






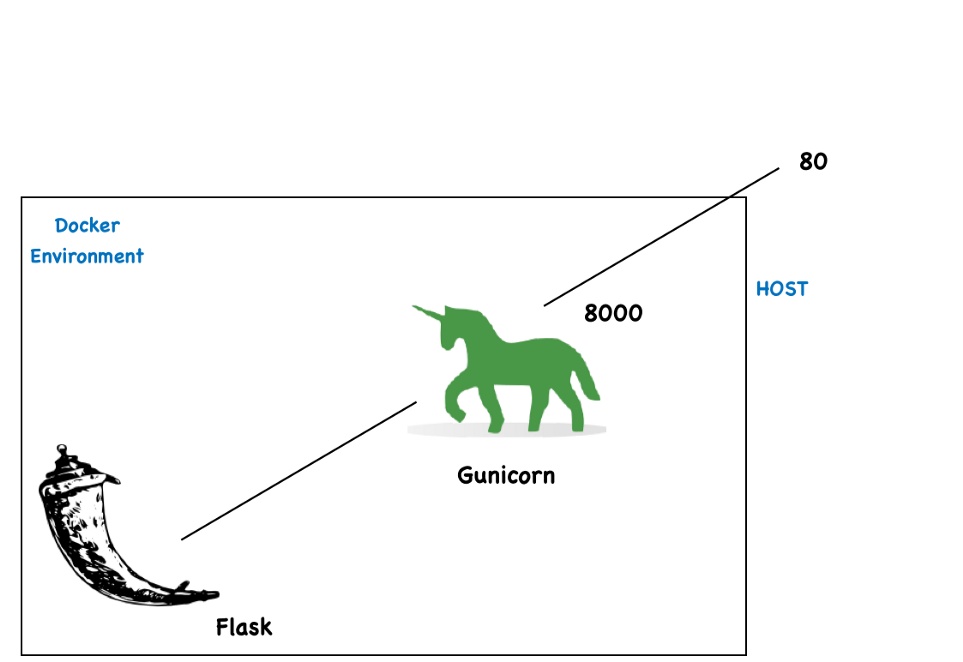
# 基于flask-gunicorn的算法部署框架介绍 此demo是为了让大家快速地部署flask框架,把自己的算法部署到计算能力更好的服务器上。是一个面向移动client—服务器server的简易科研数据分析平台。
相关链接
【搭建属于你的科研平台】(一)基于flask的服务器端算法框架搭建
基础介绍
- Flask :python最流行的两个框架之一
(django、flask),轻量级是最大的特点。ps: 知乎用tornado+SQLAlchemy开发,也是基于python的web框架 - Gunicorn:只熟悉熟悉用 java 或者 PHP 做开发的同学可能对 python 的部署一开始不太理解,Flask应用是一个符合WSGI规范的Python应用,不能独立运行(类似app.run的方式仅适合开发模式),需要依赖其他的组件提供服务器功能。
- gevent:Gunicorn 默认使用同步阻塞的网络模型
(-k sync),对于大并发的访问可能表现不够好,我们很方便地顺手套一个gevent来增加并发量

demo讲解
flask框架有两种官方的组织方式,一种是基于blueprint的,其启动文件app.py如下所示
from project import create_app #从project文件夹中的__init__.py中导入create_app函数
app = create_app() #记住这里的变量名app
if __name__ == '__main__':
app.run(debug=True)本demo中用的是新手常用版,对于我们科研场景中不需要响应数个api的情况而言,无需用blueprint的方法来科学地管理不同的api响应类、方法。如下所示:
from flask import Flask
app = Flask(__name__) #记住这里的变量名app
@app.route('/')
def hello():
return 'hello docker&flask'
if __name__ == '__main__':
app.run(host='0.0.0.0', debug=True)注意:该方法下,gunicorn.py和flask的项目文件同级。
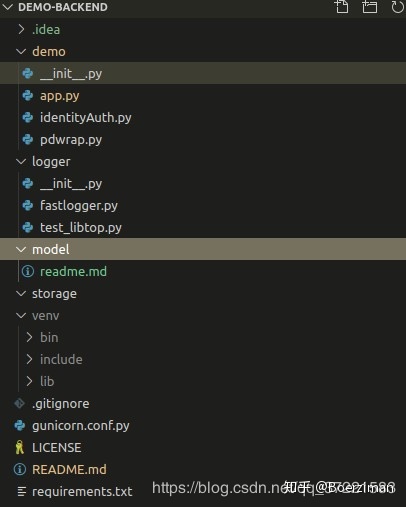
Directory : demo
1. demo/app.py
import os
import time
from flask import request, Flask, jsonify
from werkzeug.serving import WSGIRequestHandler
from logger.fastlogger import getloggerfast
from pdwrap import PdWrapper
logger = getloggerfast(__name__)
app = Flask(__name__)
dataexecuter = PdWrapper()
UPLOAD_FOLDER = '../storage'
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER # 设置文件上传的目标文件夹
basedir = os.path.abspath(os.path.dirname(__file__)) # 获取当前项目的绝对路径
@app.route('/')
def hello_world():
return 'Welcomes to Demo Cloud Platform supported by github: https://github.com/LetterLi1997'
@app.route('/api/upload', methods=['GET','POST'], strict_slashes=False)
def api_upload():
global result_done, is_processing, upload_done
upload_done = False
if request.method == 'POST':
file_dir = os.path.join(basedir, app.config['UPLOAD_FOLDER']) # 拼接成合法文件夹地址
print(file_dir)
if not os.path.exists(file_dir):
os.makedirs(file_dir) # 文件夹不存在就创建
f=request.files['myfile'] # 从表单的file字段获取文件,myfile为该表单的name值
if f:
fname=f.filename
ext = fname.rsplit('.', 1)[1] # 获取文件后缀
# unix_time = int(time.time())
# new_filename = str(unix_time)+'.'+ext # 修改文件名
f.save(os.path.join(file_dir, fname)) #保存文件到upload目录
upload_done = True
print('上传成功-----result_done:{}, is_processing:{}, upload_done:{}'.format(result_done, is_processing, upload_done))
'''
这里调用算法处理函数
eg. time.sleep(15) #算法处理时长为15s
'''
return jsonify({"errno": 0, "errmsg": "上传成功"})
else:
print('上传失败')
upload_done = False
return jsonify({"errno": 1001, "errmsg": "上传失败"})
if __name__ == '__main__':
app.run(host='0.0.0.0', debug=True)这是最重要的入口文件。能够拦截下手机app上传的POST数据,将上传的文件存储到storage文件夹中。
2. demo/pdwrap.py
这里是用于封装个人的算法,给出了一个例子~ 技术大佬多多指教哈,可能大家平时做科研的时候比较追求效率,代码的结构上不会非常注意。本人参考了一些开源代码的好习惯,用类来封装这个算法。
3. demo/identityAuth.py
这里是具体的算法实现,在pdwrap.py中可以调用具体的代码,这样整体的框架就会比较清晰。
logger
这个文件夹是为了良好的习惯,可将post等访问请求、算法分析的结构等保存到run.log中。
model
这个文件用来存放神经网络、机器学习的模型
storage
该路径存放app上传文件,demo中的算法取storage中的文件进行处理。
这篇文章预提供简易版的backend例程。 - github下载/clone demo,欢迎star/pull request etc. 哈!















 1012
1012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









