







贪心问题
while的使用:
- while list,直到list为空
- i=0 while 内部循环i自增,对于list来说pop或者remove之后直接往前顶,所以每次操作的都是i。不删除才往上增加。
- 上述的就是变长度的list还要跟踪是否到底。
分发饼干 lc 455
对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j,都有一个尺寸 s[j] 。如果 s[j] >= g[i],我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。你的目标是尽可能满足越多数量的孩子,并输出这个最大数值。
输入: g = [1,2,3], s = [1,1]
输出: 1
解释:
你有三个孩子和两块小饼干,3个孩子的胃口值分别是:1,2,3。
虽然你有两块小饼干,由于他们的尺寸都是1,你只能让胃口值是1的孩子满足。
所以你应该输出1。
class Solution:
def findContentChildren(self, g: List[int], s: List[int]) -> int:
g.sort()
s.sort()
count = 0
i,j=0,0
while i < len(g) and j < len(s):
if g[i]<=s[j]:
count+=1
i+=1
#因为排序好了,每人只能得到一个,所以当前要是不满足后面也不会满足要跳过
j+=1
return count
# 解法2,和字符串之变化一个思路一致,两个变量都要满足,只需要移动一个保持另一个
class Solution(object):
def findContentChildren(self, g, s):
"""
:type g: List[int]
:type s: List[int]
:rtype: int
"""
g.sort()
s.sort()
length_g = len(g)
start = 0
count = 0
for i in range(len(s)):
if start<length_g and s[i]>=g[start] :
count+=1
start+=1
return count
- 贪心法典型问题,排好序,当前不满足直接往后调
- 两个数组都要往下滚动,一般是有一个必须要往下滚动,另一个满足条件才往下滚动,所以一个for另一个是计数方式。
无重叠区间 lc 435
给定一个区间的集合,找到需要移除区间的最小数量,使剩余区间互不重叠。
输入: [ [1,2], [2,3], [3,4], [1,3] ]
输出: 1
解释: 移除 [1,3] 后,剩下的区间没有重叠。
class Solution:
def eraseOverlapIntervals(self, intervals):
intervals = sorted(intervals,key=lambda x:x[-1])
count = 0
i = 1
while 1<=i<len(intervals):
if intervals[i-1][-1] > intervals[i][0]:
count+=1
#注意remove的用法,就是直接删除了,如果是for就不行了
intervals.remove(intervals[i])
else:
i+=1
return count
- 挺有现实意义的,思路是如果有重叠是前一个的第二位大于后一个的第一位。
- 按照第二位排序好之后直接去删除后面的那个位置的内容即可,因为排好序了。
- 注意这是while,remove之后是删除该内容,但是序号没跟着变。
- remove产出指定的内容,删除之后后面的元素自动往前移动,for的特性是每次迭代自动往后挪,所以如果使用for的话用remove删除应该从后往前删除。否则用while,因为自增和遍历是分离的,如本题目所示。
合并重叠区域 lc 56

class Solution:
def merge(self, intervals: List[List[int]]) -> List[List[int]]:
intervals.sort(key=lambda x:x[0])
i = 0
while i!=len(intervals)-1:
if intervals[i][1]>=intervals[i+1][0]:
tmp = [intervals[i][0],max(intervals[i][1],intervals[i+1][1])]
intervals.pop(i)
intervals.pop(i)
intervals.insert(i,tmp)
else:
i+=1
return intervals
l = [[1,3],[4,5],[10,15],[2,6]]
# l = [[1,3],[2,6]]
print(merge(l))
- 这个问题是对list的pop和insert的了解。
- pop和remove一样,出去了下标都会往前挪。
求两个电话同时说话的时间
在数据存储时,我们将时间轴上的区间数据存储为列表格式,列表中的每个元素代表对应时间轴的一段时间区间,如:(1,1.5)代表从第1秒开始到第1.5秒结束。现有两个时间轴A、B及其各自包含的时间区间信息,求两个时间轴上时间区间的交集部分:
A = [(1,1.5), (3,8)]
B = [(2,4), (5,6), (7,9)]
O = overlap(A,B)
O = [(3,4), (5,6), (7,8)]
def inner(l1,l2):
lst = [l1,l2]
lst.sort(key=lambda x:x[0])
if lst[0][1]>lst[1][0]:
inner = (max(lst[0][0],lst[1][0]),min(lst[0][1],lst[1][1]))
return inner
def overlap(A,B):
res = []
for i in A:
for j in B:
res.append(inner(i,j))
return [i for i in res if i!=None]
#优化一下,当前如果没有交集,则后面都没有交集。
def overlap(A,B):
res = []
flag = 0
for i in A:
for j in B:
if inner(i,j) is None:
flag = 1
break
res.append(inner(i,j))
if flag:
flag = 0
continue
return res
- 注意不能直接合并,因为合并,因为可能后面还会有过长,不是贪心问题,只有求交集才是。
投飞镖刺破气球 lc 452

class Solution:
def findMinArrowShots(self, points: List[List[int]]) -> int:
if not points:
return 0
points.sort(key=lambda x:x[1])
res = 1
curr_pos = points[0][1]
for i in range(len(points)):
if curr_pos>=points[i][0]:
continue
curr_pos = points[i][1]
res+=1
return res
- 有重叠的问题就很容易想到贪心,就逐步的去戳。
- 用的箭最少需要从边上开始,因为从中间开始就去掉更多的链接了,想象成一个图。
- 因为已经按照右边排好序,所以每次只看左边有没有超过上一次的右边就可以了,不用管箭的位置,如果不是的话再+1并且移动新的框。
根据身高重建队列 lc 406
假设有打乱顺序的一群人站成一个队列,数组 people 表示队列中一些人的属性(不一定按顺序)。每个 people[i] = [hi, ki] 表示第 i 个人的身高为 hi ,前面 正好 有 ki 个身高大于或等于 hi 的人。
请你重新构造并返回输入数组 people 所表示的队列。返回的队列应该格式化为数组 queue ,其中 queue[j] = [hj, kj] 是队列中第 j 个人的属性(queue[0] 是排在队列前面的人)

class Solution:
def reconstructQueue(self, people: List[List[int]]) -> List[List[int]]:
people.sort(key = lambda x:(-x[0],x[1]))
res = []
for p in people:
#注意insert的用法,位置,值
res.insert(p[1],p)
return res
- 比较特殊的排序,先按照身高后按照前面有几个人拍好,身高是降序排列,前面的人是升序。
- 而后就可以按照前面有几个人依次插入,因为插入的身高都是对的。
判断是否为子序列 lc 392
示例 1:
输入:s = “abc”, t = “ahbgdc”
输出:true
示例 2:
输入:s = “axc”, t = “ahbgdc”
输出:false
class Solution:
def isSubsequence(self, s: str, t: str) -> bool:
if s == '':
return True
start = 0
for i in range(len(t)):
if s[start] == t[i]:
start+=1
if start == len(s):
return True
return False
- 一看就是常见的两个字符串的问题,一个使劲往下滑动,另一个找到了计数+1.
- 以长的为标准来。
买卖股票的最佳时机 lc 121
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
输入:[7,1,5,3,6,4]
输出:5
解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。
class Solution:
def maxProfit(self, prices: List[int]) -> int:
result, buy = 0, float('inf')
for price in prices:
buy = min(buy,price)
result = max(result,price-buy)
# if buy > price:
# buy = price
#
# if result < price - buy:
# result = price - buy
return result
- 只遍历一遍,选出当前的最小值,和未来的差值的最大值,上面和下面的注释是两种实现。
- 上面是一定先选出最小,后面是当前值减去当前的最小得到的值。关键就是未必更新,吸引我的地方是说,遍历一遍找到。
- 这个的前提条件是之前先买之后才能卖,所以可以这样遍历
买卖股票的最大收益 II lc 122
可以进行多次买卖,但是一个时间只能进行一次,即第一次买卖结束才能进行第二次。
输入: [7,1,5,3,6,4]
输出: 7
解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。
class Solution:
def maxProfit(self, prices: List[int]) -> int:
result = 0
#解决数组越界问题,循环处减1,具体循环下标+1。这个题目神奇的地方告诉我们,要是有先知先觉短线操作一定比长线好
for i in range(len(prices)-1):
if prices[i] < prices[i+1]:
result += prices[i+1] - prices[i]
return result
- 这就是建模啊,先知了为啥多次好,多次会把每次的赚钱机会平均化,多贪心那?
- 贪心到两两作比较,[a,b,c,d,e,f]单调上升,b-a+c-b+d-c+e-d+f-e=f-a,其他正好能把峰值都买到。
种花问题 lc 605
假设有一个很长的花坛,一部分地块种植了花,另一部分却没有。可是,花不能种植在相邻的地块上,它们会争夺水源,两者都会死去。
给你一个整数数组 flowerbed 表示花坛,由若干 0 和 1 组成,其中 0 表示没种植花,1 表示种植了花。另有一个数 n ,能否在不打破种植规则的情况下种入 n 朵花?能则返回 true ,不能则返回 false。
输入:flowerbed = [1,0,0,0,1], n = 1
输出:true
class Solution:
def canPlaceFlowers(self, flowerbed: List[int], n: int) -> bool:
res=0
flowerbed = [0] + flowerbed + [0]
for i in range(1,len(flowerbed)-1):
if flowerbed[i]==0 and flowerbed[i-1]==0 and flowerbed[i+1]==0:
flowerbed[i]=1
res +=1
if res>=n:
return True
else:
return False
- 连续三个好想,但是初始化那不好,看了报错,正好这样解就一致了
非递减数列 lc 665
给你一个长度为 n 的整数数组,请你判断在 最多 改变 1 个元素的情况下,该数组能否变成一个非递减数列。
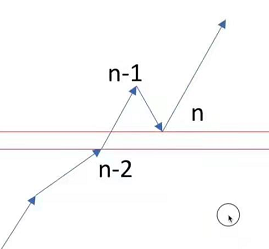
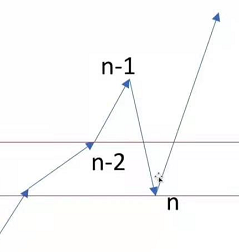
class Solution:
def checkPossibility(self, nums: List[int]) -> bool:
count = 0
for i in range(1,len(nums)):
if nums[i]>=nums[i-1]:
continue
if i-2>=0 and nums[i-2]>nums[i]:
nums[i] = nums[i-1]
else:
nums[i-1] = nums[i]
count+=1
if count == 2:
return False
return True
- 本质希望的是图一的情况,直接把前一位拉下来,但是问题是如果是图二,太低了,拉下来只会让后面的都没法进行,所以要考虑图二,即每一个要和前两个做对比。
- 这个关键是尽量改动前面,改前面改动量小,改后面非常容易让下一个失效。
划分字母区间 lc 763
字符串 S 由小写字母组成。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。返回一个表示每个字符串片段的长度的列表。

class Solution:
def partitionLabels(self, S: str) -> List[int]:
adict = {}
for i,s in enumerate(S):
adict[s] = i
last = 0
start = 0
res = []
for i,s in enumerate(S):
last = max(last,adict[s])
if last == i:
res.append(last-start+1)
start=last+1
return res
- 首先一定是遍历一遍把每个元素最后出现保存住。
- 这个题特点是让字母只出现在一坨中,所以是遍历当下去看它出现的最后一次有多大。直到序号和最大相等说明找好了,全部收进来。














 470
470











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









