






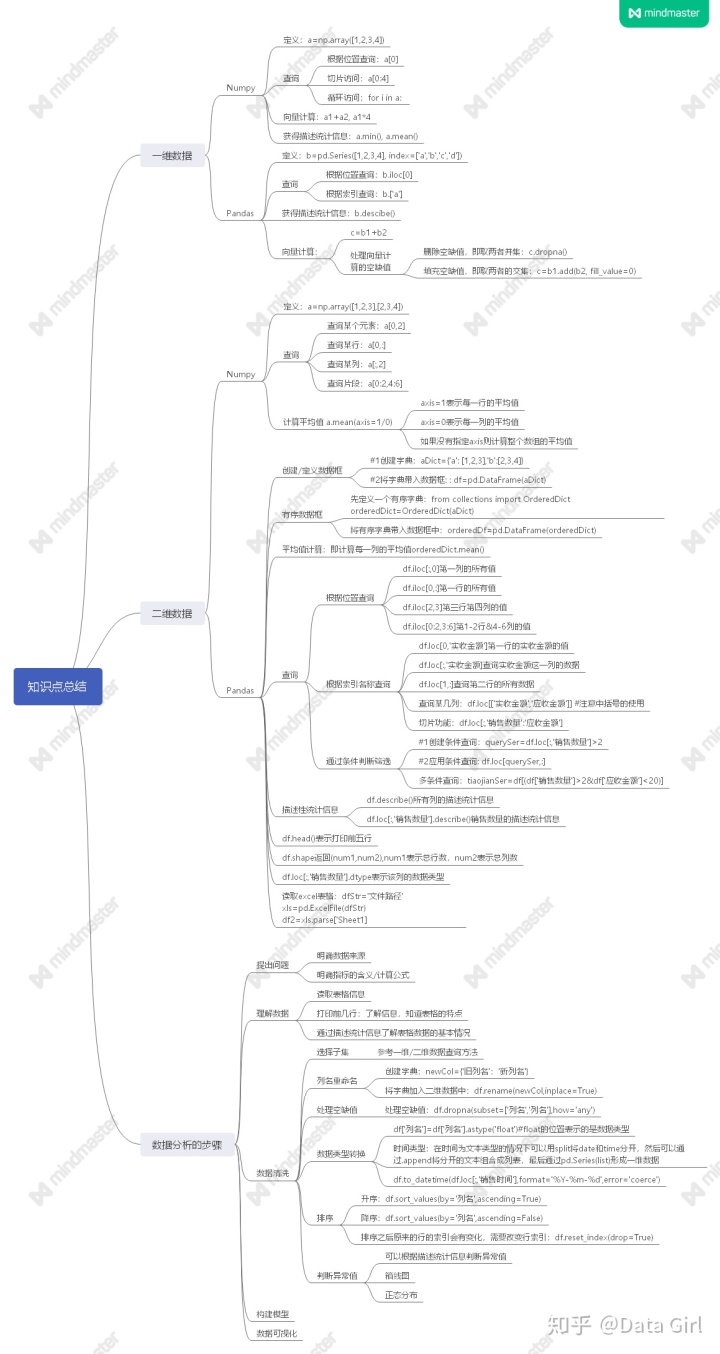
知识点概括
一、一维数据分析
- Pandas包:一维数据用Series表示,建立在Numpy的基础上,并且使用的功能更多
- Numpy包:一维数据用Array表示,和列表类似
1. Numpy一维数据结构array
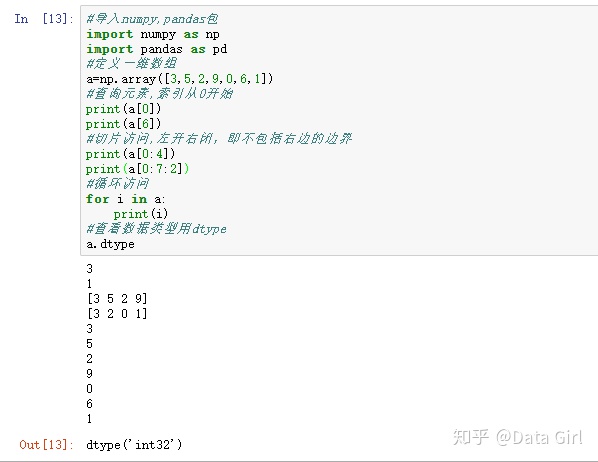
Numpy的 array和列表(List)的区别:
- 一维数组有统计功能(e.g.平均值等)
- 可以向量化计算
- 一维数组中的元素必须是同一种数据类型,列表可以是不同数据类型
- 可以通过.min()/.max()/.mean()/.std()获取描述性统计信息
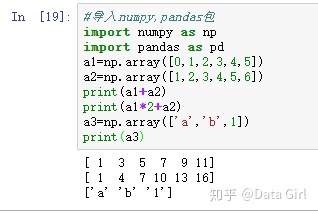
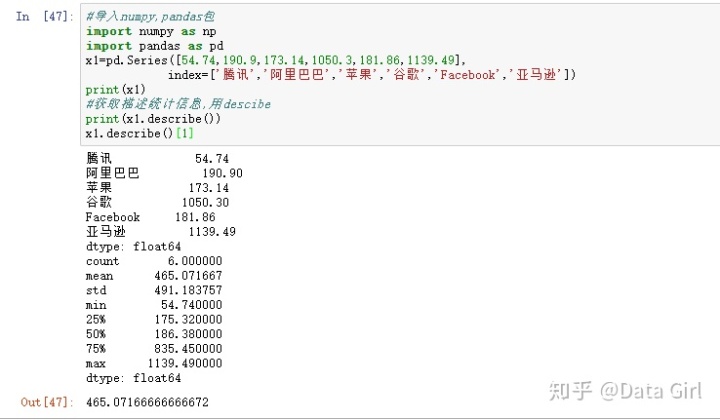
2. Pandas的一维数据结构Series
与numpy的array区别:pandas有指定索引
- 用descibe显示描述统计信息
- 用iloc属性用于根据位置获取值
- 用loc属性根据索引获取值
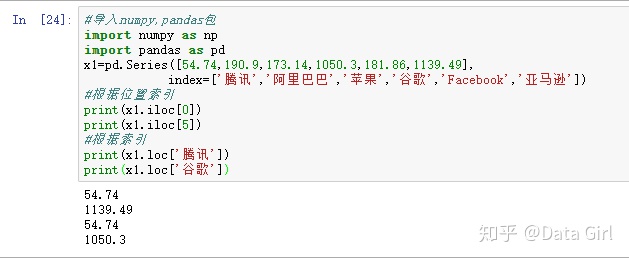
- 支持向量运算
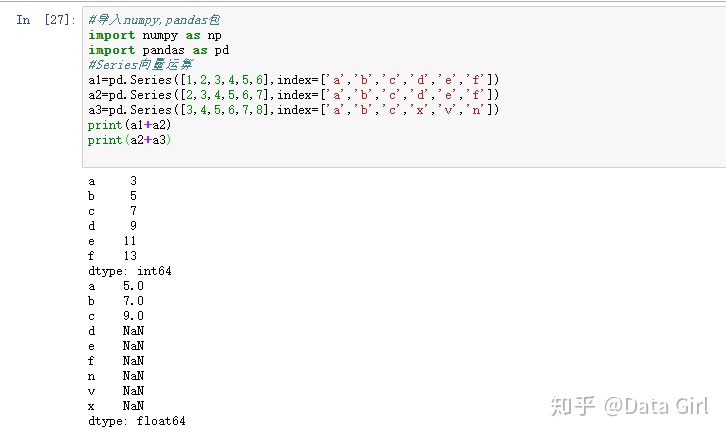
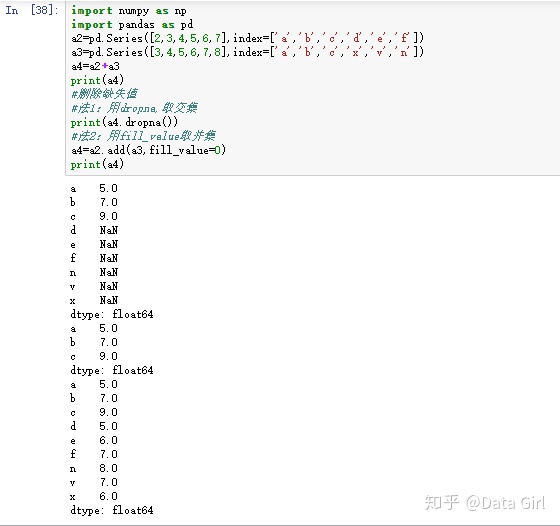
pd.Series删除空缺值
- 法1:用dropna,删除空集,类似于去两个一维数组的交集
- 法2:用fill_value,合并两个集合中不能匹配的部分,类似于取并集
二、二维数据结构
既有行又有列,类似于excel中的二维表格
- numpy中用array创建二维数组
- pandas中用dataframe创建数组
1. Numpy的array
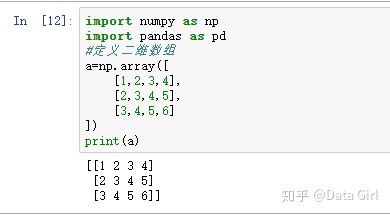
numpy的array中,每一个列表代表一行,将整个数组用中括号括起来
查询元素
- 查询某个元素:a[0:2]表示查询第一行第三列,二维数组中行列都是从0开始索引的
- 查询某行所有数据:a[0:]表示获取第一行所以数据
- 查询某列所有数据:a[:2]表示查询第三列的所有数据

计算平均值
- axis=1表示计算每一行的平均值;
- axis=0表示计算每一列的平均值;
- 如果没有指定,则计算整个数组的平均值;

2. Pandas数据框(Dataframe)
Pandas数据框(Dataframe)的优点:有索引值;每一列可以是不同类型的数据;
创建数据框的步骤:
- 第一步:创建字典(用{})
- 第二步:将创建的字典导入pd.DataFrame()中
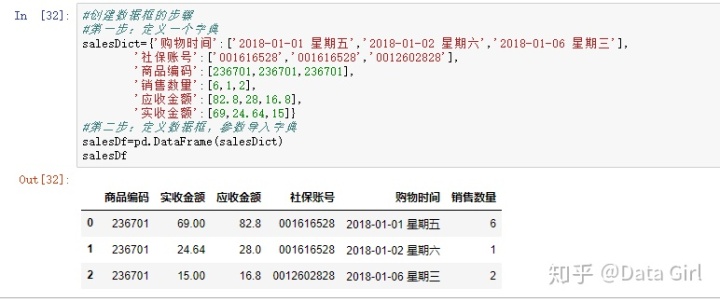
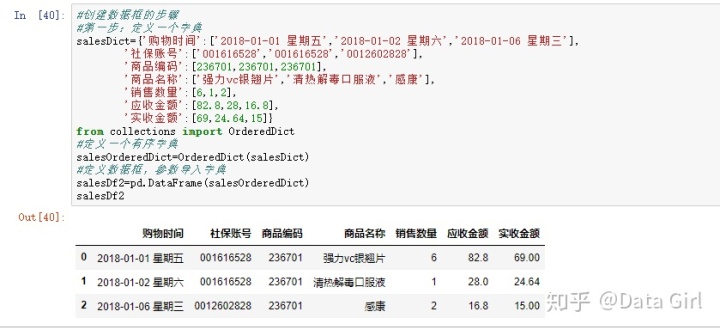
有序的数据框:需要引入collections
平均值计算
用.mean是求每一列的平均值,前提是整数/浮点型

查询
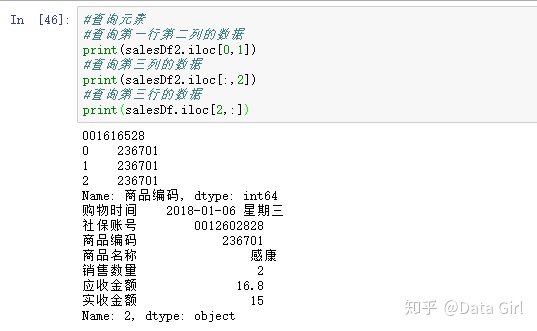
方法1:根据位置索引用iloc(逗号将行和列的范围分开)
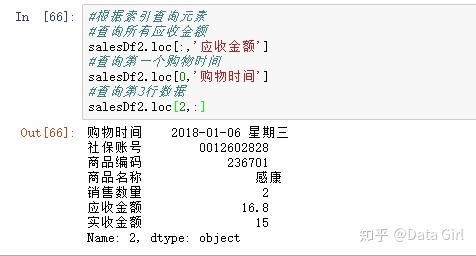
方法2:根据索引查询数据用loc,行:只能用数字/冒号,列:只能用列名索引/冒号
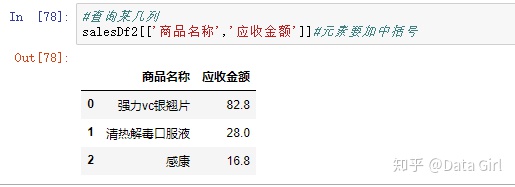
查询某几列:不需要loc属性,需要在元素范围加上中括号
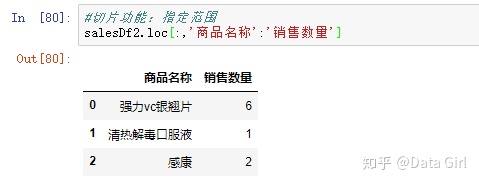
切片功能:指定范围
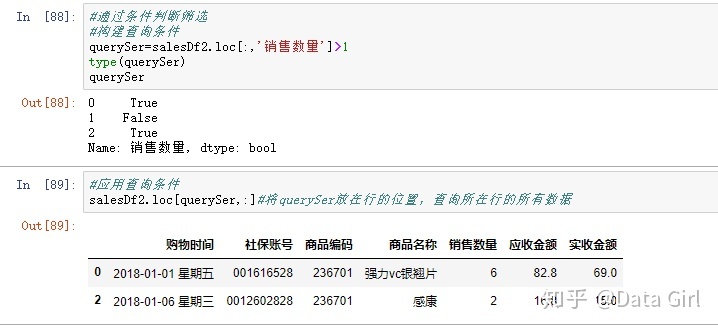
通过条件判断筛选
- 构建条件查询
- 应用查询条件
多条件查询

数据集描述统计信息
三、数据分析的步骤
- 提出问题
- 理解数据
- 数据清洗
- 构建模型
- 数据可视化
1. 提出问题
- 明确数据来源
- 明确指标的含义/计算公式
2. 理解数据
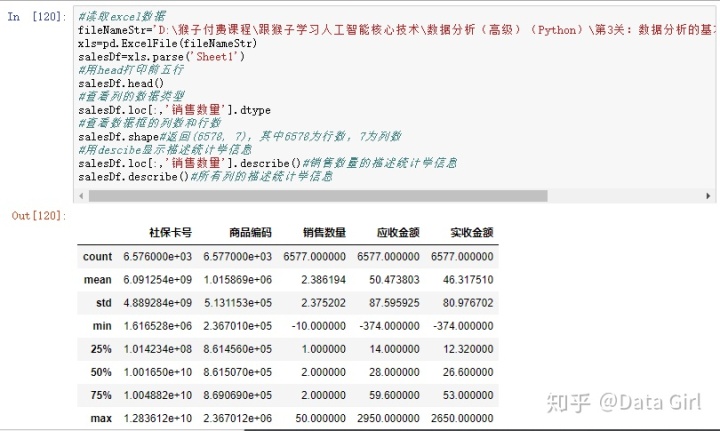
- 读取EXCEL数据,
- 打印前几行: 了解信息,知道表格的特点。
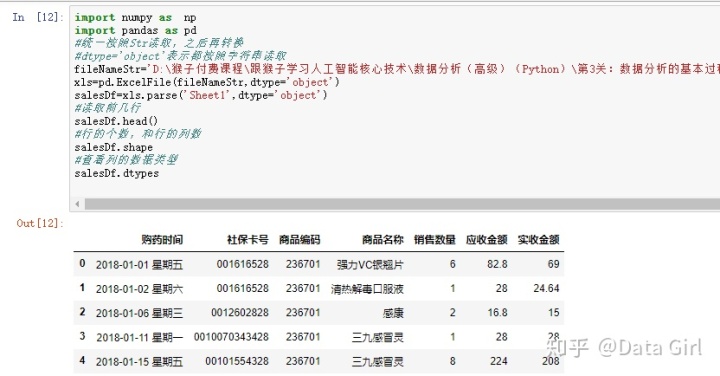
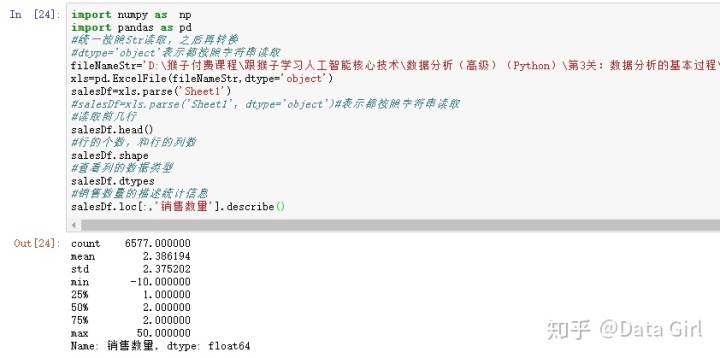
从销售数量描述统计信息中发现:
- 最小值出现负数,为异常值;
- 平均数为2.386194,中位数为2,上四分位数为2,下四分位数为1,最大值为50为异常值;
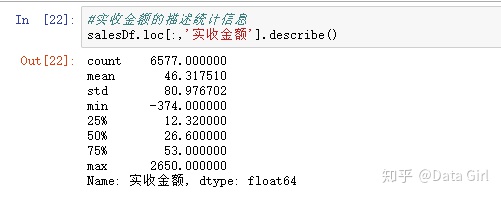
从应收金额和实收金额描述统计信息中发现:
- 最小值为负数,为异常值;
- 卖出商品数量一致,两者的平均值有出入,应收金额平均值比实收金额平均值大;
- 两者的平均值都比各自的中位数大,说明在卖出的6577个商品中,价格高的商品比例较高;
3. 数据清洗
- 选择子集
- 列名重命名
- 缺失数据处理
- 数据类型转换
- 数据排序
- 异常值处理
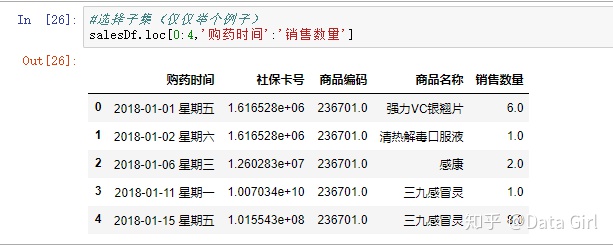
选择子集
比如用切片功能选择指定的范围
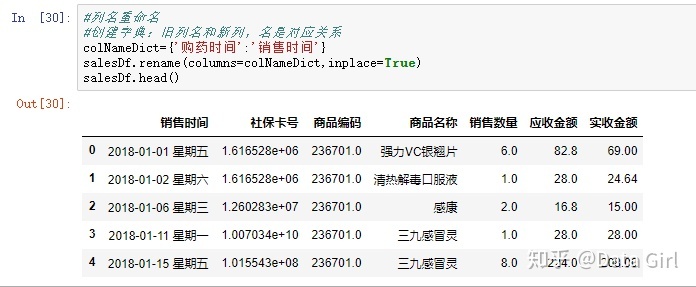
列名重命名
- 可以用.rename将列名重新命名:salesDf.rename(columns=newcolumns,inplace=True/False)
- 当inplace为True原始的数据框会变动,如果为False表示原始的数据框不会变动,会创建出新的数据框;
缺失数据处理
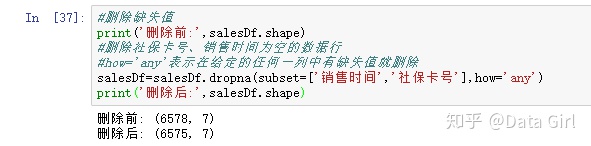
处理缺失值的方法:
- 建立模型填补缺失值
- 直接删除缺失值:可以用.dropna(subset=[].how='any),其中subset是用于存放指定列的列表,how='any'表示如何删除空缺值,any表示在给定任何一列中有缺失值就删除
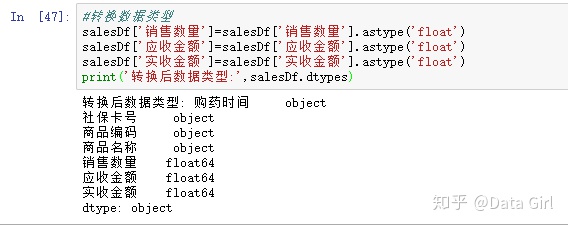
数据类型转换
用.astype('数据类型')
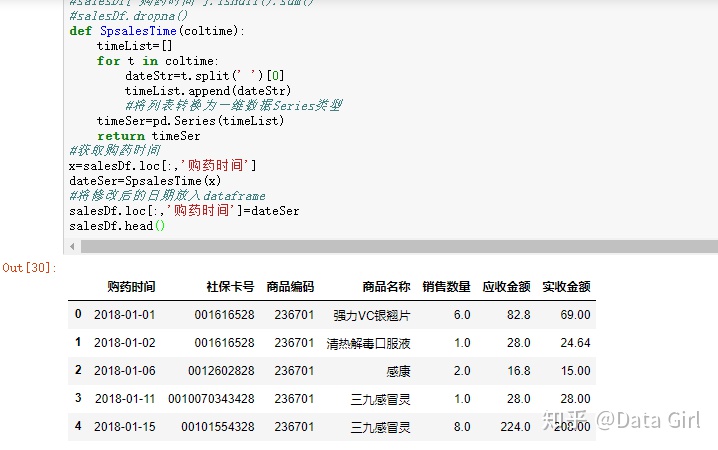
处理日期/时间
- 用.split将字符串类型的时间和日期分割
- 输入:coltime是Series数据类型
- 输出:分割后的时间,返回也是个Series数据类型
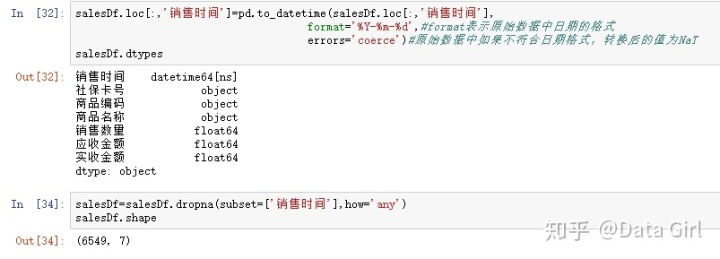
字符串转日期格式
- 用to_datetime[定位列,format=日期形式,errors='coerce]
- format表示原始数据中日期的格式
- 原始数据中如果不符合日期格式,转换后的值为NaT
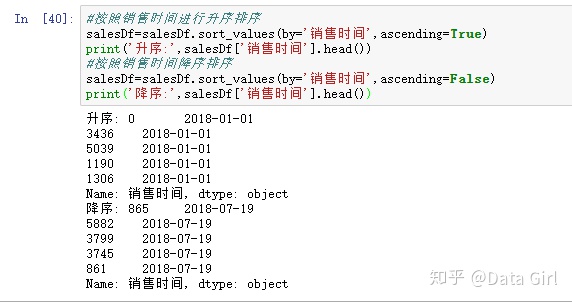
排序
- 用sort_values()
- by表示按哪一列进行排序
- ascending=True表示升序
- ascending=False表示降序
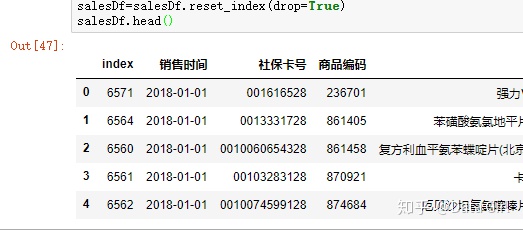
排序后行号依旧是原行号,因此可以重命名行名
四、案例
1. 业务指标
月均消费次数,即总消费次数/月份数,同一天内同一个人发生的所有消费算做一次消费
计算总消费次数:

月均消费金额,即为总消费金额/月份数
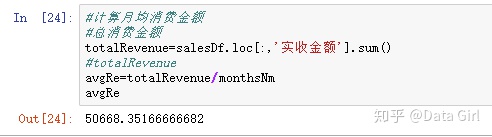
客单价:每一位顾客消费的金额















 2858
2858











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









