





OUTLINE:



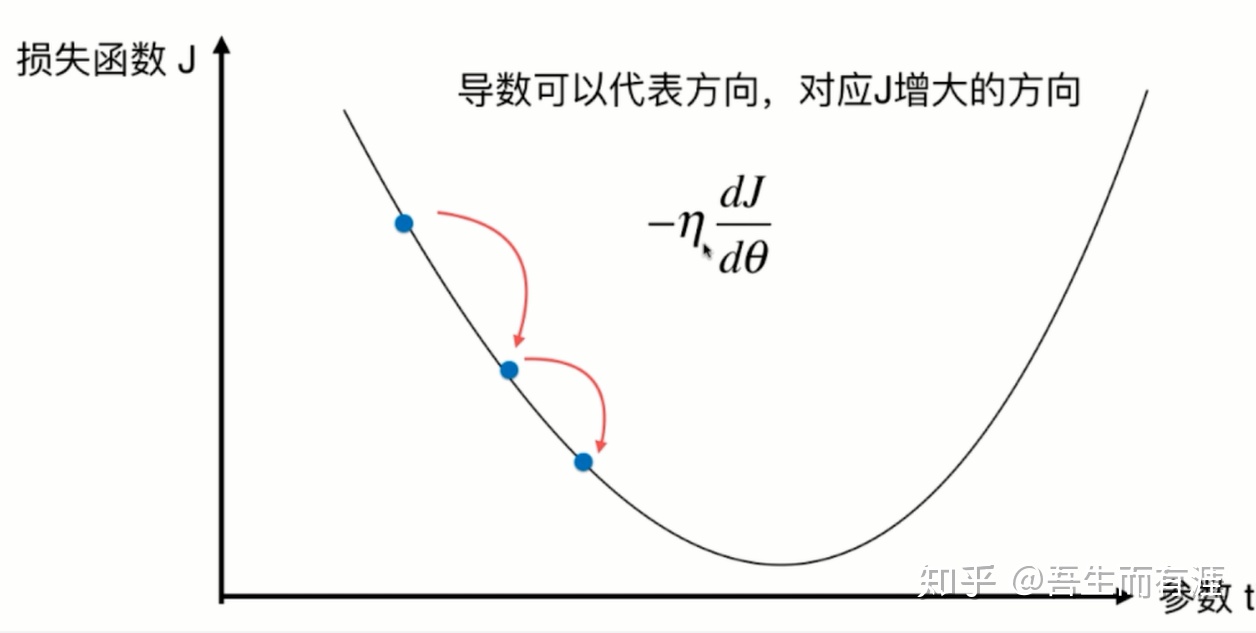
这个点的导数为负,如果每次加上这个导数会向左走,是梯度上升。要梯度下降,则加负号,前面乘以一个系数,控制每次移动的步长


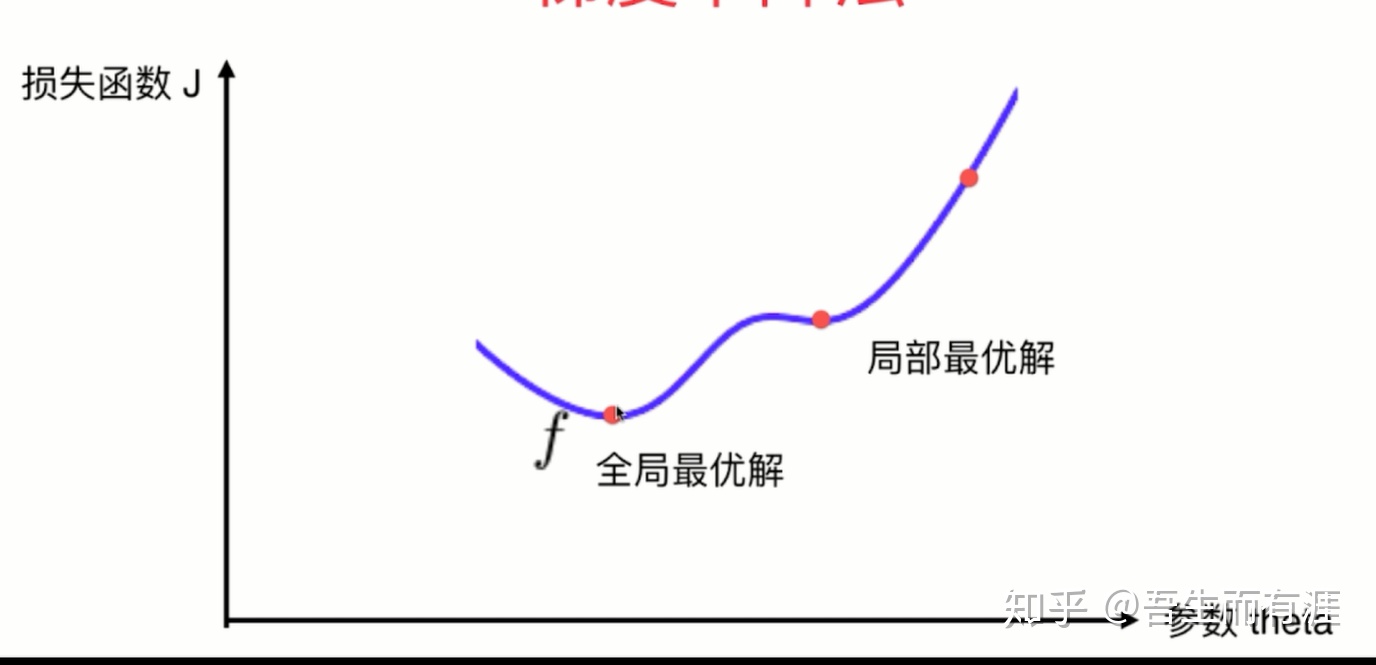
有可能找到的是:局部最优解


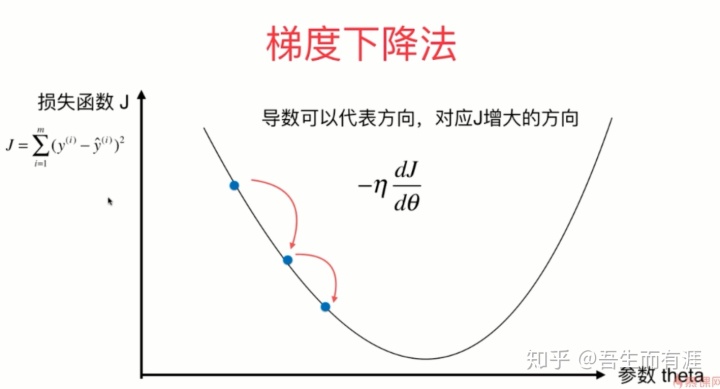
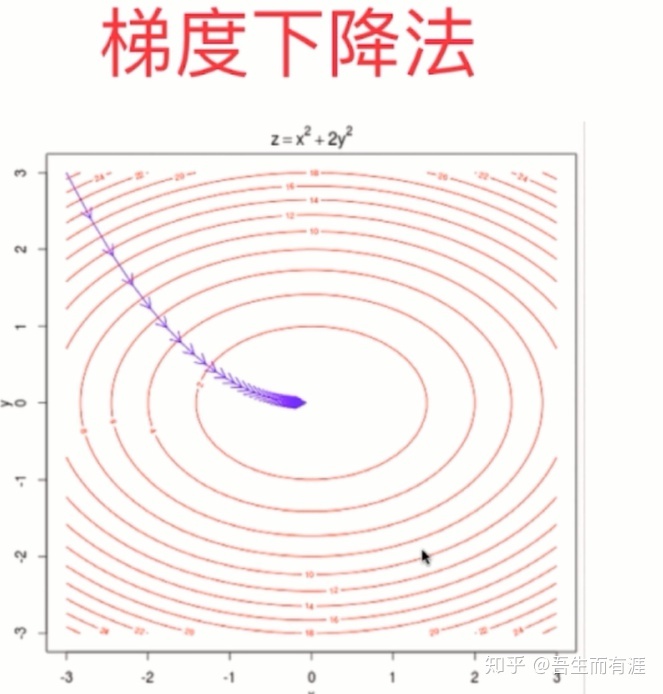
implementation:找到这个二次函数的最低点。(梯度下降法)
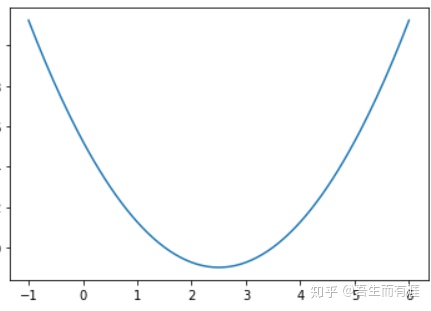
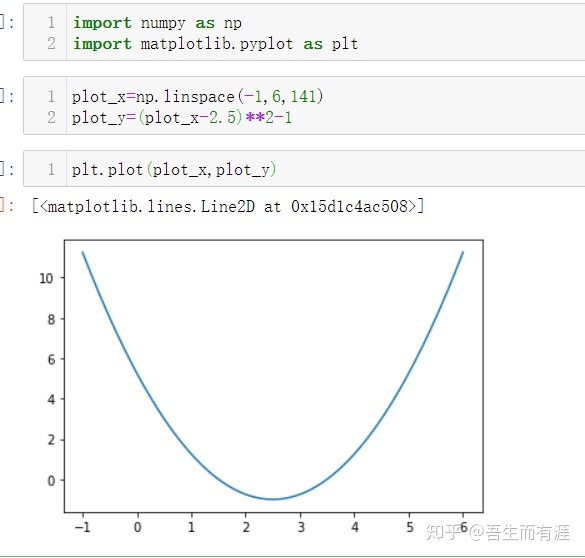
首先:loss function是啥?
很明显,就是这个二次函数,我们要让这个loss function 达到0,就说明我们找到了最小值点。
于是,每次求出迭代的点的导数值,乘以-1,表示梯度下降,然后乘以eta(学习率)
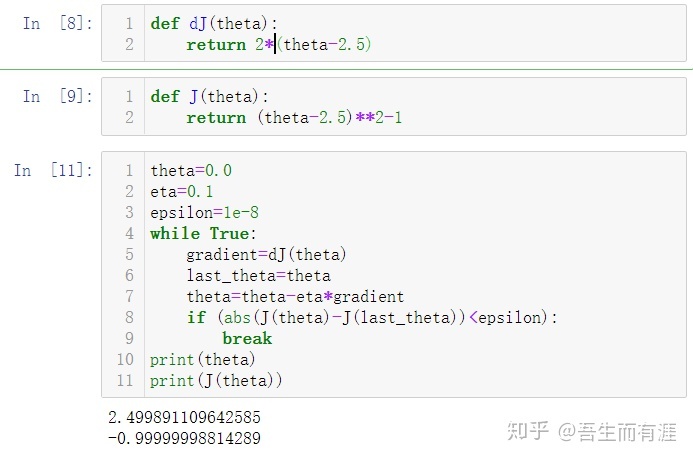
不妨来研究一下learning rate (eta)对梯度下降法的影响
eta=η()
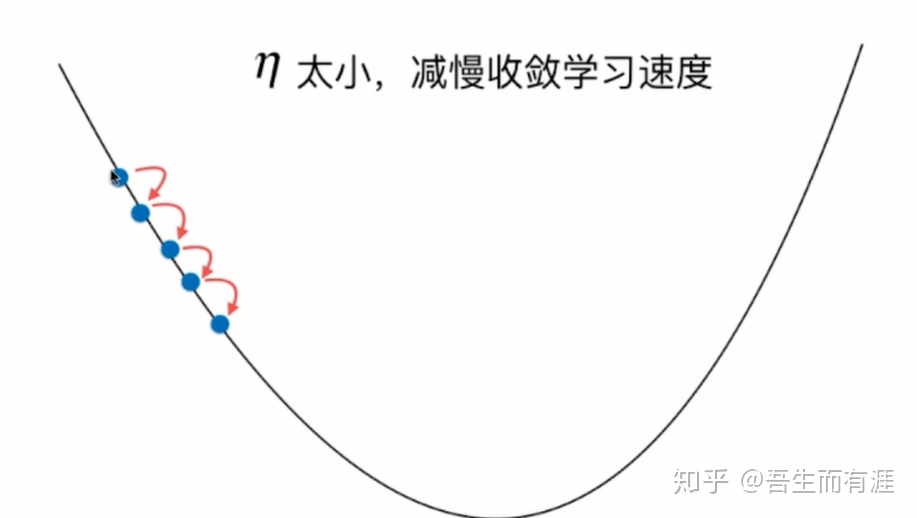
这是eta=0.1的时候
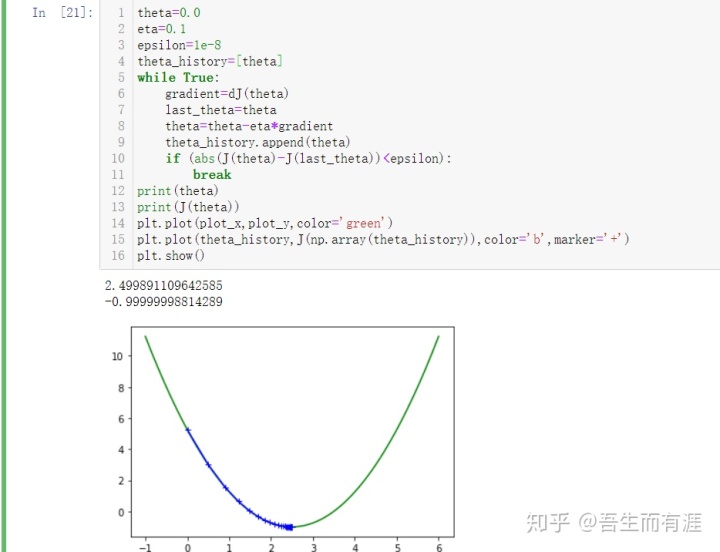
我盲猜eta=0.5,结果非常的amazing

直接给我找到了最低点,哈哈
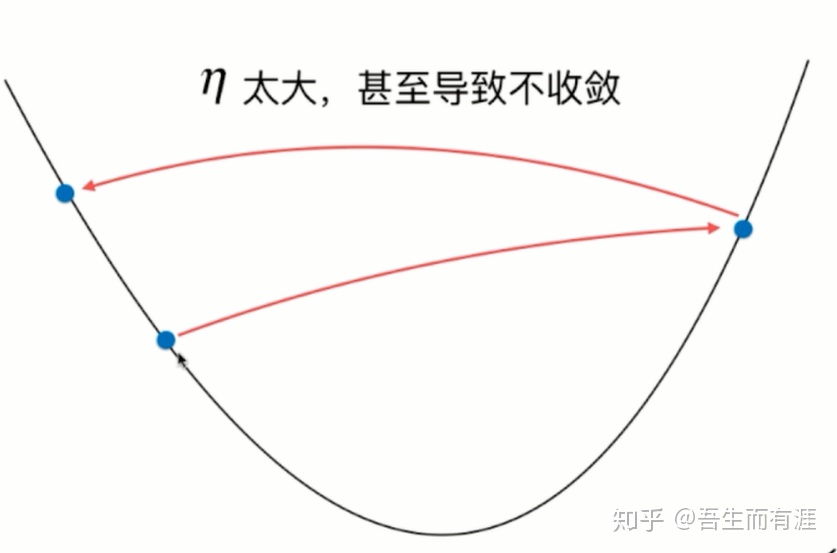
我猜想 eta>0.5的时候,很可能无法收敛。
结果任然amazing
经过左右横跳,最终还是收敛。
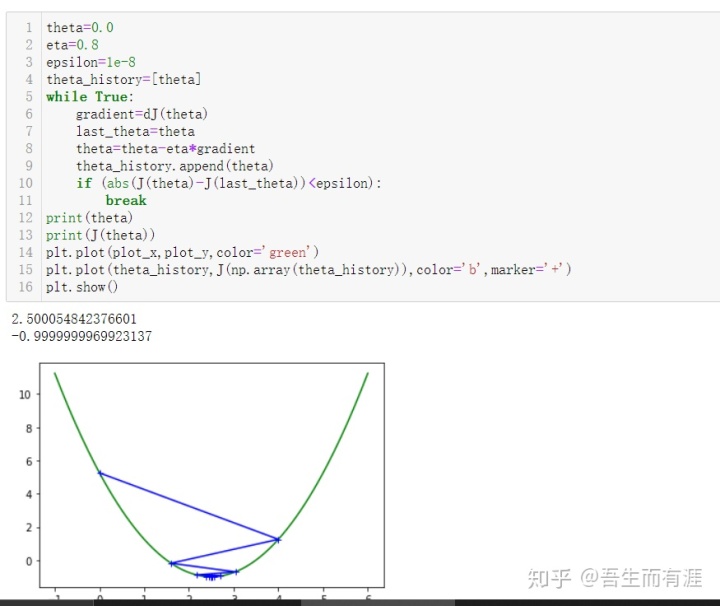
这时候eta=1.就无法收敛了。
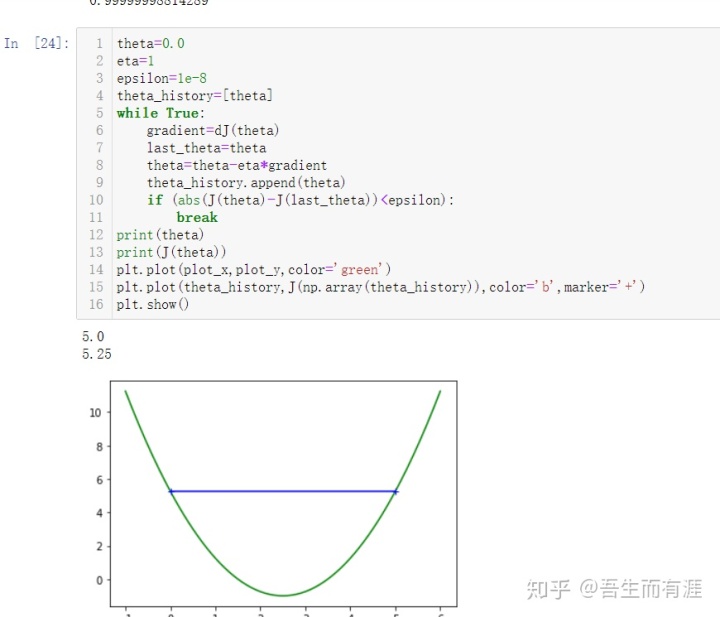
eta>1时,loss function 直接发散。
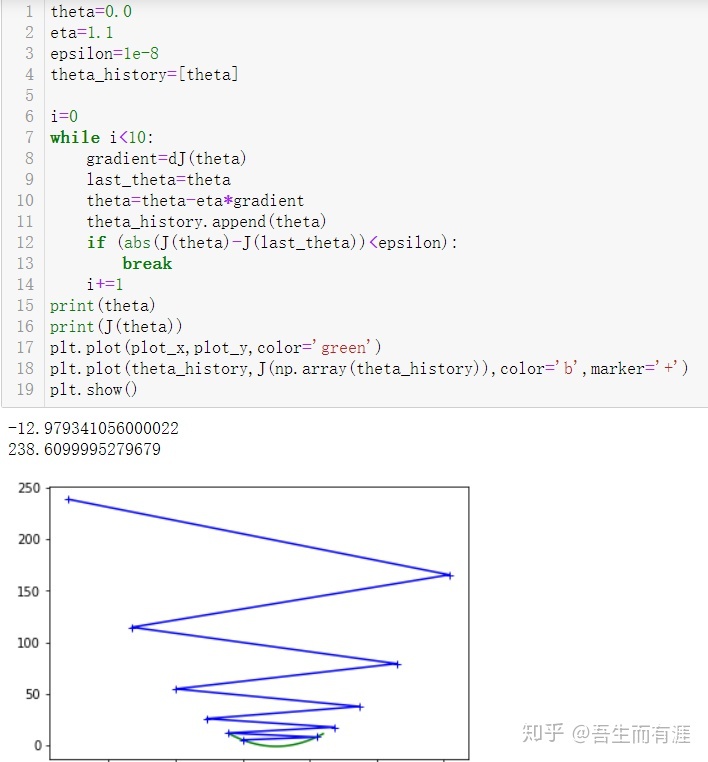
当eta很小时,迭代很多次才达到结果。

线性回归中的梯度下降法:
虽然线性回归中有解析解,但是这样的解计算很复杂,为了优化loss function,我们同样可以使用梯度下降法。
此时梯度是:
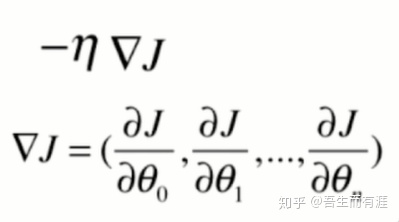

Loss function:
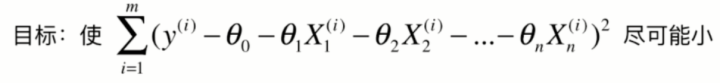
x是已经确定的,需要确定的就是θn
梯度是:
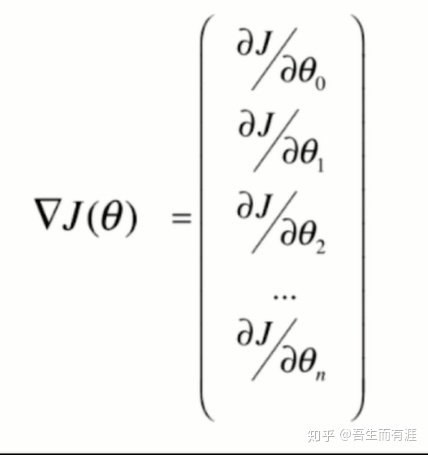

此时这个梯度每个分量都与m有关,这是一个很大的数字,我们不希望梯度与m有关,
这会导致运算量很大,
因此,不妨除以一个m:
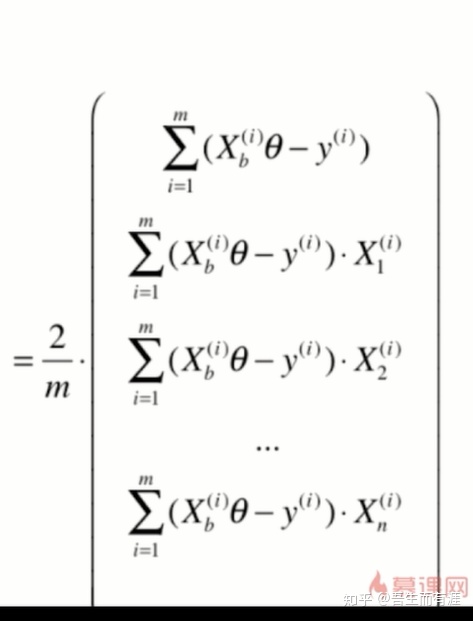
这样,我们会发现,我们优化的loss function 是:
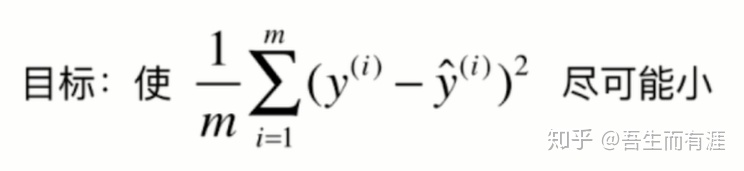

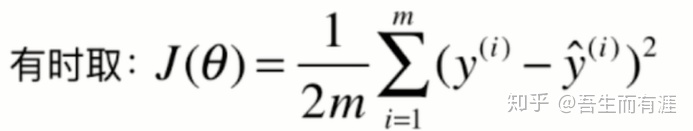
差别就是是否除以2,并无影响。
下面来编程实现一下线性回归中的梯度下降法吧~
随机生成一些数据:

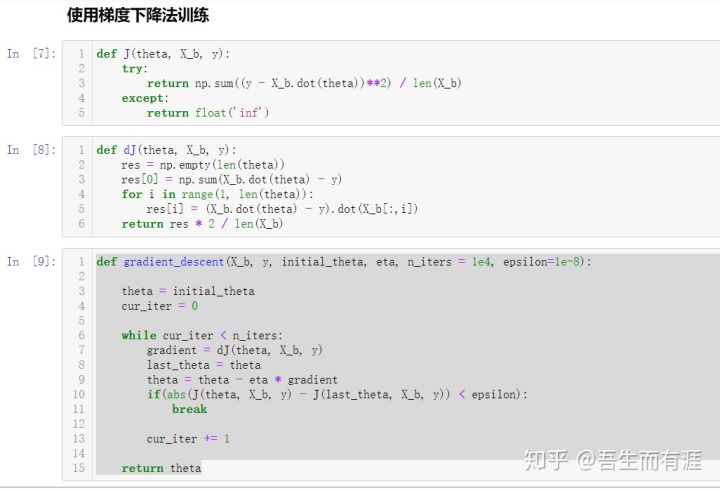
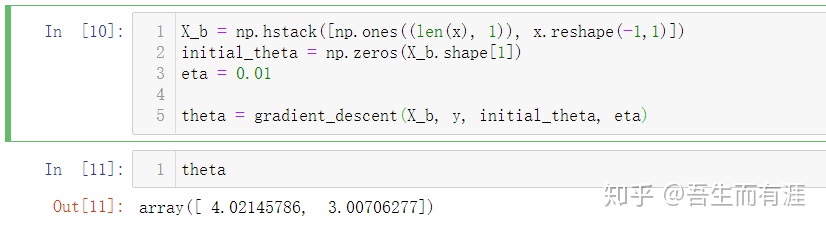
05-Vectorize-Gradient-Descent

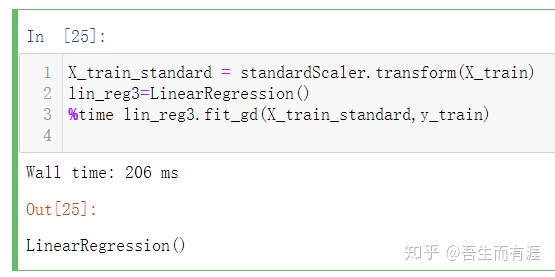
使用梯度下降法前进行数据归一化
当我们使用梯度下降法的时候,不同特征的单位不同,因此得到的梯度下降的方向也会受到一些数据偏大或者偏小的数字的影响,导致数据溢出,或者无法收敛到极小值。
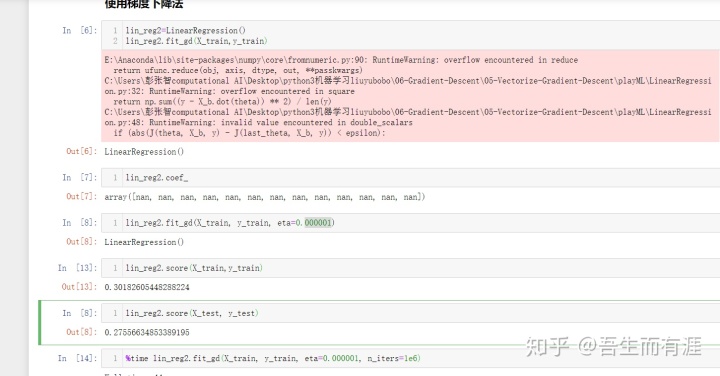
此时,最好将数据归一化,这样得到的梯度就很均匀,能够更快的梯度下降。
注意:当我们用正规方程求解时,不需要归一化!
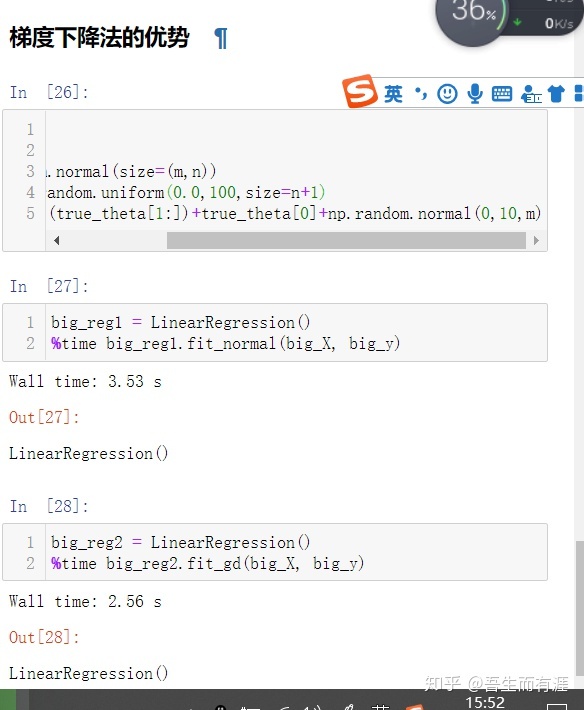
梯度下降法的优势:
随机梯度下降:
如何理解随机梯度下降(stochastic gradient descent,SGD)?www.zhihu.com这真的是一个很大的问题,我很难从我浅显的视角给出一个很准确的答案,
我的理解是:
我们选取的损失函数是各个样本损失的和再求平均,这样的方法显然很好
代表了总体性质,类似平均数。
但是这样的计算复杂度是:O(N)
随机梯度下降的思想就是随机选取一个样本,用他来代替整体的下降趋势。
那么计算开销就从

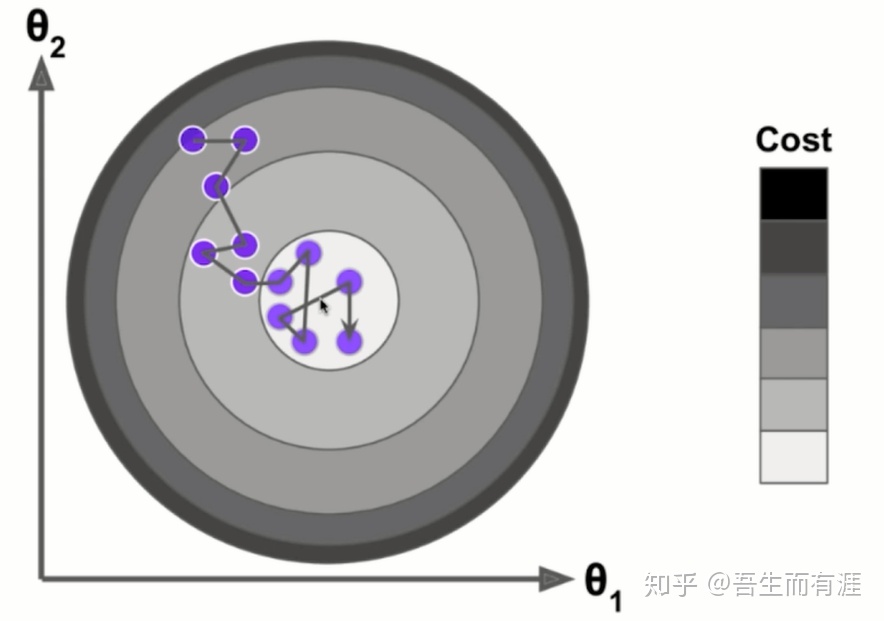
以上是搜索的过程,也许搜索的方向不是最佳的,甚至方向错误,
但是,根据实验数据显示,这样的方式能够优化到最终结果。
SGD对学习率要求很高。
因为优化的过程十分随机,如果我们的学习率一成不变,意味着可能我们到了
最佳位置但是又跳出去了。
因此,我们需要学习率随着迭代次数而逐步减少
则有:
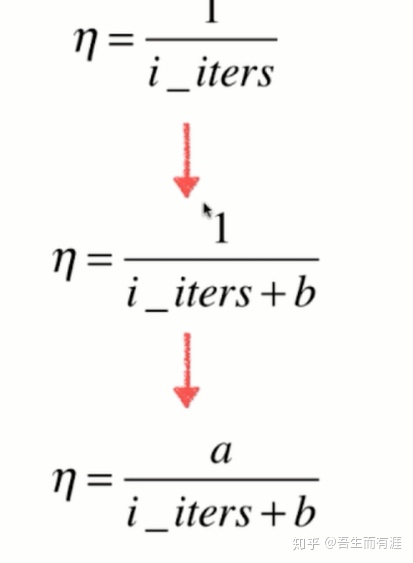

打造钢铁的时候,火的温度随着时间而减小。
下面编程实现:

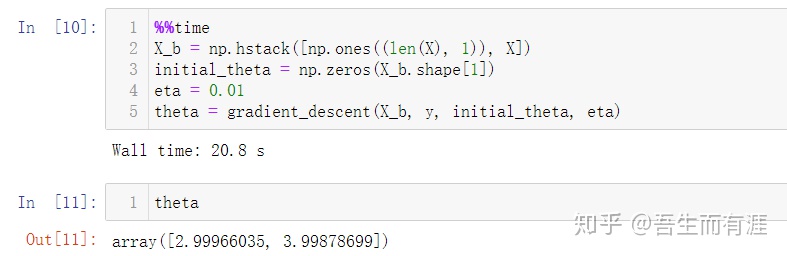
而梯度下降法耗时:
SCI-kit-LEARN 中的SGD:
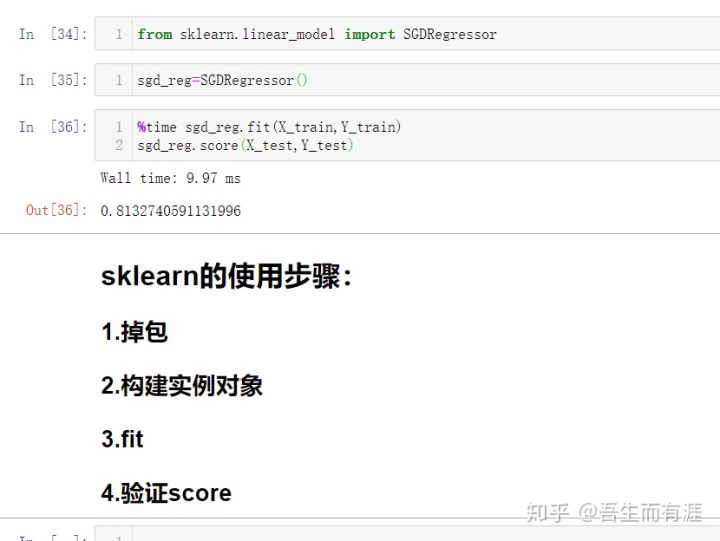
关于梯度的调试:
我们求出的梯度公式真正是对的吗?
如何验证?
其实很简单,我们的求法是依据多元函数求导公式
但是,我们忽略了导数的定义。
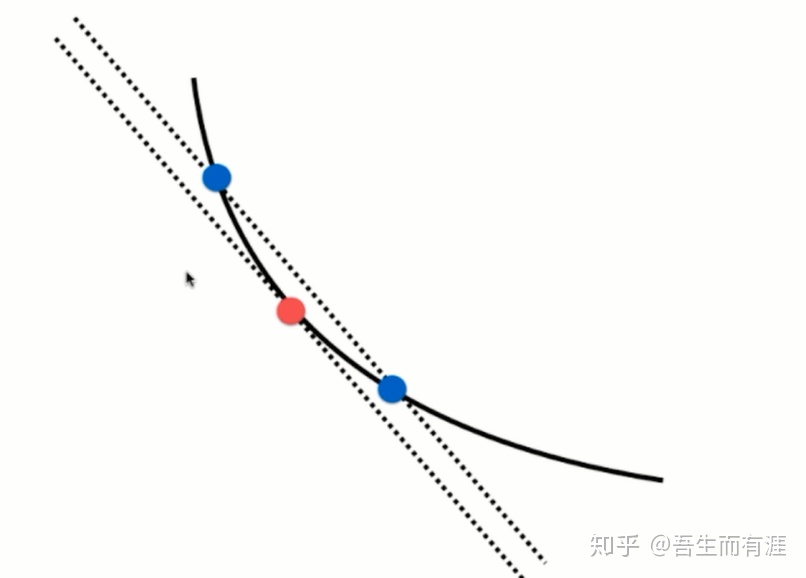
求个极限,割线斜率=切线斜率
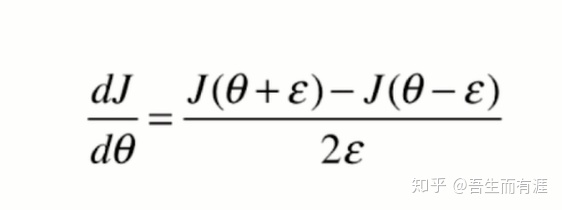
因此,对于梯度来说,就有

def dJ_debug(theta, X_b, y, epsilon=0.01):
res = np.empty(len(theta))
for i in range(len(theta)):
theta_1 = theta.copy()
theta_1[i] += epsilon
theta_2 = theta.copy()
theta_2[i] -= epsilon
res[i] = (J(theta_1, X_b, y) - J(theta_2, X_b, y)) / (2 * epsilon)
return res总结:

随机:
提高运算速度。
对于large_scale data 很重要。
能跳出局部最优解
对于很多不确定的问题,本身就没有一个确定的答案。
梯度上升法:
我们知道导数,或者梯度是代表函数值上升的方向
因此我们梯度下降的时候要减去。

梯度下降法不是一个机器学习算法
是一个基于搜索的最优化算法
能够最小化一个loss function maximize utility function~














 626
626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









