






Pytorch学习记录-torchtext和Pytorch的实例4
0. PyTorch Seq2Seq项目介绍
在完成基本的torchtext之后,找到了这个教程,《基于Pytorch和torchtext来理解和实现seq2seq模型》。 这个项目主要包括了6个子项目
- ~~使用神经网络训练Seq2Seq~~
- ~~使用RNN encoder-decoder训练短语表示用于统计机器翻译~~
- ~~使用共同学习完成NMT的堆砌和翻译~~
- ~~打包填充序列、掩码和推理~~
- ~~卷积Seq2Seq~~
- Transformer
6. Transformer
OK,来到最后一章,Transformer,又回到这个模型啦,绕不开的,依旧没有讲解,只能看看代码。 来源不用说了,《Attention is all you need》。Transformer在之前复习了多次,这次也一样,不知道教程会如何实现,反正之前学得挺痛苦的。
6.1 准备数据
这里使用了一个新的数据集TranslationDataset,机器翻译数据集是 TranslationDataset 类的子类。
import torchimport torch.nn as nnimport torch.optim as optimimport torch.nn.functional as Fimport torchtext#机器翻译数据集是 TranslationDataset 类的子类。from torchtext.datasets import TranslationDataset, Multi30kfrom torchtext.data import Field, BucketIteratorimport spacyimport randomimport mathimport osimport timeSEED=1234random.seed(SEED)torch.manual_seed(SEED)torch.backends.cudnn.deterministic=Truespacy_de = spacy.load('de')spacy_en = spacy.load('en')def tokenize_de(text): return [tok.text for tok in spacy_de.tokenizer(text)]def tokenize_en(text): return [tok.text for tok in spacy_en.tokenizer(text)]SRC=Field(tokenize=tokenize_de, init_token='', eos_token='', lower=True, batch_first=True)TRG=Field(tokenize=tokenize_en, init_token='', eos_token='', lower=True, batch_first=True)train_data,valid_data,test_data=Multi30k.splits( exts=('.de','.en'), fields=(SRC, TRG))SRC.build_vocab(train_data,min_freq=2)TRG.build_vocab(train_data,min_freq=2)device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')print(device)BATCH_SIZE=128train_iterator, valid_iterator, test_iterator=BucketIterator.splits( (train_data,valid_data,test_data), batch_size=BATCH_SIZE, device=device)cuda6.2 构建模型
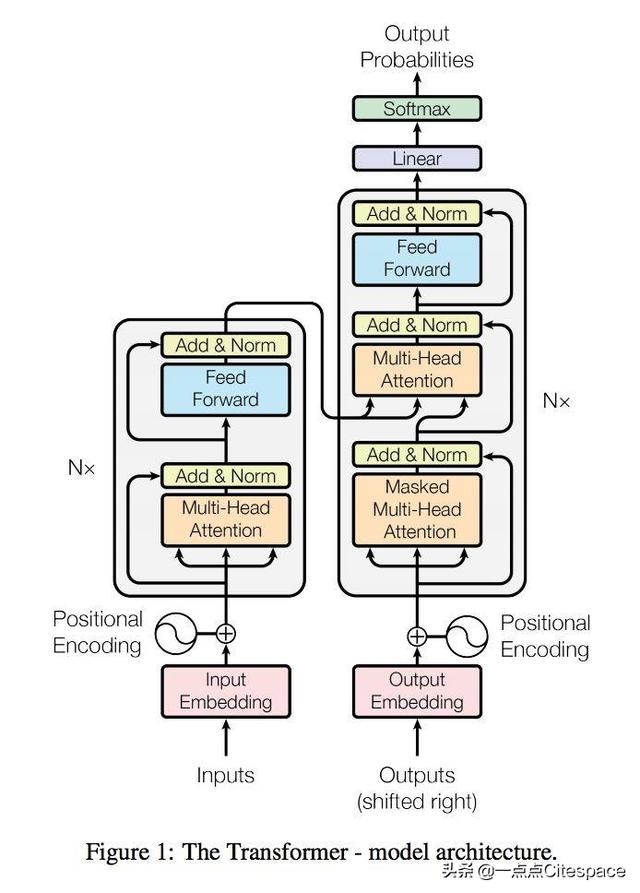
6.2.1 encoder和decoder
6.2.2 使用多种attention机制(multi-head context-attention、multi-head self-attention)
6.2.2.1 multi head self-attention
6.2.2.2 multi head context-attention
6.2.2.3 如何实现Attention?
6.2.2.4 如何实现multi-heads attention?
6.2.3 使用Layer-Normalization机制
6.2.4.1 padding mask
6.2.4.2 sequence mask
6.2.5 使用残差residual connection
6.2.6 使用Positional-encoding
6.2.7 Position-wise Feed-Forward network
6.3.1 Encoder
照例是Encoder部分,包括了Encoder,EncoderLayer,SelfAttention,PositionwiseFeedforward四个部分
class Encoder(nn.Module): def __init__(self, input_dim, hid_dim, n_layers, n_heads, pf_dim, encoder_layer, self_attention, positionwise_feedforward, dropout, device): super(Encoder, self).__init__() self.input_dim=input_dim self.hid_dim=hid_dim self.n_layers=n_layers self.n_heads=n_heads self.pf_dim=pf_dim self.encoder_layer=encoder_layer self.self_attention=self_attention self.positionwise_feedforward=positionwise_feedforward self.dropout=dropout self.device=device self.tok_embedding=nn.Embedding(input_dim, hid_dim) self.pos_embedding=nn.Embedding(1000,hid_dim) self.layers=nn.ModuleList([encoder_layer(hid_dim, n_heads, pf_dim, self_attention, positionwise_feedforward, dropout, device) for _ in range(n_layers)]) self.do=nn.Dropout(dropout) self.scale=torch.sqrt(torch.FloatTensor([hid_dim])).to(device) def forward(self, src, src_mask): #src = [batch size, src sent len] #src_mask = [batch size, src sent len] pos=torch.arange(0,src.shape[1]).unsqueeze(0).repeat(src.shape[0],1).to(self.device) src=self.do((self.tok_embedding(src)*self.scale)+self.pos_embedding(pos)) #src = [batch size, src sent len, hid dim] for layer in self.layers: src=layer(src, src_mask) return srcclass EncoderLayer(nn.Module): def __init__(self, hid_dim, n_heads, pf_dim, self_attention, postionwise_feedforward,dropout,device): super(EncoderLayer,self).__init__() self.ln=nn.LayerNorm(hid_dim) self.sa=self_attention(hid_dim,n_heads,dropout,device) self.pf=postionwise_feedforward(hid_dim, pf_dim,dropout) self.do=nn.Dropout(dropout) def forward(self, src, src_mask): #src = [batch size, src sent len, hid dim] #src_mask = [batch size, src sent len] src=self.ln(src+self.do(self.sa(src,src,src,src_mask))) src=self.ln(src+self.do(self.pf(src))) return srcclass SelfAttention(nn.Module): def __init__(self, hid_dim, n_heads, dropout, device): super(SelfAttention,self).__init__() self.hid_dim=hid_dim self.n_heads=n_heads assert hid_dim%n_heads==0 self.w_q=nn.Linear(hid_dim,hid_dim) self.w_k=nn.Linear(hid_dim, hid_dim) self.w_v=nn.Linear(hid_dim, hid_dim) self.fc=nn.Linear(hid_dim,hid_dim) self.do=nn.Dropout(dropout) self.scale=torch.sqrt(torch.FloatTensor([hid_dim//n_heads])).to(device) def forward(self, query, key, value, mask=None): bsz=query.shape[0] #query = key = value [batch size, sent len, hid dim] Q=self.w_q(query) K=self.w_k(key) V=self.w_v(value) #Q, K, V = [batch size, sent len, hid dim] Q = Q.view(bsz, -1, self.n_heads, self.hid_dim // self.n_heads).permute(0, 2, 1, 3) K = K.view(bsz, -1, self.n_heads, self.hid_dim // self.n_heads).permute(0, 2, 1, 3) V = V.view(bsz, -1, self.n_heads, self.hid_dim // self.n_heads).permute(0, 2, 1, 3) #Q, K, V = [batch size, n heads, sent len, hid dim // n heads] # 实现attentionQ*K^T/D energy=torch.matmul(Q,K.permute(0,1,3,2))/self.scale #energy = [batch size, n heads, sent len, sent len] if mask is not None: energy=energy.masked_fill(mask==0, -1e10) # 实现softmax部分 attention=self.do(F.softmax(energy, dim=-1)) #attention = [batch size, n heads, sent len, sent len] x=torch.matmul(attention,V) #x = [batch size, n heads, sent len, hid dim // n heads] x=x.permute(0,2,1,3).contiguous() #x = [batch size, sent len, n heads, hid dim // n heads] x=x.view(bsz, -1, self.n_heads*(self.hid_dim//self.n_heads)) #x = [batch size, src sent len, hid dim] x=self.fc(x) return xclass PositionwiseFeedforward(nn.Module): def __init__(self, hid_dim, pf_dim, dropout): super(PositionwiseFeedforward,self).__init__() self.hid_dim=hid_dim self.pf_dim=pf_dim self.fc_1=nn.Conv1d(hid_dim,pf_dim,1) self.fc_2=nn.Conv1d(pf_dim, hid_dim, 1) self.do=nn.Dropout(dropout) def forward(self,x): #x = [batch size, sent len, hid dim] x = x.permute(0, 2, 1) #x = [batch size, hid dim, sent len] x = self.do(F.relu(self.fc_1(x))) #x = [batch size, ff dim, sent len] x = self.fc_2(x) #x = [batch size, hid dim, sent len] x = x.permute(0, 2, 1) #x = [batch size, sent len, hid dim] return x6.3.2 Decoder
Decoder部分包括Decoder,DecoderLayer两个部分
class Decoder(nn.Module): def __init__(self, output_dim, hid_dim,n_layers,n_heads,pf_dim,decoder_layer,self_attention,positionwise_feedforward,dropout,device): super(Decoder,self).__init__() self.output_dim=output_dim self.hid_dim=hid_dim self.n_layers=n_layers self.n_heads = n_heads self.pf_dim = pf_dim self.decoder_layer = decoder_layer self.self_attention = self_attention self.positionwise_feedforward = positionwise_feedforward self.dropout = dropout self.device = device self.tok_embedding=nn.Embedding(output_dim, hid_dim) self.pos_embedding=nn.Embedding(1000,hid_dim) self.layers=nn.ModuleList([decoder_layer(hid_dim,n_heads,pf_dim,self_attention,positionwise_feedforward,dropout,device) for _ in range(n_layers)]) self.fc=nn.Linear(hid_dim, output_dim) self.do=nn.Dropout(dropout) self.scale=torch.sqrt(torch.FloatTensor([hid_dim])).to(device) def forward(self, trg, src, trg_mask, src_mask): #trg = [batch_size, trg sent len] #src = [batch_size, src sent len] #trg_mask = [batch size, trg sent len] #src_mask = [batch size, src sent len] pos=torch.arange(0, trg.shape[1]).unsqueeze(0).repeat(trg.shape[0], 1).to(self.device) trg=self.do((self.tok_embedding(trg)*self.scale)+self.pos_embedding(pos)) for layer in self.layers: trg=layer(trg,src,trg_mask,src_mask) return self.fc(trg)class DecoderLayer(nn.Module): def __init__(self, hid_dim, n_heads, pf_dim, self_attention, positionwise_feedforward, dropout, device): super().__init__() self.ln = nn.LayerNorm(hid_dim) self.sa = self_attention(hid_dim, n_heads, dropout, device) self.ea = self_attention(hid_dim, n_heads, dropout, device) self.pf = positionwise_feedforward(hid_dim, pf_dim, dropout) self.do = nn.Dropout(dropout) def forward(self, trg, src, trg_mask, src_mask): #trg = [batch size, trg sent len, hid dim] #src = [batch size, src sent len, hid dim] #trg_mask = [batch size, trg sent len] #src_mask = [batch size, src sent len] trg = self.ln(trg + self.do(self.sa(trg, trg, trg, trg_mask))) trg = self.ln(trg + self.do(self.ea(trg, src, src, src_mask))) trg = self.ln(trg + self.do(self.pf(trg))) return trg6.3.3 模型整合
class Seq2Seq(nn.Module): def __init__(self, encoder, decoder, pad_idx, device): super().__init__() self.encoder = encoder self.decoder = decoder self.pad_idx = pad_idx self.device = device def make_masks(self, src, trg): #src = [batch size, src sent len] #trg = [batch size, trg sent len] src_mask = (src != self.pad_idx).unsqueeze(1).unsqueeze(2) trg_pad_mask = (trg != self.pad_idx).unsqueeze(1).unsqueeze(3) trg_len = trg.shape[1] trg_sub_mask = torch.tril(torch.ones((trg_len, trg_len), dtype=torch.uint8, device=self.device)) trg_mask = trg_pad_mask & trg_sub_mask return src_mask, trg_mask def forward(self, src, trg): #src = [batch size, src sent len] #trg = [batch size, trg sent len] src_mask, trg_mask = self.make_masks(src, trg) enc_src = self.encoder(src, src_mask) #enc_src = [batch size, src sent len, hid dim] out = self.decoder(trg, enc_src, trg_mask, src_mask) #out = [batch size, trg sent len, output dim] return outinput_dim=len(SRC.vocab)hid_dim=512n_layers=6n_heads=8pf_dim=2048dropout=0.1enc=Encoder(input_dim,hid_dim,n_layers,n_heads,pf_dim,EncoderLayer,SelfAttention,PositionwiseFeedforward,dropout,device)output_dim=len(TRG.vocab)hid_dim=512n_layers=6n_heads=8pf_dim=2048dropout=0.1dec=Decoder(output_dim,hid_dim, n_layers, n_heads, pf_dim, DecoderLayer, SelfAttention, PositionwiseFeedforward, dropout, device)pad_idx=SRC.vocab.stoi['']model=Seq2Seq(enc,dec,pad_idx,device).to(device)model这部分是模型结构输出,可以看到Encoder和Decoder的结构,建议和前面的图进行一次对比。
Seq2Seq( (encoder): Encoder( (tok_embedding): Embedding(7855, 512) (pos_embedding): Embedding(1000, 512) (layers): ModuleList( (0): EncoderLayer( (ln): LayerNorm(torch.Size([512]), eps=1e-05, elementwise_affine=True) (sa): SelfAttention( (w_q): Linear(in_features=512, out_features=512, bias=True) (w_k): Linear(in_features=512, out_features=512, bias=True) (w_v): Linear(in_features=512, out_features=512, bias=True) (fc): Linear(in_features=512, out_features=512, bias=True) (do): Dropout(p=0.1) ) (pf): PositionwiseFeedforward( (fc_1): Conv1d(512, 2048, kernel_size=(1,), stride=(1,)) (fc_2): Conv1d(2048, 512, kernel_size=(1,), stride=(1,)) (do): Dropout(p=0.1) ) (do): Dropout(p=0.1) ) (1): EncoderLayer( (ln): LayerNorm(torch.Size([512]), eps=1e-05, elementwise_affine=True) (sa): SelfAttention( (w_q): Linear(in_features=512, out_features=512, bias=True) (w_k): Linear(in_features=512, out_features=512, bias=True) (w_v): Linear(in_features=512, out_features=512, bias=True) (fc): Linear(in_features=512, out_features=512, bias=True) (do): Dropout(p=0.1) ) (pf): PositionwiseFeedforward( (fc_1): Conv1d(512, 2048, kernel_size=(1,), stride=(1,)) (fc_2): Conv1d(2048, 512, kernel_size=(1,), stride=(1,)) (do): Dropout(p=0.1) ) (do): Dropout(p=0.1) ) (2): EncoderLayer( (ln): LayerNorm(torch.Size([512]), eps=1e-05, elementwise_affine=True) (sa): SelfAttention( (w_q): Linear(in_features=512, out_features=512, bias=True) (w_k): Linear(in_features=512, out_features=512, bias=True) (w_v): Linear(in_features=512, out_features=512, bias=True) (fc): Linear(in_features=512, out_features=512, bias=True) (do): Dropout(p=0.1) ) (pf): PositionwiseFeedforward( (fc_1): Conv1d(512, 2048, kernel_size=(1,), stride=(1,)) (fc_2): Conv1d(2048, 512, kernel_size=(1,), stride=(1,)) (do): Dropout(p=0.1) ) (do): Dropout(p=0.1) ) (3): EncoderLayer( (ln): LayerNorm(torch.Size([512]), eps=1e-05, elementwise_affine=True) (sa): SelfAttention( (w_q): Linear(in_features=512, out_features=512, bias=True) (w_k): Linear(in_features=512, out_features=512, bias=True) (w_v): Linear(in_features=512, out_features=512, bias=True) (fc): Linear(in_features=512, out_features=512, bias=True) (do): Dropout(p=0.1) ) (pf): PositionwiseFeedforward( (fc_1): Conv1d(512, 2048, kernel_size=(1,), stride=(1,)) (fc_2): Conv1d(2048, 512, kernel_size=(1,), stride=(1,)) (do): Dropout(p=0.1) ) (do): Dropout(p=0.1) ) (4): EncoderLayer( (ln): LayerNorm(torch.Size([512]), eps=1e-05, elementwise_affine=True) (sa): SelfAttention( (w_q): Linear(in_features=512, out_features=512, bias=True) (w_k): Linear(in_features=512, out_features=512, bias=True) (w_v): Linear(in_features=512, out_features=512, bias=True) (fc): Linear(in_features=512, out_features=512, bias=True) (do): Dropout(p=0.1) ) (pf): PositionwiseFeedforward( (fc_1): Conv1d(512, 2048, kernel_size=(1,), stride=(1,)) (fc_2): Conv1d(2048, 512, kernel_size=(1,), stride=(1,)) (do): Dropout(p=0.1) ) (do): Dropout(p=0.1) ) (5): EncoderLayer( (ln): LayerNorm(torch.Size([512]), eps=1e-05, elementwise_affine=True) (sa): SelfAttention( (w_q): Linear(in_features=512, out_features=512, bias=True) (w_k): Linear(in_features=512, out_features=512, bias=True) (w_v): Linear(in_features=512, out_features=512, bias=True) (fc): Linear(in_features=512, out_features=512, bias=True) (do): Dropout(p=0.1) ) (pf): PositionwiseFeedforward( (fc_1): Conv1d(512, 2048, kernel_size=(1,), stride=(1,)) (fc_2): Conv1d(2048, 512, kernel_size=(1,), stride=(1,)) (do): Dropout(p=0.1) ) (do): Dropout(p=0.1) ) ) (do): Dropout(p=0.1) ) (decoder): Decoder( (tok_embedding): Embedding(5893, 512) (pos_embedding): Embedding(1000, 512) (layers): ModuleList( (0): DecoderLayer( (ln): LayerNorm(torch.Size([512]), eps=1e-05, elementwise_affine=True) (sa): SelfAttention( (w_q): Linear(in_features=512, out_features=512, bias=True) (w_k): Linear(in_features=512, out_features=512, bias=True) (w_v): Linear(in_features=512, out_features=512, bias=True) (fc): Linear(in_features=512, out_features=512, bias=True) (do): Dropout(p=0.1) ) (ea): SelfAttention( (w_q): Linear(in_features=512, out_features=512, bias=True) (w_k): Linear(in_features=512, out_features=512, bias=True) (w_v): Linear(in_features=512, out_features=512, bias=True) (fc): Linear(in_features=512, out_features=512, bias=True) (do): Dropout(p=0.1) ) (pf): PositionwiseFeedforward( (fc_1): Conv1d(512, 2048, kernel_size=(1,), stride=(1,)) (fc_2): Conv1d(2048, 512, kernel_size=(1,), stride=(1,)) (do): Dropout(p=0.1) ) (do): Dropout(p=0.1) ) (1): DecoderLayer( (ln): LayerNorm(torch.Size([512]), eps=1e-05, elementwise_affine=True) (sa): SelfAttention( (w_q): Linear(in_features=512, out_features=512, bias=True) (w_k): Linear(in_features=512, out_features=512, bias=True) (w_v): Linear(in_features=512, out_features=512, bias=True) (fc): Linear(in_features=512, out_features=512, bias=True) (do): Dropout(p=0.1) ) (ea): SelfAttention( (w_q): Linear(in_features=512, out_features=512, bias=True) (w_k): Linear(in_features=512, out_features=512, bias=True) (w_v): Linear(in_features=512, out_features=512, bias=True) (fc): Linear(in_features=512, out_features=512, bias=True) (do): Dropout(p=0.1) ) (pf): PositionwiseFeedforward( (fc_1): Conv1d(512, 2048, kernel_size=(1,), stride=(1,)) (fc_2): Conv1d(2048, 512, kernel_size=(1,), stride=(1,)) (do): Dropout(p=0.1) ) (do): Dropout(p=0.1) ) (2): DecoderLayer( (ln): LayerNorm(torch.Size([512]), eps=1e-05, elementwise_affine=True) (sa): SelfAttention( (w_q): Linear(in_features=512, out_features=512, bias=True) (w_k): Linear(in_features=512, out_features=512, bias=True) (w_v): Linear(in_features=512, out_features=512, bias=True) (fc): Linear(in_features=512, out_features=512, bias=True) (do): Dropout(p=0.1) ) (ea): SelfAttention( (w_q): Linear(in_features=512, out_features=512, bias=True) (w_k): Linear(in_features=512, out_features=512, bias=True) (w_v): Linear(in_features=512, out_features=512, bias=True) (fc): Linear(in_features=512, out_features=512, bias=True) (do): Dropout(p=0.1) ) (pf): PositionwiseFeedforward( (fc_1): Conv1d(512, 2048, kernel_size=(1,), stride=(1,)) (fc_2): Conv1d(2048, 512, kernel_size=(1,), stride=(1,)) (do): Dropout(p=0.1) ) (do): Dropout(p=0.1) ) (3): DecoderLayer( (ln): LayerNorm(torch.Size([512]), eps=1e-05, elementwise_affine=True) (sa): SelfAttention( (w_q): Linear(in_features=512, out_features=512, bias=True) (w_k): Linear(in_features=512, out_features=512, bias=True) (w_v): Linear(in_features=512, out_features=512, bias=True) (fc): Linear(in_features=512, out_features=512, bias=True) (do): Dropout(p=0.1) ) (ea): SelfAttention( (w_q): Linear(in_features=512, out_features=512, bias=True) (w_k): Linear(in_features=512, out_features=512, bias=True) (w_v): Linear(in_features=512, out_features=512, bias=True) (fc): Linear(in_features=512, out_features=512, bias=True) (do): Dropout(p=0.1) ) (pf): PositionwiseFeedforward( (fc_1): Conv1d(512, 2048, kernel_size=(1,), stride=(1,)) (fc_2): Conv1d(2048, 512, kernel_size=(1,), stride=(1,)) (do): Dropout(p=0.1) ) (do): Dropout(p=0.1) ) (4): DecoderLayer( (ln): LayerNorm(torch.Size([512]), eps=1e-05, elementwise_affine=True) (sa): SelfAttention( (w_q): Linear(in_features=512, out_features=512, bias=True) (w_k): Linear(in_features=512, out_features=512, bias=True) (w_v): Linear(in_features=512, out_features=512, bias=True) (fc): Linear(in_features=512, out_features=512, bias=True) (do): Dropout(p=0.1) ) (ea): SelfAttention( (w_q): Linear(in_features=512, out_features=512, bias=True) (w_k): Linear(in_features=512, out_features=512, bias=True) (w_v): Linear(in_features=512, out_features=512, bias=True) (fc): Linear(in_features=512, out_features=512, bias=True) (do): Dropout(p=0.1) ) (pf): PositionwiseFeedforward( (fc_1): Conv1d(512, 2048, kernel_size=(1,), stride=(1,)) (fc_2): Conv1d(2048, 512, kernel_size=(1,), stride=(1,)) (do): Dropout(p=0.1) ) (do): Dropout(p=0.1) ) (5): DecoderLayer( (ln): LayerNorm(torch.Size([512]), eps=1e-05, elementwise_affine=True) (sa): SelfAttention( (w_q): Linear(in_features=512, out_features=512, bias=True) (w_k): Linear(in_features=512, out_features=512, bias=True) (w_v): Linear(in_features=512, out_features=512, bias=True) (fc): Linear(in_features=512, out_features=512, bias=True) (do): Dropout(p=0.1) ) (ea): SelfAttention( (w_q): Linear(in_features=512, out_features=512, bias=True) (w_k): Linear(in_features=512, out_features=512, bias=True) (w_v): Linear(in_features=512, out_features=512, bias=True) (fc): Linear(in_features=512, out_features=512, bias=True) (do): Dropout(p=0.1) ) (pf): PositionwiseFeedforward( (fc_1): Conv1d(512, 2048, kernel_size=(1,), stride=(1,)) (fc_2): Conv1d(2048, 512, kernel_size=(1,), stride=(1,)) (do): Dropout(p=0.1) ) (do): Dropout(p=0.1) ) ) (fc): Linear(in_features=512, out_features=5893, bias=True) (do): Dropout(p=0.1) ) )6.4.1 参数设置
def count_parameters(model): return sum(p.numel() for p in model.parameters() if p.requires_grad)print(f'The model has {count_parameters(model):,} trainable parameters')The model has 55,206,149 trainable parametersfor p in model.parameters(): if p.dim() > 1: nn.init.xavier_uniform_(p)class NoamOpt: "Optim wrapper that implements rate." def __init__(self, model_size, factor, warmup, optimizer): self.optimizer = optimizer self._step = 0 self.warmup = warmup self.factor = factor self.model_size = model_size self._rate = 0 def step(self): "Update parameters and rate" self._step += 1 rate = self.rate() for p in self.optimizer.param_groups: p['lr'] = rate self._rate = rate self.optimizer.step() def rate(self, step = None): "Implement `lrate` above" if step is None: step = self._step return self.factor * (self.model_size ** (-0.5) * min(step ** (-0.5), step * self.warmup ** (-1.5)))optimizer = NoamOpt(hid_dim, 1, 2000, torch.optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9))criterion = nn.CrossEntropyLoss(ignore_index=pad_idx)6.4.2 模型训练
def train(model, iterator, optimizer, criterion, clip): model.train() epoch_loss = 0 for i, batch in enumerate(iterator): src = batch.src trg = batch.trg optimizer.optimizer.zero_grad() output = model(src, trg[:,:-1]) #output = [batch size, trg sent len - 1, output dim] #trg = [batch size, trg sent len] output = output.contiguous().view(-1, output.shape[-1]) trg = trg[:,1:].contiguous().view(-1) #output = [batch size * trg sent len - 1, output dim] #trg = [batch size * trg sent len - 1] loss = criterion(output, trg) loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), clip) optimizer.step() epoch_loss += loss.item() return epoch_loss / len(iterator)def evaluate(model, iterator, criterion): model.eval() epoch_loss = 0 with torch.no_grad(): for i, batch in enumerate(iterator): src = batch.src trg = batch.trg output = model(src, trg[:,:-1]) #output = [batch size, trg sent len - 1, output dim] #trg = [batch size, trg sent len] output = output.contiguous().view(-1, output.shape[-1]) trg = trg[:,1:].contiguous().view(-1) #output = [batch size * trg sent len - 1, output dim] #trg = [batch size * trg sent len - 1] loss = criterion(output, trg) epoch_loss += loss.item() return epoch_loss / len(iterator)def epoch_time(start_time, end_time): elapsed_time = end_time - start_time elapsed_mins = int(elapsed_time / 60) elapsed_secs = int(elapsed_time - (elapsed_mins * 60)) return elapsed_mins, elapsed_secsN_EPOCHS = 10CLIP = 1SAVE_DIR = 'models'MODEL_SAVE_PATH = os.path.join(SAVE_DIR, 'transformer-seq2seq.pt')best_valid_loss = float('inf')if not os.path.isdir(f'{SAVE_DIR}'): os.makedirs(f'{SAVE_DIR}')for epoch in range(N_EPOCHS): start_time = time.time() train_loss = train(model, train_iterator, optimizer, criterion, CLIP) valid_loss = evaluate(model, valid_iterator, criterion) end_time = time.time() epoch_mins, epoch_secs = epoch_time(start_time, end_time) if valid_loss < best_valid_loss: best_valid_loss = valid_loss torch.save(model.state_dict(), MODEL_SAVE_PATH) print(f'| Epoch: {epoch+1:03} | Time: {epoch_mins}m {epoch_secs}s| Train Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f} | Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f} |')大概跑了一下结果,真不知道教程用什么硬件运行的,才40多秒的速度……
| Epoch: 001 | Time: 1m 44s| Train Loss: 5.924 | Train PPL: 373.732 | Val. Loss: 4.119 | Val. PPL: 61.478 |
| Epoch: 002 | Time: 1m 48s| Train Loss: 3.778 | Train PPL: 43.709 | Val. Loss: 3.177 | Val. PPL: 23.976 |
| Epoch: 003 | Time: 1m 48s| Train Loss: 3.133 | Train PPL: 22.939 | Val. Loss: 2.812 | Val. PPL: 16.645 |
| Epoch: 004 | Time: 1m 48s| Train Loss: 2.763 | Train PPL: 15.846 | Val. Loss: 2.611 | Val. PPL: 13.615 |
| Epoch: 005 | Time: 1m 47s| Train Loss: 2.500 | Train PPL: 12.183 | Val. Loss: 2.421 | Val. PPL: 11.260 |
| Epoch: 006 | Time: 1m 48s| Train Loss: 2.310 | Train PPL: 10.073 | Val. Loss: 2.334 | Val. PPL: 10.318 |















 1443
1443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









