





点击
蓝字
?关注【
测试先锋
】,不再迷路!
一起成为互联网测试精英,前瞻测试技术~
 导语
全参考清晰度测算的时候,输入两个视频帧序列,但是视频帧序列没有对齐,怎么知道丢了哪帧?又怎么知道补回哪一帧?今天介绍一种直播视频帧的对齐方案,如果您有更好的方法,欢迎在公众号下方留言联系作者探讨交流(文章留言近期开放),再次感谢您的关注和阅读。
导语
全参考清晰度测算的时候,输入两个视频帧序列,但是视频帧序列没有对齐,怎么知道丢了哪帧?又怎么知道补回哪一帧?今天介绍一种直播视频帧的对齐方案,如果您有更好的方法,欢迎在公众号下方留言联系作者探讨交流(文章留言近期开放),再次感谢您的关注和阅读。
 1
/
问题背景
全参考测算视频质量,广泛存在在视频业务场景。
开始算法计算时,是需要仔细的对齐这一系列的帧再能做计算的,因为全参考的计算原理是根据两张相同场景的图片数据,做比较测算。仔细想想:“帧对齐”其实这是一个挺麻烦的事儿,为什么这么说?因为:
第一、帧非常多(手机端直播业务一般在 18-25fps,pc 直播业务一般 60fps),想让人工挑出到底哪帧丢了,这是非常不现实的。
1
/
问题背景
全参考测算视频质量,广泛存在在视频业务场景。
开始算法计算时,是需要仔细的对齐这一系列的帧再能做计算的,因为全参考的计算原理是根据两张相同场景的图片数据,做比较测算。仔细想想:“帧对齐”其实这是一个挺麻烦的事儿,为什么这么说?因为:
第一、帧非常多(手机端直播业务一般在 18-25fps,pc 直播业务一般 60fps),想让人工挑出到底哪帧丢了,这是非常不现实的。
 第二、由于人眼的一个重要特性——视觉惰性,表现在人眼会存在一个视觉暂留,肉眼基本看不出来连续两帧的区别。人眼可以保留 0.1-0.4秒的影像。所以每一个视频都是一个非常快的“走马灯”,人们是很难通过图像特征来区别每一帧。
第二、由于人眼的一个重要特性——视觉惰性,表现在人眼会存在一个视觉暂留,肉眼基本看不出来连续两帧的区别。人眼可以保留 0.1-0.4秒的影像。所以每一个视频都是一个非常快的“走马灯”,人们是很难通过图像特征来区别每一帧。
- 一个标记了帧号的视频文件 - 每一帧都有帧号的图片文件集 但在后面的识别图片帧号会遇到一个新的坑:你不知道需要具体需要预测的图片的坐标是多少(因为你在输入预测图片时,需要知道图片的具体 x,y,而不是整张图片输入),也就是说 个位数帧,和十位数帧,和百位数帧,具体的 x,y 都是不一样的,分别是(14,22);(28,22);(42,22) :注:以上图片部分来自互联网,如有侵权请后台联系公众号,会第一时间删除,谢谢!
导语
全参考清晰度测算的时候,输入两个视频帧序列,但是视频帧序列没有对齐,怎么知道丢了哪帧?又怎么知道补回哪一帧?今天介绍一种直播视频帧的对齐方案,如果您有更好的方法,欢迎在公众号下方留言联系作者探讨交流(文章留言近期开放),再次感谢您的关注和阅读。
1
/
问题背景
全参考测算视频质量,广泛存在在视频业务场景。
开始算法计算时,是需要仔细的对齐这一系列的帧再能做计算的,因为全参考的计算原理是根据两张相同场景的图片数据,做比较测算。仔细想想:“帧对齐”其实这是一个挺麻烦的事儿,为什么这么说?因为:
第一、帧非常多(手机端直播业务一般在 18-25fps,pc 直播业务一般 60fps),想让人工挑出到底哪帧丢了,这是非常不现实的。
第二、由于人眼的一个重要特性——视觉惰性,表现在人眼会存在一个视觉暂留,肉眼基本看不出来连续两帧的区别。人眼可以保留 0.1-0.4秒的影像。所以每一个视频都是一个非常快的“走马灯”,人们是很难通过图像特征来区别每一帧。

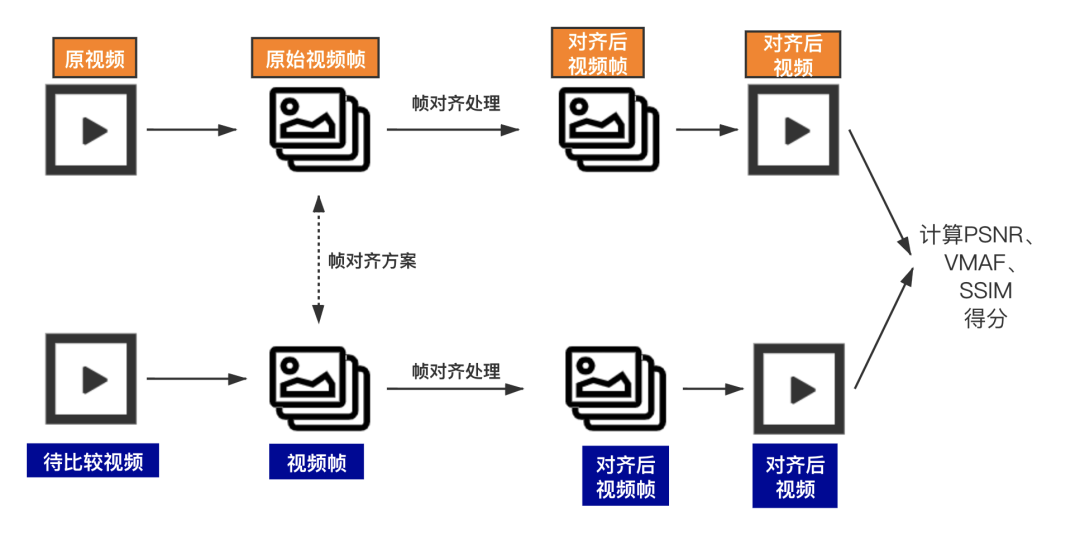
输入源为两个视频,分别是“原视频”和“待比较视频”(折损视频),首先将两个视频进行拆帧处理;将视频处理为一系列的图片帧文件,然后进行帧对齐处理(将帧的分辨率处理成一致的分辨率,将丢帧补齐,将卡帧删掉并记录帧号),输出两列对齐后的视频帧序列,再合成对齐帧后的视频序列,再进行VMAF,PSNR等全参考得分的分数计算。
了解了上述的测试方案,我们来看下每一个部分都是怎么解决的。
2 / 如何识别每一帧 识别帧的两个思路:物理识别与代码识别。 物理识别是指,放大每一帧之间的区别,或者专门打上帧的标签来识别不同的图片。 代码识别目前 笔 者 没有 找 到 比较有效的方法来区别两帧, 因为在截取为 jpg 时 这个信息已经丢失了。 所以这里还是倾向于“物理识别”方案 。 这里根据两位测试前辈(在这特别感谢 eriel,austin)曾经尝试过的经验,有两种方法: 方法一: 给每一帧标记物理序号至某一个固定位置

ffmpeg -i input.mp4 -vf drawtext=fontcolor=black:box=1:boxcolor=white:fontsize=40:fontfile=msyh.ttf:line_spacing=7:text=%{n}:x=0:y=0 -vframes 600 -y -qscale 0 out.mp4
text={n}ffmpeg -i out-1.flv -r 1 -q:v -f image2 ./result/image-%3d.jpegdef cutFrame(srcFilePath,dstFolderPath): srcFileName = srcFilePath.split('/')[-1].split('.')[0] print(srcFileName) dstFolderPath = dstFolderPath + srcFileName + '/' times=0 #提取视频的频率,每1帧提取一个 frameFrequency=1 if not os.path.exists(dstFolderPath): #如果文件目录不存在则创建目录 os.makedirs(dstFolderPath) camera = cv2.VideoCapture(srcFilePath) count = 0 while True: times+=1 res, image = camera.read() if not res: print('error ! not res , not image') break countMax = 400 if times%frameFrequency==0 and count < countMax: count+=1 print(count) cv2.imwrite(dstFolderPath + srcFileName + '-'+ str(times-1)+'.jpg', image) print(dstFolderPath + srcFileName +'-'+ str(times)+'.jpg') print('图片提取结束') camera.release()- 一个标记了帧号的视频文件 - 每一帧都有帧号的图片文件集 但在后面的识别图片帧号会遇到一个新的坑:你不知道需要具体需要预测的图片的坐标是多少(因为你在输入预测图片时,需要知道图片的具体 x,y,而不是整张图片输入),也就是说 个位数帧,和十位数帧,和百位数帧,具体的 x,y 都是不一样的,分别是(14,22);(28,22);(42,22) :



ffmpeg -i test.jpg -vf drawtext=fontcolor=black:box=1:boxcolor=white:fontsize=40:fontfile=msyh.ttf:line_spacing=7:text='00001':x=0:y=0 -vframes 600 -y -qscale 0 output.jpg text = '00001'


def frameToAvi(srcFolderPath,dstFolderPath): for root, dir, files in os.walk(srcFolderPath): count = 0 for f in files: #print(f) if not f.endwith('jpg'): continue else: count += 1 fourcc = cv2.VideoWriter_fourcc(*'XVID') videoWriter = cv2.VideoWriter(dstFolderPath+'/'+srcFolderPath.split('/')[-1]+'.avi', fourcc, 18, (1088,1920)) ## 一定要对上 宽高,不然写不进去 3506463247-106.avi for i in range(0,count): img12 = cv2.imread(root + '/' + '1-' + str(i) + '.jpg') print(root + '/' + '1-' + str(i) + '.jpg is reading') cv2.imshow('img',img12) cv2.waitKey(1) videoWriter.write(img12) print(root + '/' + '1-' + str(i) + '.jpg is succeed') videoWriter.release() print('over')videoWriter = cv2.VideoWriter(dstFolderPath+'/'+srcFolderPath.split('/')[-1]+'.avi', fourcc, 18, (1088,1920)) ## 一定要对上 fps 宽高,不然写不进去 3506463247-106.avi
















 749
749











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









