







今天本地spark连接远程hive集群,直接把配置导入进去,本地直接应用远程环境
1. 安装spark, 设置spark环境变量
2. 拿到远程集群配置文件, 将配置文件放在spark/conf 目录下,
*.xml 一共五个文件
3. 将mysql-connector-java-5.1.32-bin.jar 文件放入spark/jars目录下
4. 然后启动spark-shell 测试
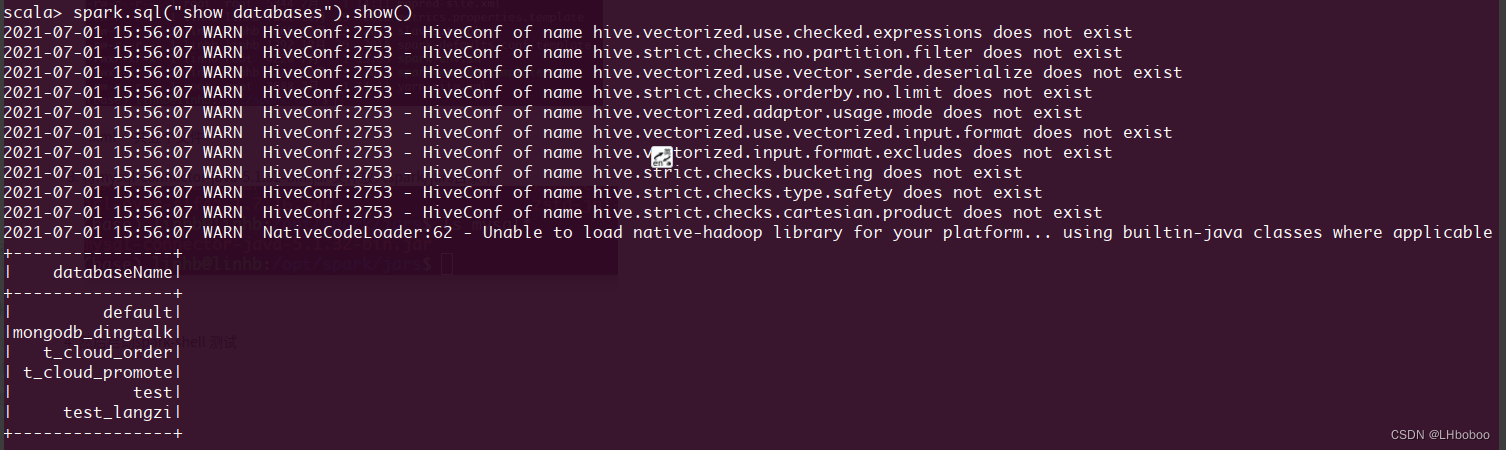
5. 然后在代码里面测试:
import findspark
findspark.init()
import os
from pyspark.sql import SparkSession
os.environ['JAVA_HOME'] = '/opt/java/jdk1.8.0_11'
spark = SparkSession.builder.master("local[*]") \
.appName("hive") \
.enableHiveSupport().getOrCreate()
spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", "true")
spark.conf.set('spark.driver.memory', '8g')
spark.conf.set('spark.executor.memory', '4g')
spark.sql("use adm_2153095")
df = spark.sql("show tables")
df.show(10)好了,配置OK















 7882
7882











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









