







目录
一.向量化


在playML包的LinearRegression.py函数中的class LinearRegression类中添加fit_gd()函数
def fit_gd(self, X_train, y_train, eta=0.01, n_iters=1e4):
"""根据训练数据集X_train, y_train, 使用梯度下降法训练Linear Regression模型"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must be equal to the size of y_train"
def J(theta, X_b, y):
try:
return np.sum((y - X_b.dot(theta)) ** 2) / len(y)
except:
return float('inf')
#向量化处理得到的梯度计算公式
def dJ(theta, X_b, y):
return X_b.T.dot(X_b.dot(theta) - y) * 2. / len(y)
def gradient_descent(X_b, y, initial_theta, eta, n_iters=1e4, epsilon=1e-8):
theta = initial_theta
cur_iter = 0
while cur_iter < n_iters:
gradient = dJ(theta, X_b, y)
last_theta = theta
theta = theta - eta * gradient
if (abs(J(theta, X_b, y) - J(last_theta, X_b, y)) < epsilon):
break
cur_iter += 1
return theta二.数据归一化
- 数据规模不一样,使用梯度下降法之前,最好进行数据归一化。
- 使用默认η,可能使搜索距离过大;修改有可能过小。
加载波士顿房价数据

使用梯度下降法前进行数据归一化

三.随机梯度下降法
1.概念
批量梯度下降:之前每一次计算就要将样本所有数据批量计算。如果m非常大,计算梯度本身也非常耗时。
随机梯度下降:在每次更新时用1个样本,我们用样本中的一个例子来近似我所有的样本,虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近。但是相比于批量梯度,这样的方法更快,更快收敛,虽然不是全局最优,但很多时候是我们可以接受的,所以这个方法用的也比上面的多。

学习率取值很重要。希望学习率是逐渐递减的。经验a取5,b取50

2.随机梯度下降法

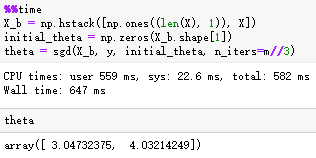
3.scikit-learn中的SGD
加载波士顿房价数据
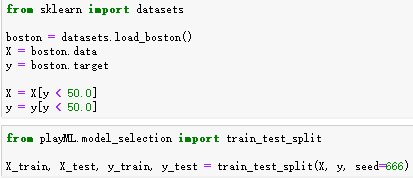
随机梯度处理线性规划

四.梯度调试
如果导数公式不好求。或者先用调试找适当参数,再使用公式求解验证。
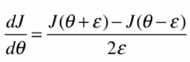
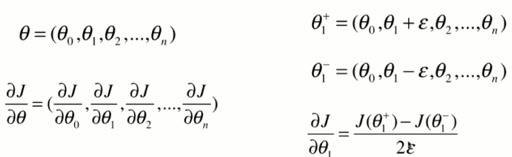
def dJ_debug(theta, X_b, y, epsilon=0.01):
res = np.empty(len(theta))
for i in range(len(theta)):
theta_1 = theta.copy()
theta_1[i] += epsilon
theta_2 = theta.copy()
theta_2[i] -= epsilon
res[i] = (J(theta_1, X_b, y) - J(theta_2, X_b, y)) / (2 * epsilon)
return res















 3162
3162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









