







概论
该篇文章讲述了NeoPI如何利用统计学特征来检测webshell,笔者认为NeoPI选择的这些统计学方法在webshell检测上有些鸡肋,没有太大的实用效果。
反而其中的各种统计学方法值得学习一下,因此文章会重点讲解这些统计学特征的原理,以求可以举一反三,并应用在其他领域。
统计学特征
NeoPi使用以下五种统计学特征检测方法,下面分别来分析各种方法的原理和代码实现(代码部分只选择了核心代码并附加了注释,方便大家阅读。):
重合指数
重合指数法是密码分析学的一种工具,主要用于多表代换的密码破译。以纯英文文本为例,它的基本原理可以定义如下:

根据统计,在英文中各个字母出现的频率是特定的,如下表 :
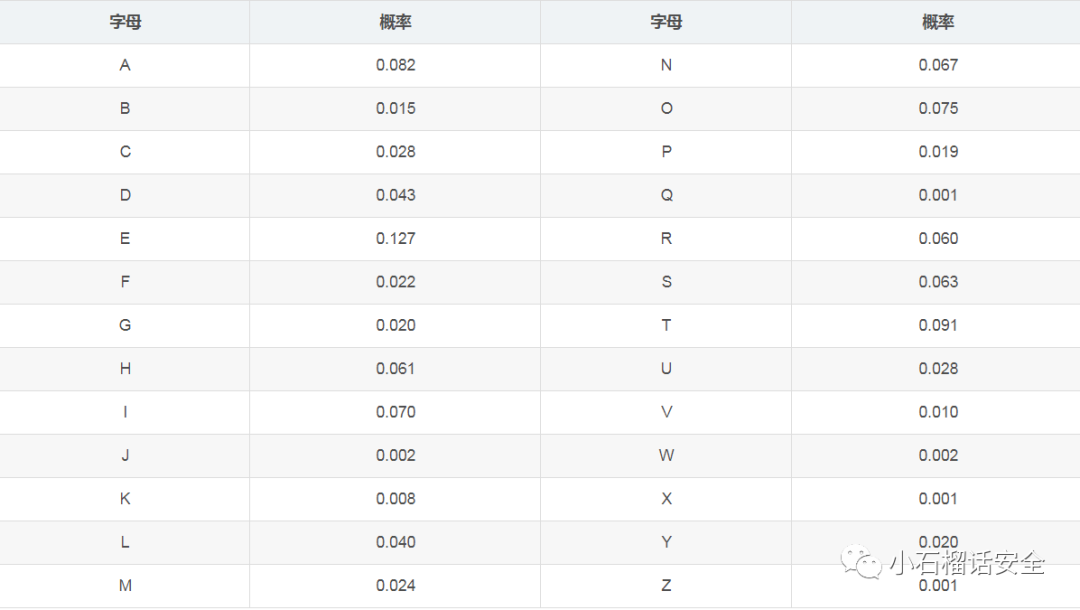

如上所述,一个纯英文的且编码风格良好(一般在软件开发时,会采用统一的函数及有意义的变量名编写)的源代码计算出的重合指数会趋近于0.065。考虑到文件中的中文注释,虽然计算出的重合指数会偏离0,065,但同样会趋于相似,呈现正态分布。
而加密或者混淆后的webshell 与原 web 应用不相关,其字符的排列通常没有特征可言
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8119
8119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









