






这里,我就主要记录一下自己在跑tensorflow框架下的faster-rcnn。
首先,就是硬件要求,这里只能做到使用一块GPU。
具体环境要求:
1.Ubuntu 16.04系统、CUDA 8.0和cudnn(可以支持NVIDIA的GPU运算,当然有很多人在说这个环境,可以再参考其他相关文章)
2.python版本opencv和gpu版本的tensorflow,自己的python版本是2.7的, 所以自己就找了2.7版本的opencv和tensorflow(必须是gpu版,因为我们要使用gpu)。
一、数据集准备
二、程序和环境编译
我的建议是大家在运行前,先理解faster-rcnn结构,然后去看它的python版本和matlab版本代码,最后在下载Faster-RCNN-TF的程序,这样会让我们在修改的时候节省很多时间,同时,也让自己的思路清晰。对于faster-rcnn-tf的程序,最主要的文件夹如下图:

data-----------------这里是用来存放你的数据图片的
experiments------这个文件夹决定了你要采用什么样的方式去训练你的数据,大家都知道,faster-rcnn提供了两种训练方式:
1.交替训练(alt_opt)
2.近似联合训练(end-to-end)
这里我们就使用的是第二种,因为它速度更快,同时也能保证准确率,但是两者修改代码是不一样的。
lib--------------------存放python的接口文件,如需要数据读入等。
tools-----------------存放的是训练、测试等python文件,这里是我们的重点。
output是用来存放自己训练好的模型的,所以在未训练前,里面是空的。我建议大家要仔细阅读README.md文件,可以很好的帮助我们运行程序。
我们现在已经有程序代码了,然后我们现在先建立Cython环境
进入终端,我们找到Faster-rcnn-TF的文件夹

点击回车,如果大家之前的软件环境都有的话,这一步会完成编译。
之后,我们需要下载一个已经训练好的模型,用来测试它的demo.py(也就是例程),这里直接用它README.md中给的网站下载就可以了,然后把模型放在tools/model(新建model文件夹)文件夹中就可以,方便我们调用。另外,这个程序是基于voc2007数据集训练的,所以它训练的是21类,测试例程的模型也是区分21类物体的。

这里,对于model模型存放的位置,大家根据自己修改,另外,对于tensorflow版本的模型来讲,它由三个文件(后缀名为data-00000-of-00001、index、meta)组成,所以大家只需要写到ckpt即可。这里我使用的是自己训练好的一个模型,所以大家凑合看即可。如果demo.py运行顺利,我们就可以训练自己的数据模型了。
三、训练
1.替换数据。大家应该提前下好voc数据集,并保存在data/VOCdevkit2007下,那么替换数据就是将自己训练集的Annotations、lmageSets和JPEGlmages文件和原文件替换即可。大家替换数据后,一定要将data/cache中的pkl文件删除,不然不会获得修改后的数据。
(1)lib/datatsets/pascal_voc.py


3. lib/networks/VGGnet_train.py (第7行)

同理,VGGnet_test.py修改同上()
4. 为了大家测试demo.py的方便,所以大家也把tools/demo.py中的类别改成自己的类别

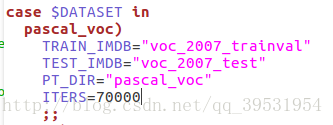
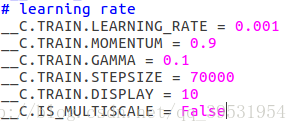
(5)修改迭代次数等参数
这里大家根据自己的计算,选择合适的迭代次数以及学习率等, 个人认为,初试学习率0.001,如果不收敛再减小一个量级,另外,70000次在gpu(看自己的gpu性能,我的是1080)上跑,也只是需要半天多的时间,所以还是可以接受的迭代次数,至于选择多少迭代次数合适,可以根据不同次数训练好的模型,测试验证。



大家需要注意一点,就是修改py文件前,大家把它对应的pyc文件删掉,修改后再重新编译一下。上面的步骤都需要重新编译一下。
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









