






hxjcarrie/pyspark_studygithub.com

xgboost4j
- pyspark.ml和 pyspark.mllib中没有xgboost,需要自己打jar包
https://github.com/dmlc/xgboost/tree/master/jvm-packages
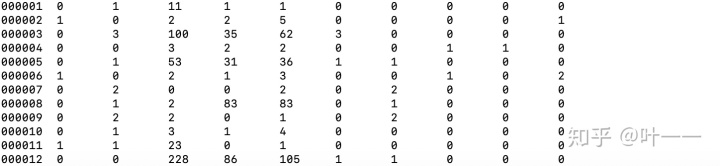
- 训练数据样例(第一列uid;第二列为label,后面为feature)
- xgbDemo.py
#!coding=utf8
'''
author: huangxiaojuan
'''
import sys
reload(sys)
sys.setdefaultencoding('utf8')
from pyspark.sql import SparkSession,Row
from pyspark.sql.types import *
from time import *
import numpy
import os
from pyspark.mllib.linalg import Vectors
from pyspark.mllib.regression import LabeledPoint
from pyspark.mllib.classification import LogisticRegressionWithLBFGS, LogisticRegressionModel
from sparkxgb import XGBoostClassifier
from pyspark.ml.feature import StringIndexer, VectorAssembler
from pyspark.ml import Pipeline
#from sparkxgb import XGBoostEstimator
from sparkxgb import XGBoostRegressor
#os.environ['PYSPARK_PYTHON'] = './python_env/py27/bin/python2'
#os.environ['PYSPARK_SUBMIT_ARGS'] = '--jars xgboost4j-spark-0.72.jar,xgboost4j-0.72.jar pyspark-shell'
def getFeatureName():
featureLst = ['feature1', 'feature2', 'feature3', 'feature4', 'feature5', 'feature6', 'feature7', 'feature8', 'feature9']
colLst = ['uid', 'label'] + featureLst
return featureLst, colLst
def parseFloat(x):
try:
rx = float(x)
except:
rx = 0.0
return rx
def parse(line):
l = line.split('t')
label = parseFloat(l[0])
features = map(lambda x: parseFloat(x), l[1:])
return LabeledPoint(label, features)
def getDict(dictDataLst, colLst):
dictData = {}
for i in range(len(colLst)):
dictData[colLst[i]] = parseFloat(dictDataLst[i])
return dictData
def main():
spark = SparkSession.builder.master("yarn").appName("spark_demo").getOrCreate()
print "Session created!"
sc = spark.sparkContext
print "The url to track the job: http://bx-namenode-02:8088/proxy/" + sc.applicationId
sampleHDFS_train = sys.argv[1]
sampleHDFS_test = sys.argv[2]
outputHDFS = sys.argv[3]
featureLst, colLst = getFeatureName()
#读取hdfs上数据,将RDD转为DataFrame
#训练数据
rdd_train = sc.textFile(sampleHDFS_train)
rowRDD_train = rdd_train.map(lambda x: getDict(x.split('t'), colLst))
trainDF = spark.createDataFrame(rowRDD_train)
#测试数据
rdd_test = sc.textFile(sampleHDFS_test)
rowRDD_test = rdd_test.map(lambda x: getDict(x.split('t'), colLst))
testDF = spark.createDataFrame(rowRDD_test)
#用于训练的特征featureLst
vectorAssembler = VectorAssembler().setInputCols(featureLst).setOutputCol("features")
## 训练
print "step 1"
xgboost = XGBoostRegressor(featuresCol="features", labelCol="label", predictionCol="prediction",
numRound=50, colsampleBylevel=0.7, trainTestRatio=0.9,
subsample=0.7, seed=123, missing = 0.0, evalMetric="rmse")
pipeline = Pipeline(stages=[vectorAssembler, xgboost])
model = pipeline.fit(trainDF)
## 预测, 保存结果
print "step 2"
labelsAndPreds = model.transform(testDF).select("uid", "label", "prediction")
labelsAndPreds.write.mode("overwrite").options(header="true").csv(outputHDFS + "/target/output")
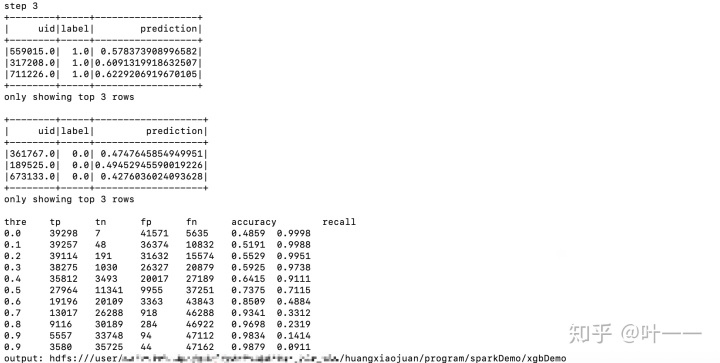
print "step 3"
# 评估不同阈值下的准确率、召回率
labelsAndPreds_label_1 = labelsAndPreds.where(labelsAndPreds.label == 1)
labelsAndPreds_label_0 = labelsAndPreds.where(labelsAndPreds.label == 0)
labelsAndPreds_label_1.show(3)
labelsAndPreds_label_0.show(3)
t_cnt = labelsAndPreds_label_1.count()
f_cnt = labelsAndPreds_label_0.count()
print "threttpttntfptfntaccuracytrecall"
for thre in [0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 0.95]:
tp = labelsAndPreds_label_1.where(labelsAndPreds_label_1.prediction > thre).count()
tn = t_cnt - tp
fp = labelsAndPreds_label_0.where(labelsAndPreds_label_0.prediction > thre).count()
fn = f_cnt - fp
print("%.1ft%dt%dt%dt%dt%.4ft%.4f"%(thre, tp, tn, fp, fn, float(tp)/(tp+fp), float(tp)/(t_cnt)))
# 保存模型
model.write().overwrite().save(outputHDFS + "/target/model/xgbModel")
#加载模型
#model.load(outputHDFS + "/target/model/xgbModel")
print "output:", outputHDFS
if __name__ == '__main__':
main()
日志打印模型效果:
- spark-submit_xgb.sh
#ModelType=lrDemo
ModelType=xgbDemo
CUR_PATH=$(cd "$(dirname "$0")";pwd)
echo $CUR_PATH
SPARK_PATH=/user/spark/spark
YARN_QUEUE=
DEPLOY_MODE=cluster
DEPLOY_MODE=client
input_path_train=hdfs:///user/huangxiaojuan/program/sparkDemo/input/train
input_path_test=hdfs:///user/huangxiaojuan/program/sparkDemo/input/test
output_path=hdfs:///user/huangxiaojuan/program/sparkDemo/${ModelType}
hadoop fs -rmr $output_path
${SPARK_PATH}/bin/spark-submit
--master yarn
--queue ${YARN_QUEUE}
--deploy-mode ${DEPLOY_MODE}
--driver-memory 6g
--driver-cores 4
--executor-memory 12g
--executor-cores 15
--num-executors 10
--archives ./source/py27.zip#python_env
--py-files ./pyspark-xgboost/sparkxgb.zip
--jars ./pyspark-xgboost/xgboost4j-spark-0.90.jar,./pyspark-xgboost/xgboost4j-0.90.jar
--conf spark.default.parallelism=150
--conf spark.executor.memoryOverhead=4g
--conf spark.driver.memoryOverhead=2g
--conf spark.yarn.maxAppAttempts=3
--conf spark.yarn.submit.waitAppCompletion=true
--conf spark.pyspark.driver.python=./source/py27/bin/python2
--conf spark.yarn.appMasterEnv.PYSPARK_PYTHON=./python_env/py27/bin/python2
--conf spark.pyspark.python=./python_env/py27/bin/python2
./${ModelType}.py $input_path_train $input_path_test $output_path- 由于pyspark.ml和 pyspark.mllib中没有xgboost,需要自己打包jar并上传
--py-files ./pyspark-xgboost/sparkxgb.zip
--jars ./pyspark-xgboost/xgboost4j-spark-0.90.jar,./pyspark-xgboost/xgboost4j-0.90.jar - 使用client模式 需要保证driver和executor上的python版本一致
- 若executor上的python不满足要求,可通过如下参数上传打包好的python到executor上
#上传python包到executor
--archives ./source/py27.zip
#指定executor上python路径
--conf spark.yarn.appMasterEnv.PYSPARK_PYTHON=./python_env/py27/bin/python2
--conf spark.pyspark.python=./python_env/py27/bin/python2
#指定driver上python路径
--conf spark.pyspark.driver.python=./source/py27/bin/python2
#或者先上传至hdfs
--conf spark.yarn.dist.archives=hdfs://user/huangxiaojuan/py27.zip#python_env













 4561
4561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









