





整理不易,手有余香请点赞!
Bag of Tricks for Image Classification with Convolutional Neural Networks
Abstract
Much of the recent progress made in image classification research can be credited to training procedure refinements, such as changes in data augmentations and optimization methods. In the literature, however, most refinements are either briefly mentioned as implementation details or only visible in source code. In this paper, we will examine a collection of such refinements and empirically evaluate their impact on the final model accuracy through ablation study. We will show that, by combining these refinements together, we are able to improve various CNN models significantly. For example, we raise ResNet-50’s top-1 validation accuracy from % to % on ImageNet. We will also demonstrate that improvement on image classification accuracy leads to better transfer learning performance in other application domains such as object detection and semantic segmentation.
图像分类研究的最新进展可以归功于训练程序的改进,例如数据增强和优化方法的改变。 但是,在文献中,大多数改进只是作为实现细节而简要提及,或者仅在源代码中可见。 在本文中,我们将研究这些改进的集合,并通过消融研究从经验上评估它们对最终模型准确性的影响。 我们将证明,通过将这些改进组合在一起,我们可以显着改善各种CNN模型。 例如,在ImageNet上,我们将ResNet-50的top-1验证准确性从%提高到%。 我们还将证明,图像分类准确度的提高可在其他应用领域(例如目标检测和语义分割)中带来更好的迁移学习性能。
论文从加快模型训练,网络结构优化以及训练参数调优三个部分,分别介绍如何提升模型的效果。
1. 模型训练加速
使用更大的batch size;使用低精度(FP16,混合精度)进行训练。
2. 网络结构调优
Resnet-50优化
:图像分类训练技巧包(二)
可变形卷积
如何评价 MSRA 最新的 Deformable Convolutional Networks?
SE模块
小小将:最后一届ImageNet冠军模型:SENet
3. 模型训练调参
学习率策略采用cosine
Lable smoothing
new_labels = (1.0 - label_smoothing) * one_hot_labels + label_smoothing / num_classes总结就一句话,one-hot编码会自驱的向正类和负类的差值扩大的方向学习(过度的信任标签为1的为正类),在训练数据不足的情况容易过拟合,所以使用Label Smooth来软化一下,使得没那么容易过拟合。
知识蒸馏(knowledge distillation)
知识蒸馏时模型压缩领域的一个重要分支,即采用一个效果更好的teacher model训练student model,使得student model在模型结构不改变的情况下提升效果。
注意,p代表真实概率,z和r表示studnet model和techer model的最后一个全连接层的输出,T是超参数,用来平滑softmax函数的输出。
Mixup
如果使用了Mixup数据增强来进行训练,那么每次需要读取2张输入图像,这里用(xi, yi),(xj, yj)来表示,那么通过下面的公式就可以合成获得一张新的图像和标签(x_hat, y_hat),然后使用这张新图像和新标签进行训练,需要注意的是采用这种方式训练模型时要训更多epoch。式子中的
 是一个超参数,用来调节合成的比重,取值范围是[0, 1]。
是一个超参数,用来调节合成的比重,取值范围是[0, 1]。
4. 其他
调整Loss函数
- Bbox loss (IOU,GIOU,DIOU,CIOU)
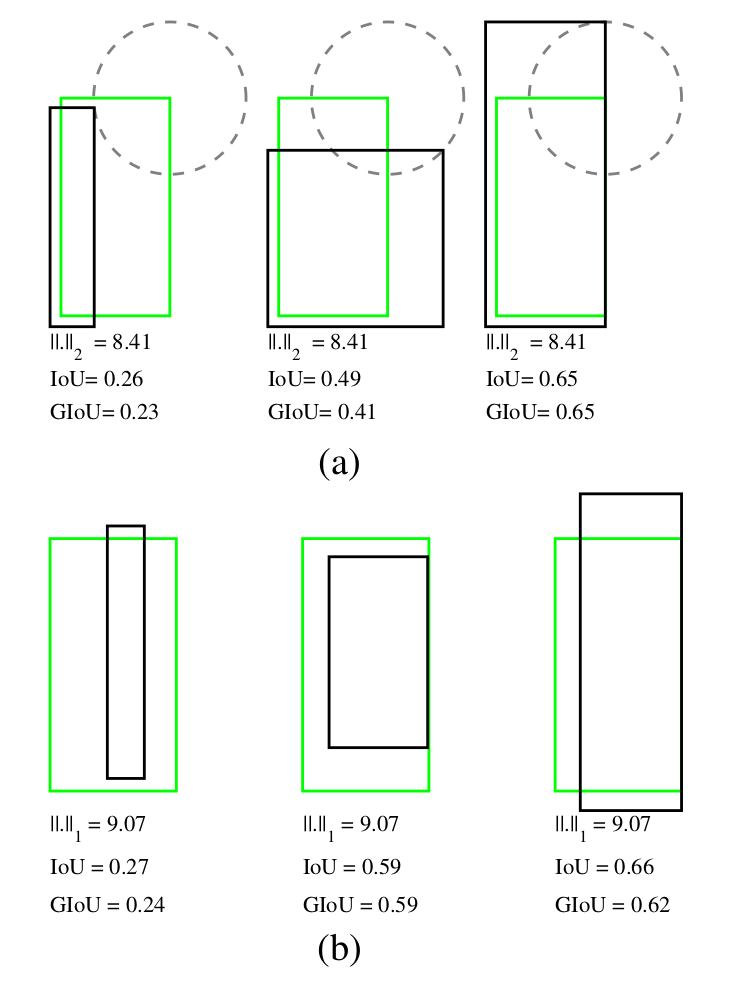

- Confidence loss(YOLOv4,YOLOv5,PP-YOLO)
- IOU_Aware_Loss(PP-YOLO)
- Focal loss

Exponential Moving Average
梯度裁剪















 1119
1119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









