题。该方法的提出推动了面板数据模型的发展,扩大了面板协整模型在经济管理中的应用。
面板单位检验方法是在Fisher的检验方法基础上提出的,Maddala和Wu等学者对Fisher的检验方法进行了改进,提出了Fisher-ADF检验和Fisher-PP检验。Kao于1999年提出了基于Engle-Granger的Kao-ADF面板协整检验方法。有关面板协整的估计比较常见的有FMOLS估计和DOLS估计,Pedroni于1999年提出了基于Pool panel Fmols估计法(phillips,Hanson,1990)的Group Mean Panel Fmols估计法。
4.1.2 面板协整模型的基本理论
面板单位根检验
关于面板单位根检验主要介绍Fisher-ADF和Fisher-PP检验,该检验方法最初由Fisher在1932年提出,用于检验异质面板单位根。
Maddala和Wu(1999)以及Choi(2001)对该检验方法进行了发展和改进,其方法如下:定义πi为任意第i个截面单位根检验的p值,该检验的原假设为N个截面存在单位根,检验统计量为
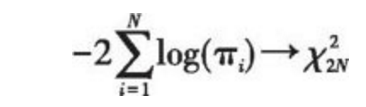
面板协整检验
关于面板协整检验存在多种检验方法,本部分介绍基于Engle-Granger方法的Kao ADF检验法,这种检验法是Kao在1999年提出来的。ADF检验主要基于以下回归方程。
面板协整估计
关于面板协整的估计目前存在多种估计方法,本部分主要介绍由Pedroni提出来的Group Mean Panel Fmols估计法,这种估计方法是对Phillips& Hanson(1990)估计法的发展和改进,相对于Pool Panel Fmols法来说效果更好,更加适用于实证分析。
4.3.3 面板单位根检验
为了检验面板数据是否满足平稳性,本部分采用Eviews 7.2软件对各个变量序列进行面板单位根检验,选用的方法为检验异质单位根的ADF检验(包括ADF - Fisher检验以及ADF - Choi检验),通过分析得到ADF-Fisher Chi-square统计量和ADF-Choi Z-stat统计量,见表4-1。
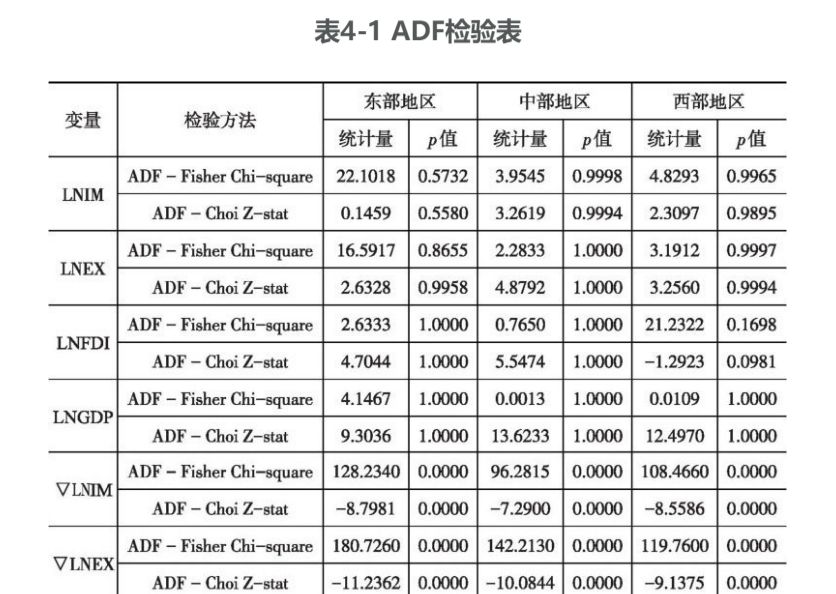
注:原假设为存在异质面板单位根。
由表4-1可以看出,不论是东部地区、中部地区还是西部地区,未差分的四变量LNIMit、LNEXit、LNFDIit、LNGDPit的ADF-Fisher Chi-square统计量和ADF-Choi Z-stat统计量的p值均大于0.05,不能拒绝原假设,说明未差分的四变量均为非稳定变量。而一阶差分后的四变量的ADF-FisherChi-square统计量的p值都小于0.05,这说明这四个一阶差分变量都是稳定变量,因此,这三大地区的四个变量都存在一阶面板单位根,即LNIMit~I(1)、LNEXit~I(1)、LNFDIit~I(1)、LNGDit~I(1)。
4.3.4 面板协整检验
由于这三大地区的各个变量都存在面板单位根,属于非平稳面板数据,不满足平稳性条件,不能利用普通的面板数据方法来进行研究,需要进行面板协整检验。我们采用Eviews 7.2软件,选用其中的Kao ResidualCointegration Test检验法来对三个地区的各个变量进行面板协整检验,得结果如下:1.东部地区面板协整检验利用Eviews 7.2软件对东部地区的四变量进行Kao ResidualCointegration Test检验,见表4-2~表4-4。
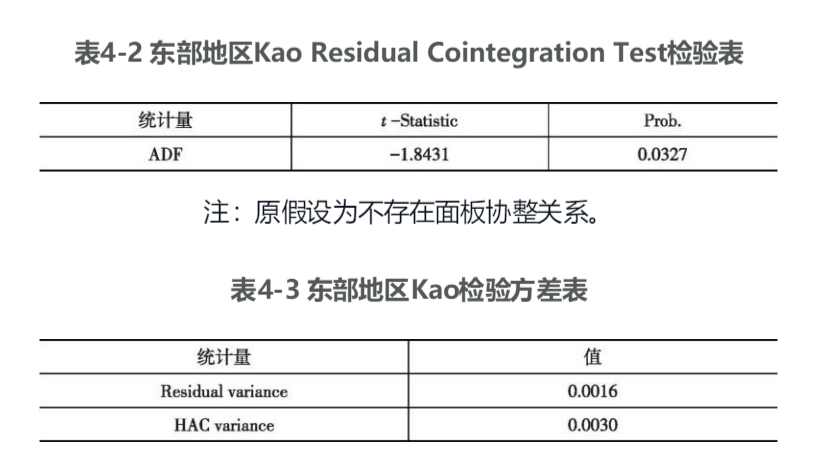
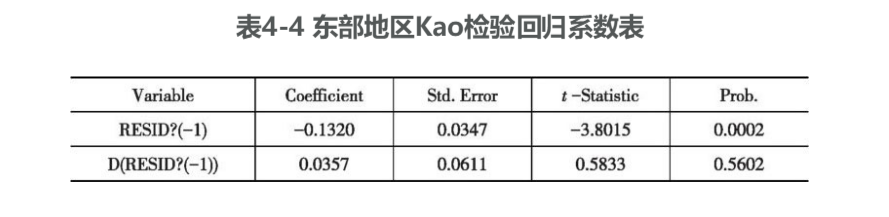
由表4-2~表4-4可以看出,Kao统计量的p值为0.0327小于0.05,拒绝原假设,说明东部地区的四个变量LNIMit、LNEXit、LNrDIit、LNGDPit之间存在稳定的面板协整关系,其中,表4-4的各个系数均显著,也可以得出相同的结论。
4.3.5 面板协整估计(FMOLS估计)
关于面板协整估计,本小节采用Winrats 7.0软件来进行估计,选用Pedroni提出的Group Mean Panel Fmols估计方法,估计得到如下结果:
1. 东部地区面板协整估计
首先对东部地区的四变量进行面板协整估计(FMOLS估计),利用Winrats7.0软件进行估计得以下结果。
面板群的完全修正普通最小二乘法(FMOLS)估计:
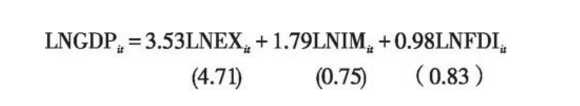
整体而言,我国东部地区的出口、进口和利用外资对经济增长具有一定的促进作用,其中出口的拉动作用非常明显,其次是进口的拉动作用,利用外资的拉动作用最小。
我国东部地区各个省区市的FMOLS估计结果见表4-11。
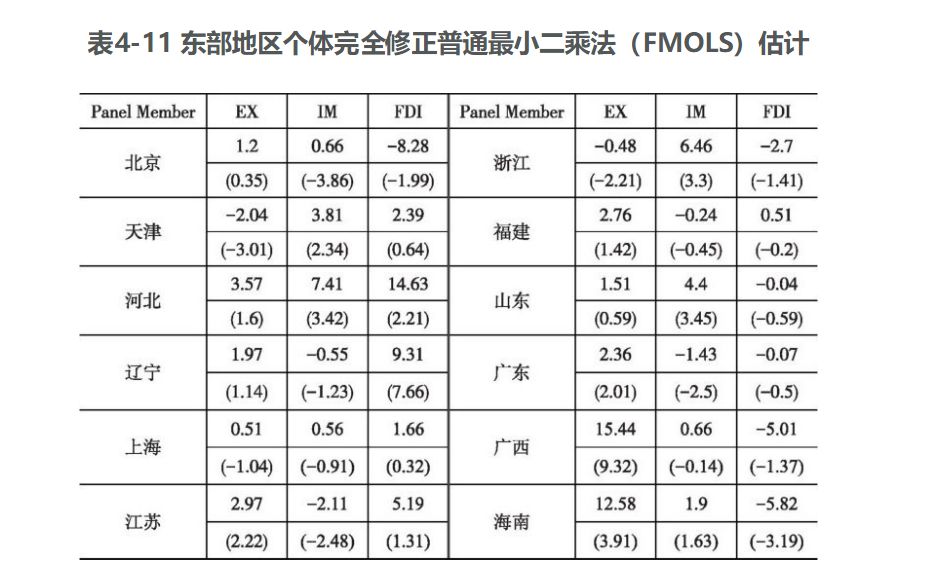
由表4-11可以看出,我国东部地区的各个省区市之间存在较大差异,不同省区市之间的进口、出口和利用外资等对经济增长的影响也存在较大差异。其中出口对我国东部各个省区市经济增长的影响比较稳定,并且其系数大于进口和利用外资的系数,说明近年来发展外向型经济大大推动了东部各省区市的经济发展。
4.3.6 实证分析结论
通过上面分析不难发现,三大地区的进出口贸易、利用外资与经济增长之间均存在稳定的面板协整关系。三大地区的进出口贸易和利用外资都对经济增长起到了一定的促进作用。并且三大地区之间存在较大的差异,进出口贸易和利用外资对西部地区和中部地区的拉动作用要高于对东部地区的拉动作用。出现上述特征的原因,著者认为主要包括以下几个方面:
1. 发展阶段存在差异
我国东部地区、中部地区和西部地区之间经济发展存在着比较明显的差异,可以说三大地区之间处于不同的发展阶段。我国的东部地区已经处于相对发达的发展阶段,并且我国东部沿海地带的地理位置优越,是我国经济发展的主引擎,但我国东部地区的经济总量较大,除了进出口和利用外资以外还有许多新的经济增长点,已经产生了新的内生经济增长因素;我国的西部地区还处于比较落后的发展阶段,进出口和利用外资在其经济总量中的比重相对较大,加上近年来的西部大开发浪潮以及边境贸易的蓬勃发展,使得其对经济增长的拉动作用比较明显;我国中部地区的发展阶段介于东部和西部之间,既没有东部的临海优势和技术优势,也缺乏西部地区开展边境贸易的便利条件,正处于经济结构调整的转型时期。
2.技术差异
我国东部地区、中部地区和西部地区之间的技术差异比较明显,我国东部地区集中了大部分的教育和科技资源,对新技术的吸收转化能力较强,但与发达国家相比仍缺乏核心技术,产业升级已势在必行,再加上近年来工资上涨的压力大增,使得东部地区的外向型经济面临着较大压力和挑战。与东部相比,中西部地区具有一定的劳动力成本优势,但同时也面临着技术水平较低、吸收转化能力不足的弱点。
3.资金和产品的丰富程度差异我国东部地区的资金相对比较丰富,企业的资金压力相对较小,对外资的依赖程度逐渐降低,而中西部地区的资金相对匮乏,因此,外资的进入会对经济发展产生更为明显的促进作用。中西部地区的产品比较匮乏,发展进出口贸易会对经济发展产生较强的推动作用。因此,应该针对不同地区的对外贸易和利用外商投资的特点,因地制宜地制定对外贸易政策与区域发展策略。对于东部地区应该继续保持和巩固目前的对外贸易政策,加快产业结构升级,提高企业的创新水平,尽快获得核心技术,提高产品的附加值,实现外贸的良性发展;中部地区应该继续开拓对外贸易和利用外商投资的途径,尽快提高技术水平,提高吸收转化能力,并加强与东部地区和西部地区的合作;西部地区应该抓住西部大开发的机遇,大力发展边境贸易,并提高利用外资的水平和质量,引进先进的技术和管理经验,体现后发优势,促进经济的快速发展。
4.4 本章小结
本章主要采用面板协整模型分析了我国的东部地区、中部地区和西部地区的进出口贸易、实际利用外商直接投资与各地区经济增长之间的关系。由于面板数据为非平稳序列,因此,首先对各个面板数据进行面板单位根检验,发现均存在一阶面板单位根,然后进行面板协整检验,发现三大地区的进出口贸易、实际利用外资和各地区经济增长之间存在稳定的面板协整关系,最后,对三大地区分别建立了FMOLS面板协整估计。
通过面板协整估计发现,三大地区的进出口贸易、利用外资与经济增长之间均存在稳定的面板协整关系。三大地区的进出口贸易和利用外资都对经济增长起到了一定的促进作用。并且三大地区之间存在较大的差异,进出口贸易和利用外资对西部地区和中部地区的拉动作用要高于对东部地区的拉动作用。随后对出现这种现象的原因进行了初步探讨。
THE LAST PERIODS:
读文1:导论——背景、意义、目的、方法、思路、结构安排、创新点
读文2:概念诠释
读文3:模型设定检验

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









