





量仔导读
最近,咱们M星程序员小哥熊怀东,在使用Facebook推出的开源项目PyTorch 1.7的过程中,“顺手”修复了一个bug,还被PyTorch官方收录。小熊同学特意为大家准备了一份手记,详细记录了团队是如何解决bug的,在此分享给大家。
固定布局 工具条上设置固定宽高
背景可以设置被包含
可以完美对齐背景图和文字
以及制作自己的模板

背景
PS on PySpark 是 Mobvista 机器学习团队为 MindAlpha 2.0 机器学习平台新开发的 Parameter Server 实现,它将 Spark 和 PyTorch 这两个大数据和机器学习领域最流行、最易用的框架结合起来,为深度学习算法从特征工程、离线训练到在线预测提供一站式服务,支持集团的大规模深度学习算法应用。 之前,我们使用 PyTorch 1.6 开发算法,最近算法同学开发了一种新的 Batch Normalization Op,经测该 Op 可显著提高模型的 AUC。由于该新 Op 需要使用尚未正式发布的 PyTorch 1.7 中的 torch.no_grad 这一功能 (https://github.com/pytorch/pytorch/issues/40259),因此我们使用PyTorch 1.7 的 nightly build 进行测试,这样当 PyTorch 1.7 于 10 月下旬正式发布时,我们的模型正式上线时间正好对上。 使用 PyTorch 1.7 的 nightly build,修复一些不兼容的代码后,离线训练和预测均可正常进行,但将模型部署到在线预测服务后,在一个 minibatch 的 forward 执行完成后,libtorch 总是报 Expected Tensor but got None 的断言失败。
调试过程
1. 在线调试,排除人为误操作因素
我们首先尝试了修改 .py 文件,在 Model.forward() 方法中的每条语句后面添加 print(),然后重新导出 .ptm 进行线上预测,但是由于 print() 的输出到 stdout 与日志是分离的,日志中看不到输出,所以这种方法行不通。 于是我们改为用 unzip 解开 .ptm 文件,修改 TorchScript 源代码,然后重新打包进行预测的方法。
unzip export.ptm
vim archive/code/__torch__/nn_rank.py
zip -r export.ptm archive
通过修改 .ptm 里的 nn_rank.py 中 TorchScript 表示的 forward 方法,在恰当的位置插入 ops.prim.RaiseException,我们可以验证 forward 方法能成功执行的部分,并在异常消息中看到 Tensor 在对应位置处的值。
于是我们改为用 unzip 解开 .ptm 文件,修改 TorchScript 源代码,然后重新打包进行预测的方法。
unzip export.ptm
vim archive/code/__torch__/nn_rank.py
zip -r export.ptm archive
通过修改 .ptm 里的 nn_rank.py 中 TorchScript 表示的 forward 方法,在恰当的位置插入 ops.prim.RaiseException,我们可以验证 forward 方法能成功执行的部分,并在异常消息中看到 Tensor 在对应位置处的值。
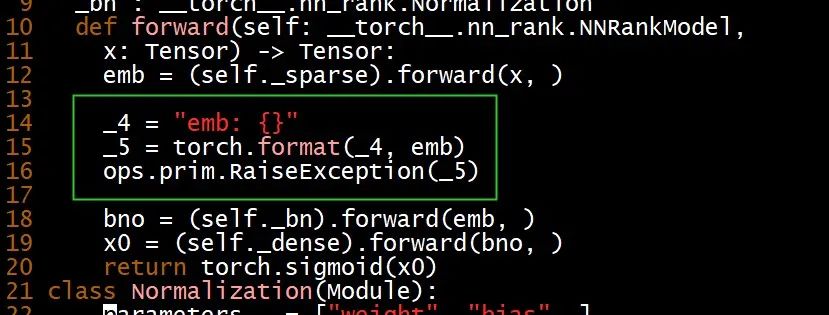 但奇怪的是整个 forward 直到 return torch.sigmoid(x0) 之前都可以成功执行,而从 TorchScript 返回到 C++ 后仍断言失败,报 ExpectedTensor but got None。
退回至 PyTorch 1.6 改用不使用torch.no_grad 的算法测试,不会遇到断言失败。根据
https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/core/ivalue.h#L92 处 TORCH_FORALL_TAGS() 的定义,None 和 Tensor 的枚举值只相差了 1,怀疑不同版本 libtorch 存在源码不兼容,我们使用 PyTorch 1.7 的 libtorch 重新编译各模块,问题依旧,排除此猜测。
但奇怪的是整个 forward 直到 return torch.sigmoid(x0) 之前都可以成功执行,而从 TorchScript 返回到 C++ 后仍断言失败,报 ExpectedTensor but got None。
退回至 PyTorch 1.6 改用不使用torch.no_grad 的算法测试,不会遇到断言失败。根据
https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/core/ivalue.h#L92 处 TORCH_FORALL_TAGS() 的定义,None 和 Tensor 的枚举值只相差了 1,怀疑不同版本 libtorch 存在源码不兼容,我们使用 PyTorch 1.7 的 libtorch 重新编译各模块,问题依旧,排除此猜测。

2. GDB 调试,确定排查范围
为了使调试更容易,编写 nps_offline_check.cpp 用 OnlineSparseModel 加载 .ptm 直接调用 TorchScript 里面的 forward 方法,可以重现 Expected Tensor but got None 的断言失败,这使得用 GDB 调试成为可能。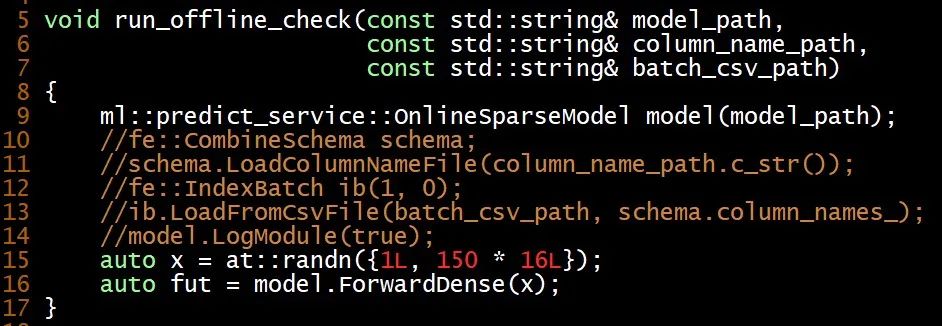 结合使用 GDB 的 stepi 和 finish 命令单步执行机器指令,确认执行至
https://github.com/pytorch/pytorch/blob/master/torch/csrc/jit/api/function_impl.cpp#L51处即 forward 返回时仍不会发生断言失败。
结合使用 GDB 的 stepi 和 finish 命令单步执行机器指令,确认执行至
https://github.com/pytorch/pytorch/blob/master/torch/csrc/jit/api/function_impl.cpp#L51处即 forward 返回时仍不会发生断言失败。
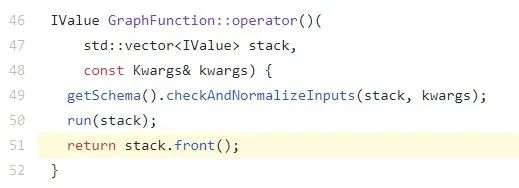 推断是 run(stack) 里面的逻辑有问题,run 最终会调用至
https://github.com/pytorch/pytorch/blob/master/torch/csrc/jit/runtime/interpreter.cpp#L1161 处的
InterpreterStateImpl::runImpl() 方法,该方法主要由一个大的 switch 语句组成。
推断是 run(stack) 里面的逻辑有问题,run 最终会调用至
https://github.com/pytorch/pytorch/blob/master/torch/csrc/jit/runtime/interpreter.cpp#L1161 处的
InterpreterStateImpl::runImpl() 方法,该方法主要由一个大的 switch 语句组成。
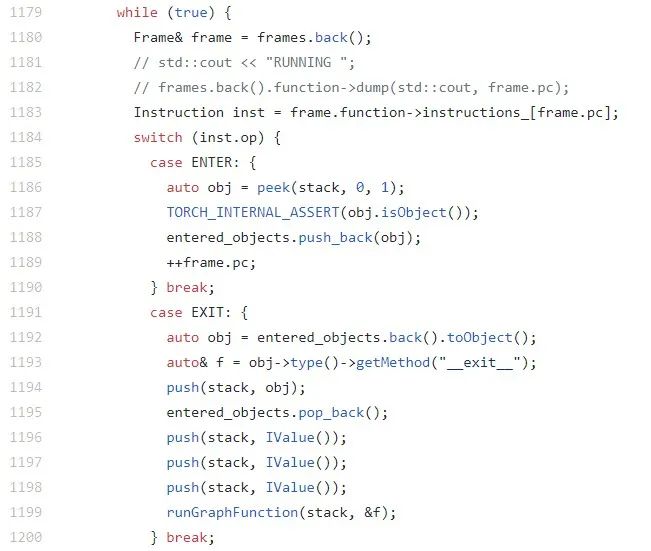 可以看出该函数所起的作用正是 CPython 解释器中实现字节码解释的功能。参见 CPython 中_PyEval_EvalFrameDefault 的实现,
可以看出该函数所起的作用正是 CPython 解释器中实现字节码解释的功能。参见 CPython 中_PyEval_EvalFrameDefault 的实现,https://github.com/python/cpython/blob/master/Python/ceval.c#L1477。
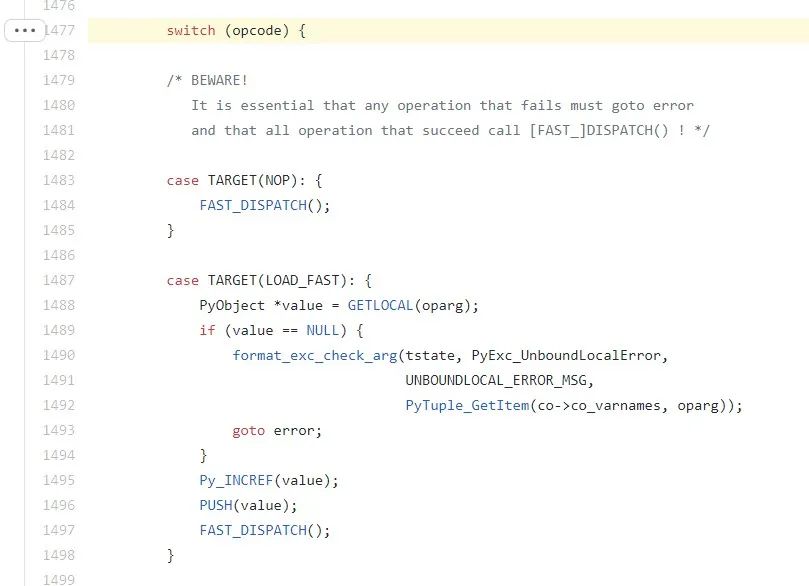 两者都是由一个大的 switch 语句组成。PyTorch 之所以自己实现一个 TorchScript 的解释器,主要有两方面的考虑,一是这样避免了 CPython 中 GIL(Global Interpreter Lock)引起的多线程上下文切换的开销,从而可以更高效地进行多线程并行预测,二是自定义一种IR 可以做常量传播、窥孔优化等常规编译优化和 operator fusion 之类针对深度学习的专用优化,用 CPython 解释器这些优化无法进行。
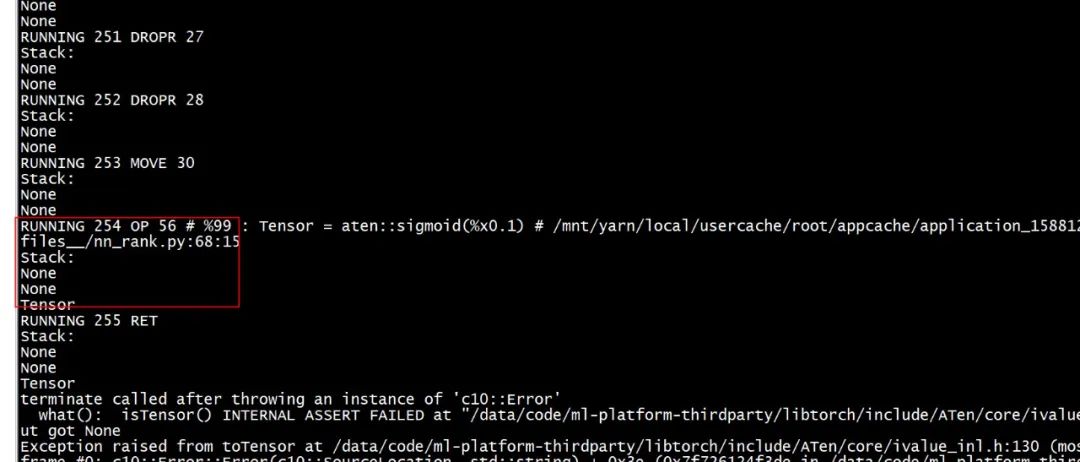
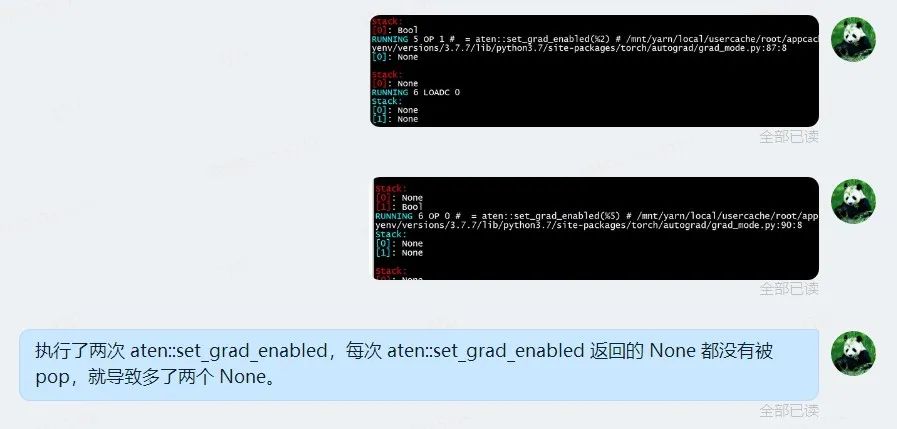
通过在 InterpreterStateImpl::runImpl() 中执行每条指令前打印求值栈中每个值的 tag,得到下图。该图表明栈顶有一个 Tensor,但是其下多出了两个 None 值,由于 GraphFunction::operator() 的最后一条语句为 returnstack.front();,这样 toTensor 方法就会尝试从 None 中取出一个 Tensor,导致 Expected Tensor but got None 的断言失败。
两者都是由一个大的 switch 语句组成。PyTorch 之所以自己实现一个 TorchScript 的解释器,主要有两方面的考虑,一是这样避免了 CPython 中 GIL(Global Interpreter Lock)引起的多线程上下文切换的开销,从而可以更高效地进行多线程并行预测,二是自定义一种IR 可以做常量传播、窥孔优化等常规编译优化和 operator fusion 之类针对深度学习的专用优化,用 CPython 解释器这些优化无法进行。
通过在 InterpreterStateImpl::runImpl() 中执行每条指令前打印求值栈中每个值的 tag,得到下图。该图表明栈顶有一个 Tensor,但是其下多出了两个 None 值,由于 GraphFunction::operator() 的最后一条语句为 returnstack.front();,这样 toTensor 方法就会尝试从 None 中取出一个 Tensor,导致 Expected Tensor but got None 的断言失败。
3. 排除多种猜测,最终定位 bug 根源
我们提出了多种猜测,包括: 1. EXIT 指令未 pop 正确个数的 None。 2. with 语句的实现调用 __exit__ 之类返回 None 的方法后没有 pop None 返回值。 3. 字节码编译器处理 __exit__ 时没有生成 DROP 指令弹出 None。 4. with ... as var: 编译方法中 else 分支未处理正确。 但通过分析 PyTorch 源代码及实际验证,这些猜测均被否定。 最后通过在执行每条 TorchScript IR 指令前后分别打印求值堆栈的内容,反复观察两个 None 是何时出现在栈中(并一直未被弹出),终于发现这发生在执行aten::set_grad_enabled() 之后,如下面的两张图所示。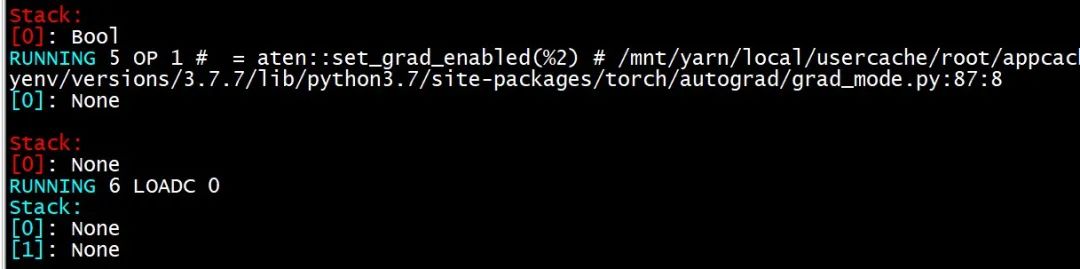
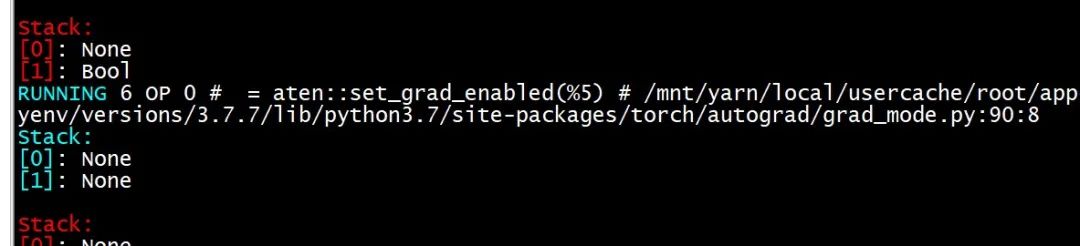
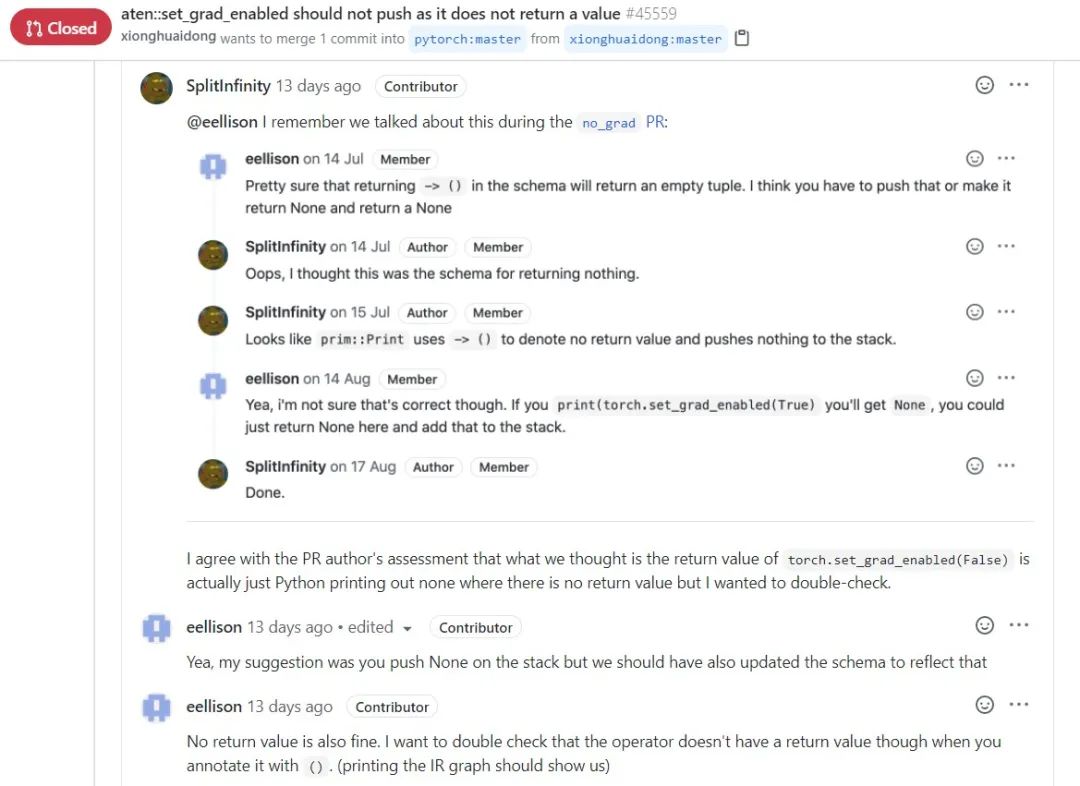
 在 PyTorch 源代码中搜索 set_grad_enabled,定位到
在 PyTorch 源代码中搜索 set_grad_enabled,定位到https://github.com/pytorch/pytorch/blob/v1.7.0-rc1/torch/csrc/jit/runtime/register_special_ops.cpp#L436,可以看到其中的 push(stack, IValue()); 处 push 了一个 None 到求值堆栈。
 看到 aten::set_grad_enabled(boolval) -> () 这个 operator 签名,我联想到了函数式编程语言如 Haskell 中的 () 类型,函数式语言使用 () 或 unit 表示函数无返回值。aten::set_grad_enabled 无返回值,因此它的签名中使用了 (),但是 436 行这里却push 了一个 None,推测原作者搞混了 CPython 和 TorchScript 的行为,None 在 Python 里有两种作用,既作为一个普通的值,也用于表示函数无返回值,当Python 函数不显式返回一个值时,CPython 解释器会 push 一个 None 到求值栈,但 TorchScript 使用自定义的解释器,结合分析,TorchScript 在函数无返回值时不应 push None。PyTorch 团队开发成员后来在 pull request
https://github.com/pytorch/pytorch/pull/45559 中的回复证明了这一点。
看到 aten::set_grad_enabled(boolval) -> () 这个 operator 签名,我联想到了函数式编程语言如 Haskell 中的 () 类型,函数式语言使用 () 或 unit 表示函数无返回值。aten::set_grad_enabled 无返回值,因此它的签名中使用了 (),但是 436 行这里却push 了一个 None,推测原作者搞混了 CPython 和 TorchScript 的行为,None 在 Python 里有两种作用,既作为一个普通的值,也用于表示函数无返回值,当Python 函数不显式返回一个值时,CPython 解释器会 push 一个 None 到求值栈,但 TorchScript 使用自定义的解释器,结合分析,TorchScript 在函数无返回值时不应 push None。PyTorch 团队开发成员后来在 pull request
https://github.com/pytorch/pytorch/pull/45559 中的回复证明了这一点。
 虽然前后调试了近三天,但修复还是比较容易的,只需要删除
虽然前后调试了近三天,但修复还是比较容易的,只需要删除https://github.com/pytorch/pytorch/blob/v1.7.0-rc1/torch/csrc/jit/runtime/register_special_ops.cpp#L436这一行代码。
后续
9月30日,我们给 PyTorch 官方提交了一个 issuehttps://github.com/pytorch/pytorch/issues/45558,并提交了相应的 pull request
https://github.com/pytorch/pytorch/pull/45559,该 pull request 于 10月12日合并到了 release/1.7 分支,这样当 PyTorch 1.7 正式发布时,我们的生产代码可以使用 torch.no_grad 而不会再遇到该断言失败。
技术进阶之旅
END
量仔一路同行















 704
704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









