






一般在机器学习的模型训练之前,有一个比较重要的步骤是数据变换。
因为,一般情况下,原始数据的各个特征的值并不在一个统一的范围内,这样数据之间就没有可比性。
数据变换的目的是将不同渠道,不同量级的数据转化到统一的范围之内,方便后续的分析处理。
数据变换的方法有很多,比如数据平滑,数据聚集,数据概化,数据规范化和属性构造等。
本篇文章主要介绍数据规范化,这是一种比较常用,也比较简单的方法。
数据规范化是使属性数据按比例缩放,这样就将原来的数值映射到一个新的特定区域中,包括归一化,标准化等。
1,数据归一化
归一化就是获取原始数据的最大值和最小值,然后把原始值线性变换到 [0,1] 范围之内,变换公式为:
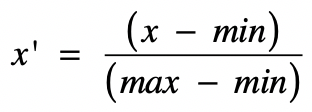
其中:
x 是当前要变换的原始值。
min 是当前特征中的最小值。
max 是当前特征中的最大值。
x' 是变换完之后的新值。
注意:min 和 max 是指当前特征中的最小最大值。
所以同一特征之内,最小最大值是一样的。
而不同特征之间,最小最大值是不一样的。
从公式中可以看出,归一化与最大最小值有关,这也是归一化的缺点,因为最大值与最小值非常容易受噪音数据的影响。
1.1,归一化处理
比如,我们有以下数据:
| 编号 | 特征1 | 特征2 | 特征3 |
| 第1条 | 5 | 465 | 135 |
| 第2条 | 23 | 378 | 69< |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 14万+
14万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









