





本文未经允许禁止转载,谢谢合作。
本文我们介绍高斯过程及其在机器学习中应用的一个例子——高斯过程回归。
高斯过程在语音合成中有广泛的应用,我计划在之后的文章中介绍一些应用,但本节我们重点讨论相关的基础知识。
本文的大部分内容来自Stanford CS229-gaussian_process,有兴趣的同学可以去看英文原版。
明天是元旦,因此也祝大家元旦快乐。
1. 多元高斯分布
1.1 定义
设随机变量
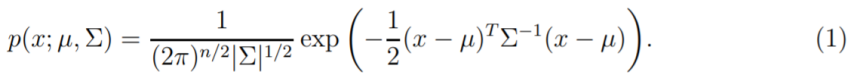
我们用
多元高斯变量在机器学习中非常常用,主要是因为它有下面两个特点:
① 可以用来建模噪声
② 在很多积分中,如果有高斯分布,则很多情况下可以得到简单的封闭形式的解。
1.2 性质
我们首先假设x被分成了两个部分

那么有下面的性质成立:
① Normalization
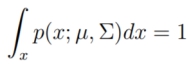
② Marginalization
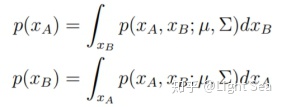
也是多元高斯分布,满足:

③ Conditioning
以高斯随机变量作为条件的分布还是高斯分布,比如:
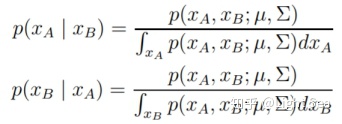
满足:
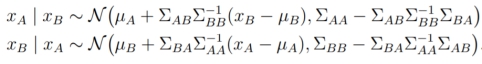
证明比较繁琐,这里略过,但这个结论对后面的讲解比较重要,大家需要重点关注一下。
④ Summation
相同维度的独立高斯随机变量的和仍然满足高斯分布:
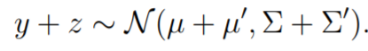
2. Bayesian Linear Regression
设
回忆线性回归模型:
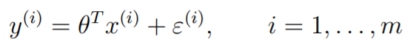
这里
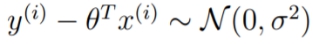
如果给定了

我们定义下面的符号,用来简化符号:
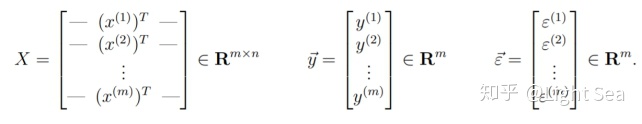
当然,参数
为了处理参数,在贝叶斯线性回归中,我们一般会假设参数
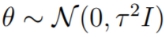
使用贝叶斯规则,我们可以得到parameter posterior:

在这种情况下,如果我们假设测试集中的点也满足和训练集一样的模型,那么贝叶斯回归的输出就不是一个固定的点,而是输出的分布:
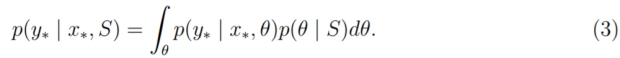
我们称这个分布为posterior predictive distribution。
当然,上面的式子看起来优雅,但是对于很多模型来说,实际计算时却是基本算不出来的,因为随着训练集或者参数维度的增加,复杂度就会飞速增长。因此一般情况下我们会避开直接计算,使用估计的方法来计算上式,比如最典型的MAP估计。
幸运的是,在贝叶斯回归中,上式是可以计算出来的,经过复杂的计算我们可以得到:
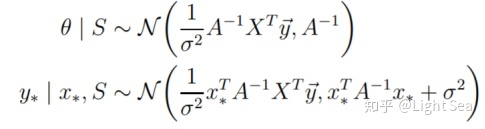
其中:
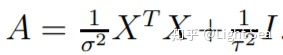
从上式中我们可以发现,任何测试点
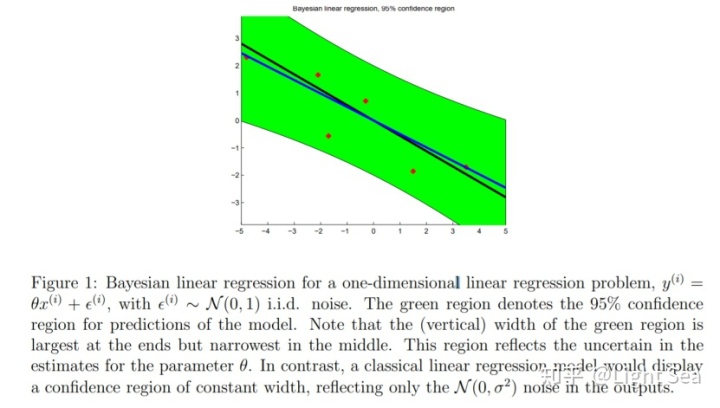
与此相对照,回忆在最简单的线性回归中我们的做法,我们对参数
“不确定性”就是两者之间最根本的区别。
3. 高斯过程
高斯过程是多元高斯分布在无限实变量集上的扩展。不同于多元高斯分布,高斯过程甚至允许我们考虑随机函数(random function)的分布。
我们这里解释一下随机函数这个概念,一般来说我们理解的随机变量的“随机”都体现在其值上,但在这里,随机函数的“随机”则体现在它的映射规则上,然而,虽然映射是随机的,但一旦我们确定了映射,则函数的值就是确定的。
3.1 有限域上的随机函数概率分布
设
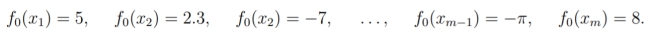
因为

这种向量表示为我们将概率分配给某个函数提供了一种渠道,我们假设:
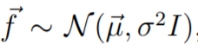
这样我们就可以得到
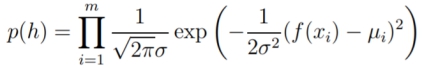
上面的例子是典型的有限定义域上随机函数的建模方法,那么无限域上怎么做呢?
3.2 无限域上的随机函数概率分布和高斯过程
所谓随机过程就是一个随机变量的集:
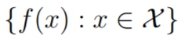
这里
我们定义高斯过程是一个随机过程,满足随机变量集合的任意有限子集都服从多元高斯分布。
为了解释这个性质,我们定义均值函数(mean function)
如果随机变量集
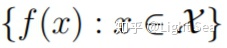
是从均值函数为
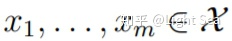
它们相对应的随机变量f(xi)服从多元高斯分布:
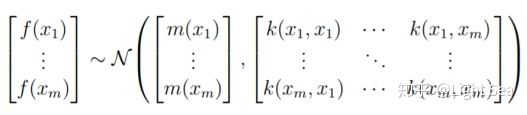
记为:
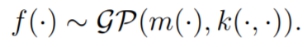
我们可以将均值函数和协方差函数理解为,对任意
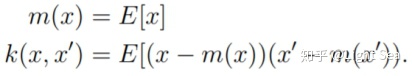
给定定义之后,我们可能会问,什么样的
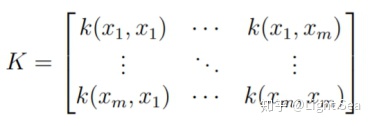
是一个多元高斯分布的协方差矩阵,因此
看到这个条件,对SVM中核函数很熟悉的同学应该懂了,这个条件其实和合法核函数的条件(Mercer条件)是等价的,因此任何合法的核函数都可以作为协方差函数
你可能已经发现,在上一节中我们利用多元高斯分布解决了有限域上的随机函数的定义问题,既然高斯过程定义在无限域上,那么我们在上一节最后提出的问题也就迎刃而解。
3.3 平方指数核
考虑零均值高斯过程(今后为了简便,称高斯过程为GP):

作为对随机函数
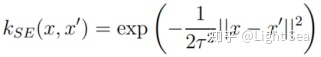
这里
这个随机函数
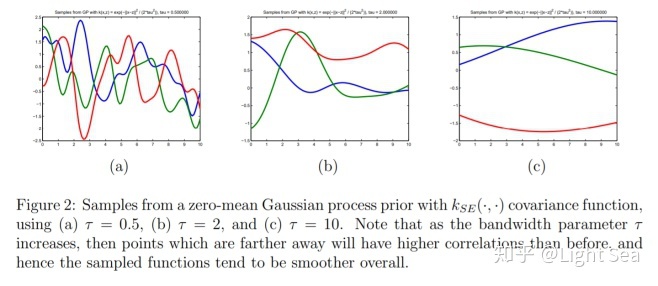
首先,我们知道任意采样点的均值为0,那么函数肯定在0附近振荡。另外,由于我们使用的是平方指数核,当采样点越近,则协方差越接近1,反之当采样点距离远,则协方差接近0.
什么意思呢?协方差为1说明点和点之间的关联性高,因此函数在局部应该是平滑的,而协方差为0说明关联性低,则振荡幅度变大。另外,超参数τ实际上控制了函数整体的平滑程度,如下图所示:
4. Gauss Process Regression
GP提供了建模无限域上随机函数的方法,这一节我们介绍如何将随机函数的概率分布的概念应用到贝叶斯回归的框架上。
4.1 模型
设
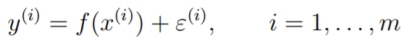
其中
和贝叶斯线性回归一样,我们需要为函数
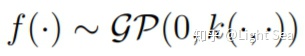
现在设
定义:
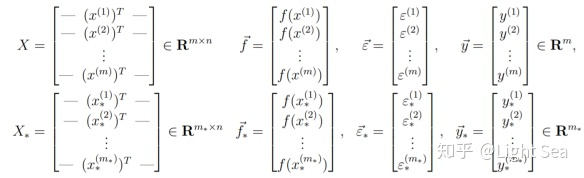
我们的任务就是计算posterior predictive distribution
4.2 预测
根据高斯过程的性质,有:
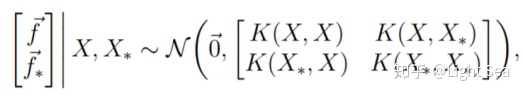
其中:
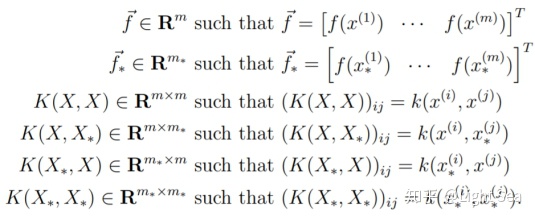
同样的,对噪声也有类似的结论:
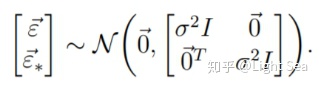
因为两个独立多元高斯变量的和还是多元高斯变量,因此有:
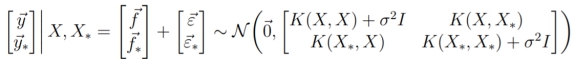
我们回忆多元高斯分布的第三个性质(conditioning),可以看出,

利用这个性质有:
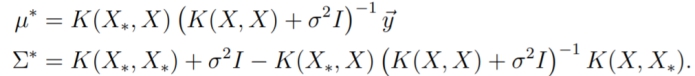
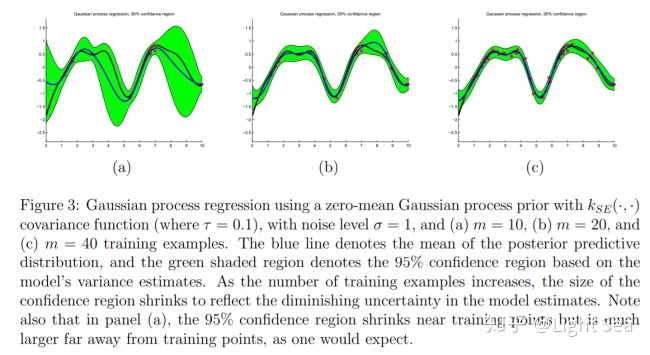
这样我们就完成了预测,几个预测的例子如下图所示:
5. 总结
GPR是一个非参数模型,它通过GP为模型赋予了更多不确定性,这也是它的优势所在;且虽然GP比较复杂,但是用于回归时却计算简单,非参数模型让它能够建模任意函数,核函数也让这个模型能利用数据的内在结构。
创作不易,求大家点赞收藏支持一下~















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









