







Flume
Flume的定位就是数据收集的技术
安装
1、下载
http://www.apache.org/dyn/closer.lua/flume/1.8.0/apache-flume-1.8.0-bin.tar.gz
2、上传到指定的服务器(master)中的某个目录
3、解压
tar -xvf apache-flume-1.8.0-bin.tar.gz
4、cd apache-flume-1.8.0-bin/conf
5、cp flume-conf.properties.template flume-conf.properties
6、vi flume-conf.properties
配置
第六步配置conf文件,将netcat数据展示到 console
## 定义 sources、channels 以及 sinks
## 数据源配置 依次为 netcat数据源,收集的数据暂时放在内存中
agent1.sources = netcatSrc ## netcat数据源
agent1.channels = memoryChannel ## 收集的数据暂时放在内存中
agent1.sinks = loggerSink ## 数据放在哪里去, 以log console的方式打到控制台
## netcatSrc 的配置
agent1.sources.netcatSrc.type = netcat ## source服务类型
agent1.sources.netcatSrc.bind = localhost ## 服务启在哪台机器上
agent1.sources.netcatSrc.port = 44445 ## 服务启动的端口
## loggerSink 的配置
agent1.sinks.loggerSink.type = logger
## memoryChannel 的配置
agent1.channels.memoryChannel.type = memory
agent1.channels.memoryChannel.capacity = 100
## 通过 memoryChannel 连接 netcatSrc 和 loggerSink
agent1.sources.netcatSrc.channels = memoryChannel ## 源数据放入channel
agent1.sinks.loggerSink.channel = memoryChannel ## 从channel中读取输出 这里是打印在控制台
启动
# 启动 一个agent conf读取配置文件,也就是我们上编辑的文件,并且通过logger打印INFO级别的日志到控制台
bin/flume-ng agent --conf conf --conf-file conf/flume-conf.properties --name agent1 -Dflume.root.logger=INFO,console
表示启动成功
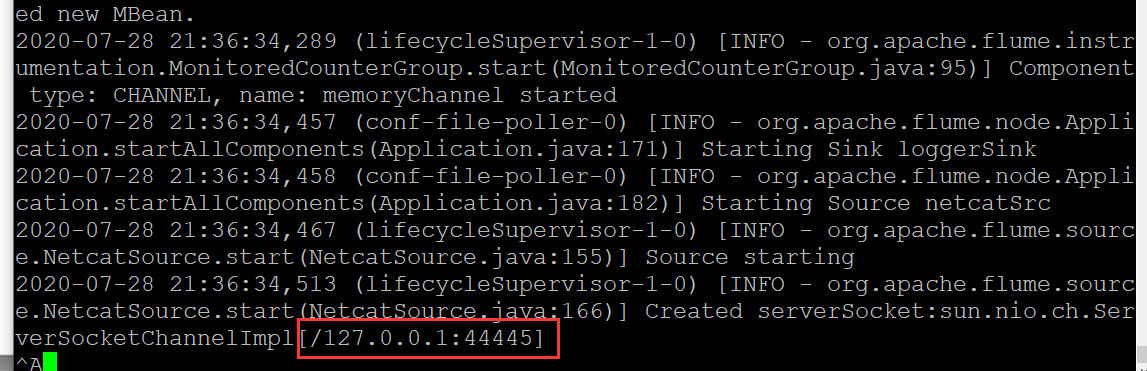
验证
在另外一个客户端上 通过telnet localhost 44445(地址和端口就是配置文件中 netcatSrc 的配置)
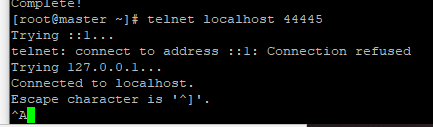
这样就表示连接上了,可以在上面随便输出内容,然后在Flume中就会接收到并打印在控制台

上面过程使用命令启动,启动的是一个agent,而接收一条记录,称为一个event
下面的从netcat中获取数据,不是输出到控制台,而是写在hdfs里
## 定义 sources、channels 以及 sinks
agent1.sources = netcatSrc
agent1.channels = memoryChannel ## 内存不稳定 agent挂掉,数据就丢了,可以用fileChannel,保存在文件中
agent1.sinks = hdfsSink
## netcatSrc 的配置
agent1.sources.netcatSrc.type = netcat
agent1.sources.netcatSrc.bind = localhost
agent1.sources.netcatSrc.port = 44445
## hdfsSink 的配置
agent1.sinks.hdfsSink.type = hdfs
agent1.sinks.hdfsSink.hdfs.path = hdfs://master:9999/user/hadoop-twq/spark-course/steaming/flume/%y-%m-%d
agent1.sinks.hdfsSink.hdfs.batchSize = 5 ## 到5条记录才写一次
agent1.sinks.hdfsSink.hdfs.useLocalTimeStamp = true
## memoryChannel 的配置
agent1.channels.memoryChannel.type = memory
agent1.channels.memoryChannel.capacity = 100
## 通过 memoryChannel 连接 netcatSrc 和 hdfsSink
agent1.sources.netcatSrc.channels = memoryChannel
agent1.sinks.hdfsSink.channel = memoryChannel
从实时查看日志中获取数据源,并保存到 HDFS中
## 定义 sources、channels 以及 sinks
agent1.sources = logSrc
agent1.channels = fileChannel
agent1.sinks = hdfsSink
## l
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 677
677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









