






(硬件环境:笔记本电脑,intel处理器i9-13900HX、64G内存、NVIDIA RTX4080(12G)、操作系统windows11家庭版)
一、下载开源大模型
在 Hugging Face 开源社区搜索“llama chinese”,选择一个适合自身硬件配置的 Llama 3中文大模型。经过多方面的比较分析,本人选择了zhouzr/Llama3-8B-Chinese-Chat-GGUF,并下载了Llama3-8B-Chinese-Chat.q6_k.GGUF版本。
二、安装ollma深度学习框架
1.访问ollma官网:https://ollama.com/;
2.点击“Download↓”按钮;
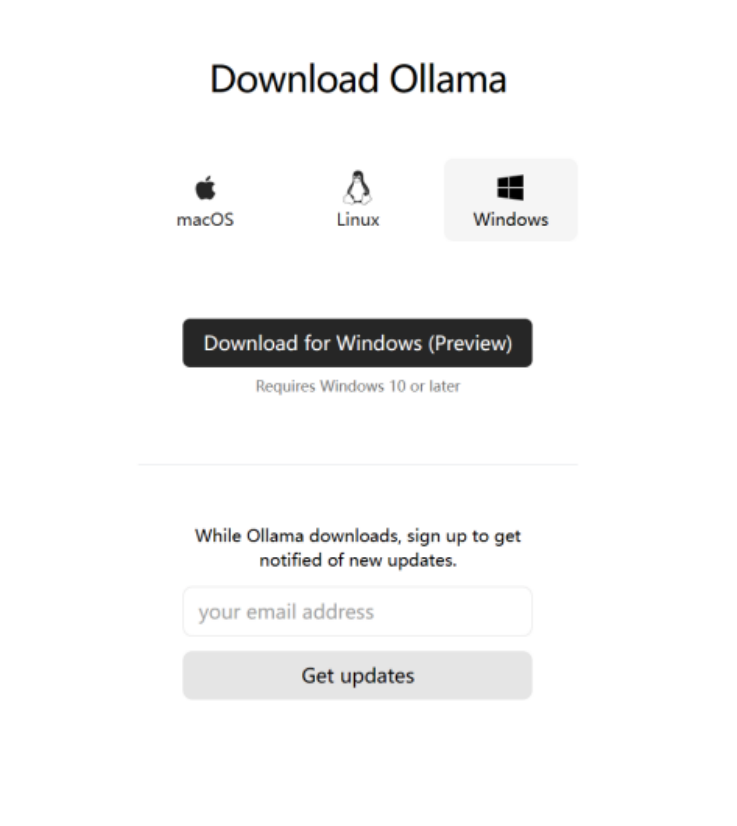
3.点击“Download for Windows(Preview)”。
4.设置ollama环境变量,重启后生效。
OLLAMA_PROXY_URL:127.0.0.1 :11434
OLLAMA_MODELS :指定ollama模型的存放路径(d:\ollama_models)
三、将下载的大模型导入ollama
1.编写Modefile(md格式)
创建一个文本文件,里面的内容是:FROM ./Llama3-8B-Chinese-Chat.q6_k.GGUF
2.创建ollama模型
ollama create llama3-8b-chinese -f Modelfile.md
四、检验模型
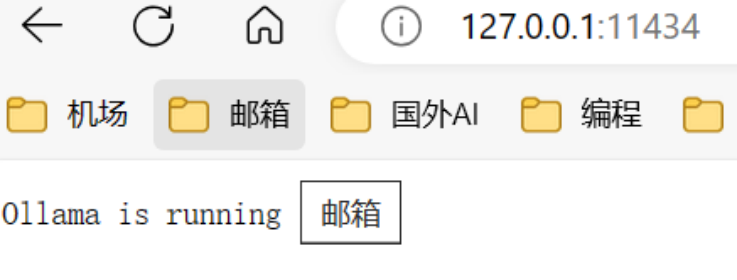
1.打开浏览器,输入:http://127.0.0.1:11434。显示以下内容,说明模型正在运行。
2.使用本地大模型,在命令行输入Ollama run llama3-8b-chinese,向大模型输入信息,看是否输出正常。
















 2104
2104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









