





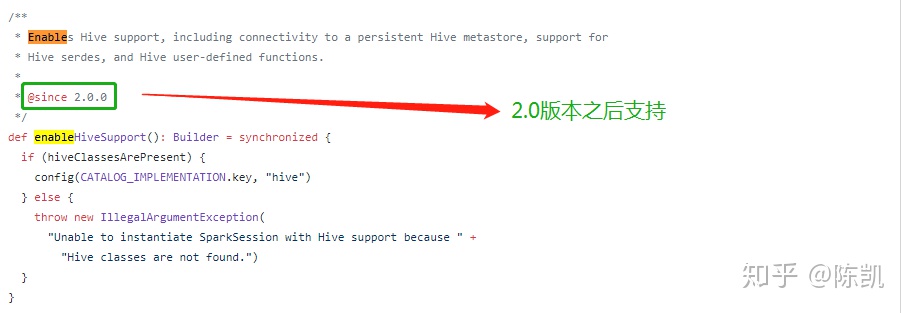
val spark= SparkSession.builder().master (”local").enableHiveSupport().getOrCreate()
spark.sq!(”CREATE TABLE IF NOT EXISTS src (key INT, value STRING )”)
spark. sql( "LOAD DATA LOCAL INPATH ’ kvl. txt' INTO TABLE src”)
spark. sql( ''SELECT * FROM src”) . show() 上面这串代码是2.0的spark版本之后预处理环境部分,enableHiveSupport则是配置信息 conf 中会将 Catalog 信息( spark.sql. cataloglmplementation )设置为“hive ”,这样在 SparkSession 根据配置信息反射获取SessionState 对象时就会得到与 Hive 相关的对象 。

再看另外一个重要概念,HiveSessionState,其实通过HiveSessionStateBuilder创建的。
生成Hive感知的`SessionState`的构建器在HiveSessionStateBuilder.scala中。

HiveSessionState会创建三个重要成员
HiveSessionCatalog;Analyzer;SparkPlanner


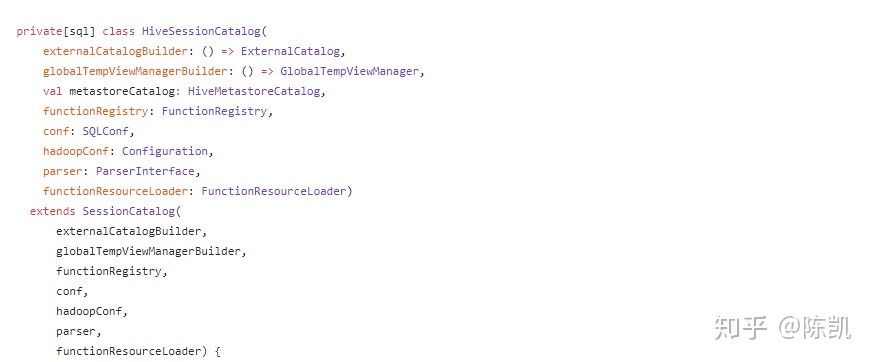
HiveSessionCatalog
HiveSessionCatalog继承SessionCatalog
SessionCatalog
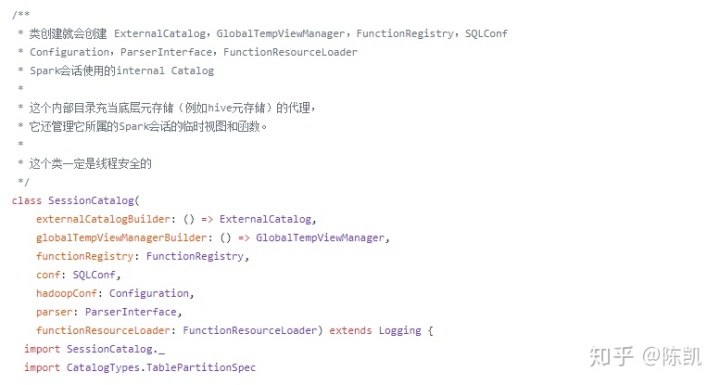
而实际操作存储数据的是ExternalCatalog类
Spark在Hive场景下,HiveSessionCatalog继承了SessionCatalog, HiveExternalCatalog则继承了ExternalCatalog。在HiveExternalCatalog中,对数据库、数据表、数据分区和注册函数等信息的读取与操作都通过HiveClient完成 。 顾名思义,Hive Client是用来与Hive进行交互的客户端,在Spark SQL中是定义了各种基本操作的接口,具体实现为HiveClientimpl 对象 。

ExternalCatalog分别从,通用层面;数据库层面;数据表层面;分区层面;方法层面。对数据存储操作




在 Spark SQL 中是定义了各种基本操作的接口,具体实现为 HiveClientimpl 对象 。 然而在实际场景中 ,因为历史遗留的原因,往往会涉及多种 Hive 版本,为了有效地支持不同版本, Spark SQL 对 HiveClient的实现由 HiveShim 通过适配 Hive 版本号( HiveVersion )来完成。Hive 版本与对应的 Shim 实现关系如下

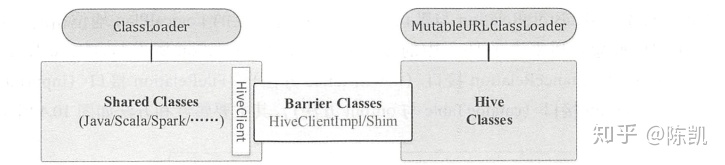
真正创建 HiveClient 的操作位于 IsolatedClientLoader 类中 。一般情况下, Spark SQL 只会通过 HiveClient 访问 Hive 中的类,为了更好地隔离, IsolatedClientLoader 将不同的类分成 3 种,不同种类的加载和访问规则各不相同 。
- 共享类( Shared classes ):包括基本的Java、 Scala 、 Logging 和 Spark 中的类,这些类通过当前上下文的 ClassLoader 加载,调用 HiveClient 返回的结果对于外部来说是可见的 。
- Hive 类( Hive classes) : 通过加载 Hive 的相关 Jar 包得到的类。 默认情况下,加载这些类的 ClassLoader 和加载共享类的 ClassLoader 并不相同,因此,无法在外部访问这些类。
- 桥梁类( Barrier classes ): 一般包括 HiveClientlmpl 与 Shim 类,在共享类与 Hive 类之间起到了桥梁的作用, Spark SQL 能够通过这个类访问 Hive 中的类 。 每个新的 HiveClientlmpl实例都对应一个特定的 Hive 版本
创建 HiveClient 的具体实现逻辑(删除了异常处理的代码)如以下代码所示。当isolationOn 为false时,直接创建一个HiveClientimpl对象并返回。代码中的classLoader为 MutableURLClassLoader 类型,可以直接通过 add URL 方法加载所需要的类 。
HiveSessionCatalog 中一个重要的方法是查找数据表( lookupRelation ) ,由于HiveSessionCatalog是继承SessionCatalog,自然继承了其对应的方法。


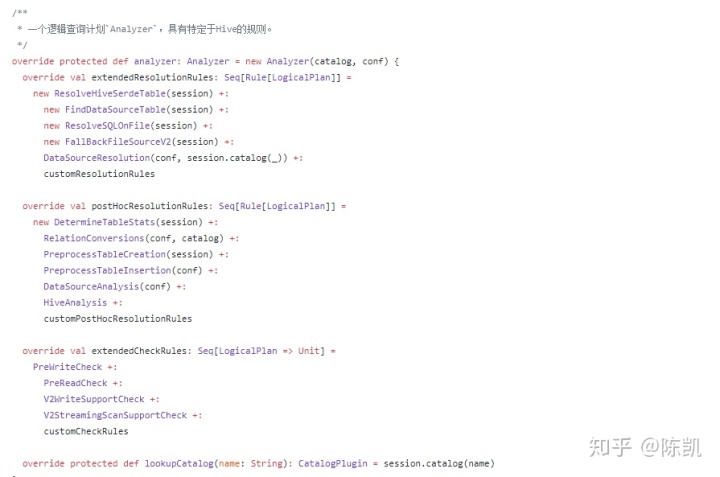
Analyzer 之 Hive-Specific 分析规则
在逻辑计划阶段,HiveSessionState中仍然会生成新的Analyzer可以看到,不同之处在于 extendedCheckRules中少了HiveOnlyCheck规则,且extendedResolutionRules中多了 ParquetConversions和OrcConversions两条规则 。在默认的Analyzer中,HiveOnlyCheck 规则会遍历逻辑算子树,如果发现 CreateTable 类型的节点且对应的 CatalogTable 是 Hive 才能够提供的,则会抛出 AnalysisException 异常,因此在Hive场景下,这条规则不再需要。
顾名思义, ParquetConversions 与 OrcConversions 用来处理 Parquet 数据表文件与 ORCFile数据表文件。在 Hive 模块中,数据表统一 用 MetastoreRelation 表示,而MetastoreRelation 包含了复杂的 partition 信息 。 当 一个查询涉及的数据表不涉及分区情况时-,为了得到更优的性能,可以将 MetastoreRelation 直接转换为数据源表 ( Data source table ) 。 具体来讲,包含两种情况。
- 读数据表,将 LogicalPlan 中所有满足条件的 MetastoreRelation 转换为 Parquet ( ORCFile) 文件格式所对应的 LogicalRelation 节点 。
- ·写数据表,即 InsertlntoTable 逻辑算子节点,同样的逻辑替换目标数据表 MetastoreRel ation为对应的 LogicalRelation 节点 。 具体的实现可以参见 convertToLogicalRelation 方法。

SparkPlanner 之 Hive-Specific 转换策略

HiveTableScans 策略与前面章节中介绍过的 FileSourceStrategy 类似,同样是匹配 Physical Operation 模式,区别在于 FileSourceStrategy 生成的物理执行计划的节点为 FileSourceScanExec ,而 Hive 中则对应 HiveTableScanExec 节点 。















 876
876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









