






最初的条件随机场论文发表于本世纪初,从那时起,机器学习社区开始将CRF应用于各个领域,从生物序列、计算机视觉到自然语言处理。
在过去几年中,CRF模型与LSTM结合使用,获得了新的结果。在NLP社区中,这被认为是序列标记的经验法则:如果你想要更高的准确性,只需将一个CRF堆叠在你的LSTM层之上。
在序列分类问题中,最终目标是在给定序列向量(X)的输入的情况下找到序列标签(y)的概率。这被表示为P(y|x)。
首先,让我们定义符号:
- 训练集:输入和目标序列对{(X i,y i)}
- 第i个输入向量序列:ξ=(x1,…,xℓ)
- 第i个标签序列:yi = [y1, …, yℓ]
- ℓ是序列长度。
对于样本(X,y),在常规分类问题中,我们通过乘以序列中第k个位置的每个项目的概率来计算P(y | X),其中1≤k≤ℓ:
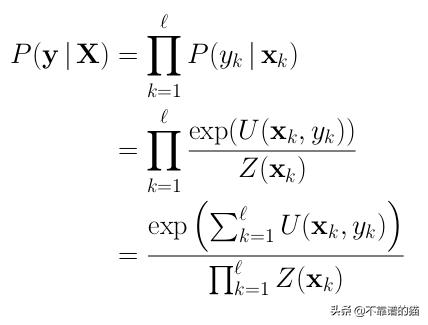
我们用归一化指数来建模P(yk | xk)这类似于在神经网络中广泛使用的softmax操作。以下是我们使用exp的一些直觉:
- 下溢:当我们用非常小的数字,我们得到一个较小的数量可能遭受下溢。
- 非负输出:所有值都映射在0和+inf之间。
- 单调增加:这与argmax操作具有类似的效果。
U(x,y) 被称为我们的emissions或一元分数(unary scores)。它只是在第k个时间步给出x向量的标签y的分数。您可以将其视为LSTM的第k个输出。理论上,x向量可以是你想要的任何向量。实际上,我们的x向量通常是周围元素的连接,比如滑动窗口中的单词嵌入。在我们的模型中,每一个一元因子都由一个可学习的权重来加权。如果我们将它们视为LSTM输出,这很容易理解。
Z(x) 通常称为配分函数(partition function)。我们可以将其视为归一化因子,因为我们想获得概率:每个不同标签的分数应该总和为1.您可以将其视为softmax函数的分母。
到目前为止,我们描述了一个常规分类模型,最后使用softmax激活以获得概率。 现在我们将添加新的可学习权重来模拟标签yk跟随yk + 1的可能性。 通过对此进行建模,我们在连续标签之间创建依赖关系!叫做线性链CRF!为了做到这一点,我们将我们先前的概率乘以P(yk + 1 | yk),我们可以使用指数属性将其重写为unary scores U(x,y)加上可学习的transition scores T(y,y):
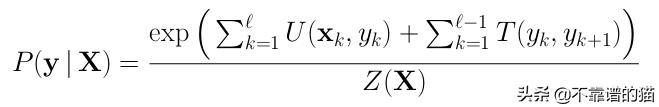
T(y, y)是一个具有形状(nb_tags, nb_tags)的矩阵,其中每个条目都是一个可学习的参数,表示从第i个标签到第j个标签的转换。让我们回顾一下所有的新变量
- emissions或unary scores(U):表示给定输入x k的yk可能性的分数。
- transition scores(T):表示yk跟随yk + 1的可能性的分数
- partition function(Z):归一化因子,以便在结束时获得概率。
唯一需要正确定义的是配分函数Z:
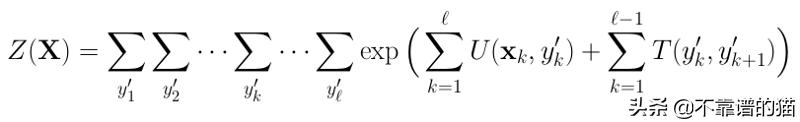
事实证明,计算Z(X)并非易事,因为我们有太多的嵌套循环!它是每个时间步标签集上所有可能组合的总和。更确切地说,我们对标签集进行了ℓ!计算。这给了我们时间复杂度O(ℓ!| y |²)。
幸运的是,我们可以利用循环依赖关系并使用动态编程来有效地计算它!执行此操作的算法称为前向算法或后向算法 - 取决于您在序列上迭代的顺序。
Python编码
让我们通过创建一个名为CRF的类来启动我们的代码,该类继承自pytorch的nn.Module,以便自动跟踪我们的梯度。
import torchfrom torch import nnclass CRF(nn.Module): """ Linear-chain Conditional Random Field (CRF). Args: nb_labels (int): number of labels in your tagset, including special symbols. bos_tag_id (int): integer representing the beginning of sentence symbol in your tagset. eos_tag_id (int): integer representing the end of sentence symbol in your tagset. batch_first (bool): Whether the first dimension represents the batch dimension. """ def __init__( self, nb_labels, bos_tag_id, eos_tag_id, batch_first=True ): super().__init__() self.nb_labels = nb_labels self.BOS_TAG_ID = bos_tag_id self.EOS_TAG_ID = eos_tag_id self.batch_first = batch_first self.transitions = nn.Parameter(torch.empty(self.nb_labels, self.nb_labels)) self.init_weights() def init_weights(self): # initialize transitions from a random uniform distribution between -0.1 and 0.1 nn.init.uniform_(self.transitions, -0.1, 0.1) # enforce contraints (rows=from, columns=to) with a big negative number # so exp(-10000) will tend to zero # no transitions allowed to the beginning of sentence self.transitions.data[:, self.BOS_TAG_ID] = -10000.0 # no transition alloed from the end of sentence self.transitions.data[self.EOS_TAG_ID, :] = -10000.0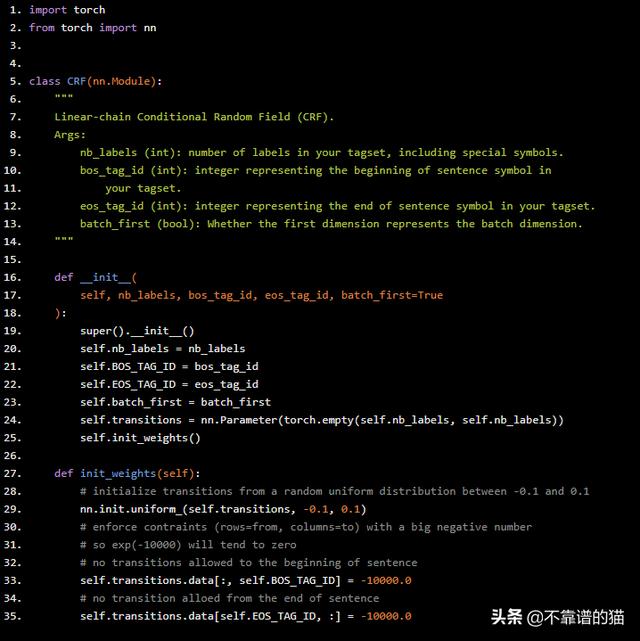
我们也可以为pad id添加一个特殊标记。如果我们这样做,我们必须确保强制执行约束以防止transitions from padding和transitions to padding的转换- 除非我们已经处于pad位置。我们可以看到我们的transitions scores T被表示为矩阵self.transitions,这是PyTorch将使用反向传播学习的torch.parameter!
定义损失函数
在分类问题中,我们希望最小化训练过程中的误差。我们可以通过定义一个损失函数L来实现这一点,这个函数将我们的预测和真实标签作为输入,如果它们相等,则返回零;如果它们不同,则返回正数,这表明出现了误差。
请注意,我们正在计算P(y | X),这是我们想要最大化的。为了将其构建为最小化问题,我们采用该概率的负对数。这也被称为负对数似然损失(NLL-Loss)。我们得到:L = - log(P(y | X))。并应用log-properties,如log(a / b)= log(a) - log(b),我们得到:
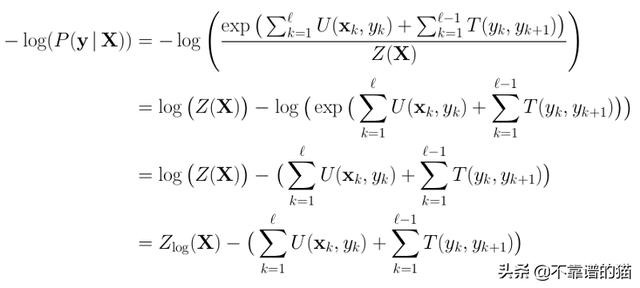
其中Z_log表示我们在计算配分函数期间获取log。让我们看看Python代码:
def forward(self, emissions, tags, mask=None): """Compute the negative log-likelihood. See `log_likelihood` method.""" nll = -self.log_likelihood(emissions, tags, mask=mask) return nlldef log_likelihood(self, emissions, tags, mask=None): """Compute the probability of a sequence of tags given a sequence of emissions scores. Args: emissions (torch.Tensor): Sequence of emissions for each label. Shape of (batch_size, seq_len, nb_labels) if batch_first is True, (seq_len, batch_size, nb_labels) otherwise. tags (torch.LongTensor): Sequence of labels. Shape of (batch_size, seq_len) if batch_first is True, (seq_len, batch_size) otherwise. mask (torch.FloatTensor, optional): Tensor representing valid positions. If None, all positions are considered valid. Shape of (batch_size, seq_len) if batch_first is True, (seq_len, batch_size) otherwise. Returns: torch.Tensor: the log-likelihoods for each sequence in the batch. Shape of (batch_size,) """ # fix tensors order by setting batch as the first dimension if not self.batch_first: emissions = emissions.transpose(0, 1) tags = tags.transpose(0, 1) if mask is None: mask = torch.ones(emissions.shape[:2], dtype=torch.float) scores = self._compute_scores(emissions, tags, mask=mask) partition = self._compute_log_partition(emissions, mask=mask) return torch.sum(scores - partition)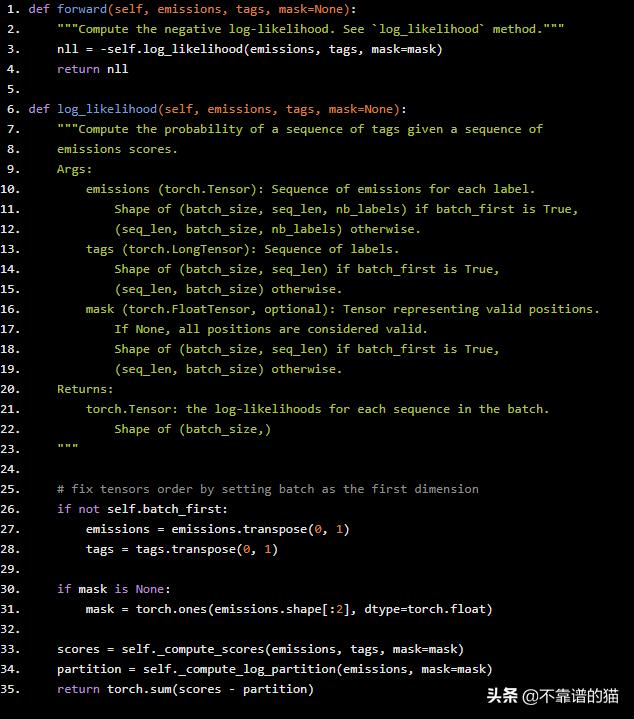
我们的forward pass只是NLL损失(不要将它与前向算法混淆),其中我们在常规log_likelihood方法前面插入减号。该log_likelihood通过首先计算所述scores和log partition的方法,然后再互相减去。此外,我们将mask矩阵传递给这些方法,以便它们可以忽略与pad符号相关的计算。为完整起见,mask矩阵看起来像:
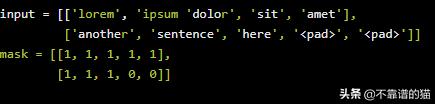
计算分子:scores
因为我们对exp应用了log,分子就是每个时间步的emission和transition scores的总和!
def _compute_scores(self, emissions, tags, mask): """Compute the scores for a given batch of emissions with their tags. Args: emissions (torch.Tensor): (batch_size, seq_len, nb_labels) tags (Torch.LongTensor): (batch_size, seq_len) mask (Torch.FloatTensor): (batch_size, seq_len) Returns: torch.Tensor: Scores for each batch. Shape of (batch_size,) """ batch_size, seq_length = tags.shape scores = torch.zeros(batch_size) # save first and last tags to be used later first_tags = tags[:, 0] last_valid_idx = mask.int().sum(1) - 1 last_tags = tags.gather(1, last_valid_idx.unsqueeze(1)).squeeze() # add the transition from BOS to the first tags for each batch t_scores = self.transitions[self.BOS_TAG_ID, first_tags] # add the [unary] emission scores for the first tags for each batch # for all batches, the first word, see the correspondent emissions # for the first tags (which is a list of ids): # emissions[:, 0, [tag_1, tag_2, ..., tag_nblabels]] e_scores = emissions[:, 0].gather(1, first_tags.unsqueeze(1)).squeeze() # the scores for a word is just the sum of both scores scores += e_scores + t_scores # now lets do this for each remaining word for i in range(1, seq_length): # we could: iterate over batches, check if we reached a mask symbol # and stop the iteration, but vecotrizing is faster due to gpu, # so instead we perform an element-wise multiplication is_valid = mask[:, i] previous_tags = tags[:, i - 1] current_tags = tags[:, i] # calculate emission and transition scores as we did before e_scores = emissions[:, i].gather(1, current_tags.unsqueeze(1)).squeeze() t_scores = self.transitions[previous_tags, current_tags] # apply the mask e_scores = e_scores * is_valid t_scores = t_scores * is_valid scores += e_scores + t_scores # add the transition from the end tag to the EOS tag for each batch scores += self.transitions[last_tags, self.EOS_TAG_ID] return scores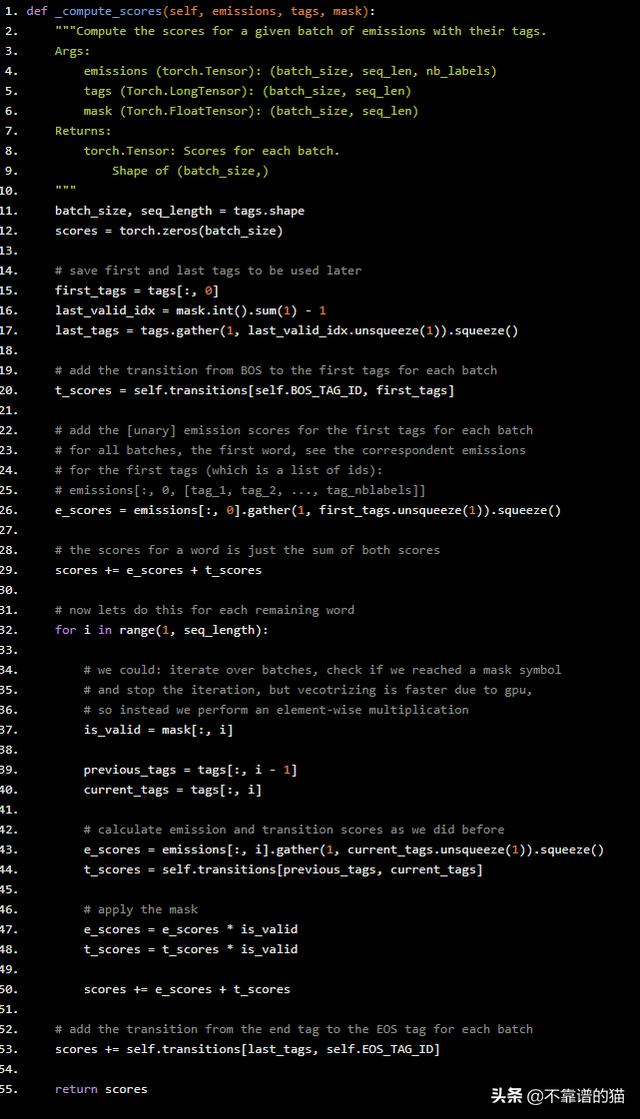
为了理解这段代码,你必须认为batch中每个句子的所有操作都是相同的。我们首先通过调用tags[:, 0]获取每个batch中第一个单词的标记。类似地,我们对时间步长维度上的mask求和,以得到长度列表,对于上一个示例,长度列表是[5,3]。在实践中,它返回一个torch.LongTensor。。例如,让我们看看第26行:
emissions[:, 0].gather(1, first_tags.unsqueeze(1)).squeeze()- 首先,我们从第一个时间步中选择所有批次:emissions[:, 0],它返回一个具有形状(batch_size, nb_tags)的张量。
- 然后我们只想选择LongTensor first_tags中具有形状(batch_size,)的列(dim = 1)中的值。 由于emissions是一个2D矩阵,我们解压缩first_tags的最后一个维度来获得形状(batch_size,1):first_tags.unsqueeze(1)
- 现在它们具有相同的形状,我们可以使用gather函数来选择first_tags指定维度内的值emissions:emissions[:, 0].gather(1, first_tags.unsqueeze(1))
- 最后,这会得到一个形状为(batch_size, 1)的矩阵,所以我们把它squeeze得到一个1D LongTensor。
在整个代码中使用这个简单的过程在指定的维度中选择一组标签。
我想谈谈这段代码的最后一件事是我们如何忽略与padding符号相关的分数。解决这个问题的想法很简单:我们在两个向量之间执行逐元素乘法,以将时间步已经处于pad位置的新分数归零。
计算配分函数:前向算法
现在我们计算了我们的分数,让我们关注我们的分母。为了有效地计算配分函数,我们使用前向算法。我将简要描述它并展示我们如何在 log-space中计算它。
前向算法的伪代码如下:
1)初始化,对于y'2的所有值:
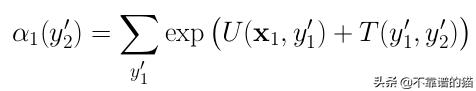
2)For k=2 to ℓ-1,对于y'k + 1(log-space)的所有值:
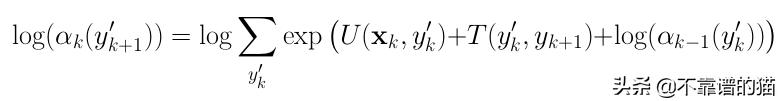
3)最后:
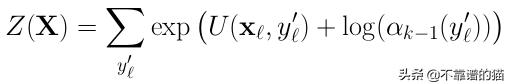
注意,在第二步中,我们对exp求和取对数。这可能是有问题的。如果给定标签y 'k的数太大,那么该指数将快速增长到一个非常大的数字!在最后做log之前,我们可能会发现一个溢出问题。幸运的是,有一个技巧可以让这个操作变得稳定:
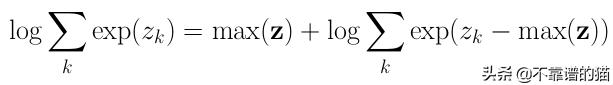
左边等于右边的证明是这样的:
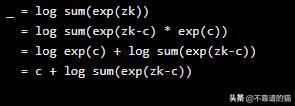
将c设置为max(z),我们就完成了。此外,PyTorch已经为我们提供了这种稳定的实现方式torch.logsumexp。现在让我们使用PyTorch对上面的算法进行编码:
def _compute_log_partition(self, emissions, mask): """Compute the partition function in log-space using the forward-algorithm. Args: emissions (torch.Tensor): (batch_size, seq_len, nb_labels) mask (Torch.FloatTensor): (batch_size, seq_len) Returns: torch.Tensor: the partition scores for each batch. Shape of (batch_size,) """ batch_size, seq_length, nb_labels = emissions.shape # in the first iteration, BOS will have all the scores alphas = self.transitions[self.BOS_TAG_ID, :].unsqueeze(0) + emissions[:, 0] for i in range(1, seq_length): alpha_t = [] for tag in range(nb_labels): # get the emission for the current tag e_scores = emissions[:, i, tag] # broadcast emission to all labels # since it will be the same for all previous tags # (bs, nb_labels) e_scores = e_scores.unsqueeze(1) # transitions from something to our tag t_scores = self.transitions[:, tag] # broadcast the transition scores to all batches # (bs, nb_labels) t_scores = t_scores.unsqueeze(0) # combine current scores with previous alphas # since alphas are in log space (see logsumexp below), # we add them instead of multiplying scores = e_scores + t_scores + alphas # add the new alphas for the current tag alpha_t.append(torch.logsumexp(scores, dim=1)) # create a torch matrix from alpha_t # (bs, nb_labels) new_alphas = torch.stack(alpha_t).t() # set alphas if the mask is valid, otherwise keep the current values is_valid = mask[:, i].unsqueeze(-1) alphas = is_valid * new_alphas + (1 - is_valid) * alphas # add the scores for the final transition last_transition = self.transitions[:, self.EOS_TAG_ID] end_scores = alphas + last_transition.unsqueeze(0) # return a *log* of sums of exps return torch.logsumexp(end_scores, dim=1)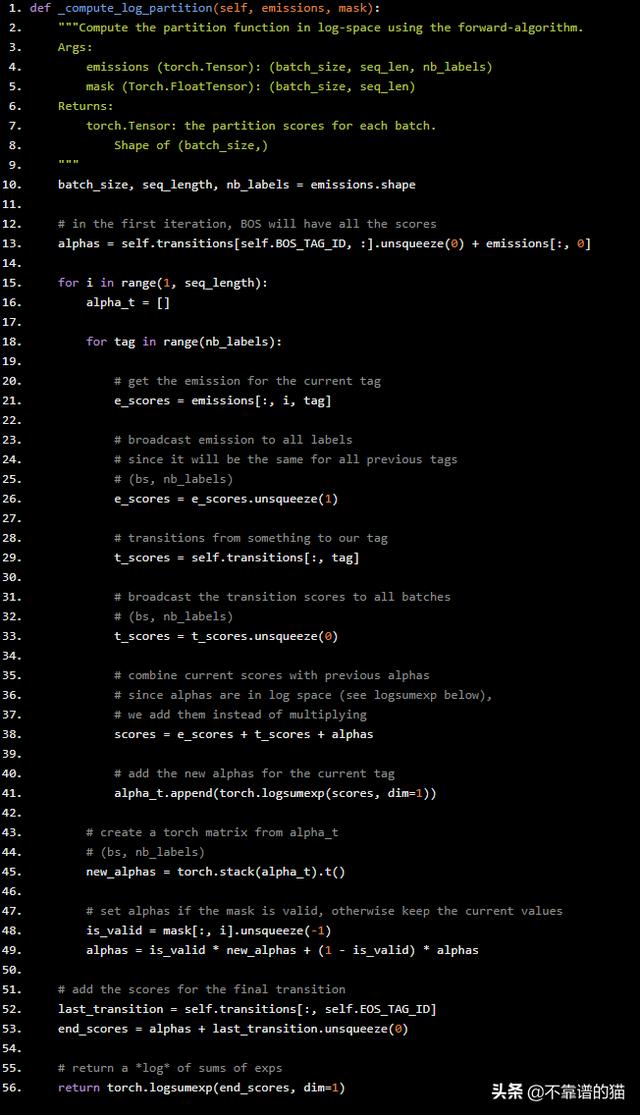
上面的代码与我们之前计算得分的方式非常相似。
这里只有一件事我们之前没有看到过:
- alphas = is_valid * new_alphas + (1 — is_valid) * alphas:在这一行中,如果我们没有达到pad 位置,我们正在将新的α的当前值更改为α,如果我们到达pad 位置,则保持相同的值。要了解其工作原理,请在时间步长i = 1时查看此示例:
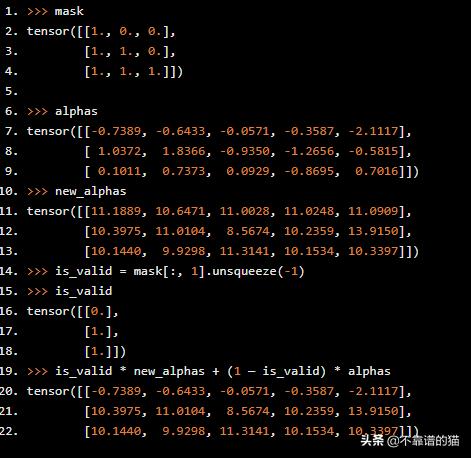
我们更新了第2和第3个序列,但没有更新第1个,因为在timetep i = 1时我们到达了pad位置。
作为一个很好的观察,你可以看到,一旦我们采用logsumexp,我们已经在log-space了!所以,我们可以将alpha的值添加到我们的分数中。最后,我们在最后再执行一次logsumexp操作,以返回到达句子末尾的最终值 - 所以我们仍然在log-space中。
找到最佳标签序列
如果我们计算后向算法 - 它只是向后遍历序列,我们可以找到在每个时间步k最大化P(y k | X)的标签。有趣的是, 如果我们假设CRF是真正的分布,这将是最佳解。它可以这样表达:
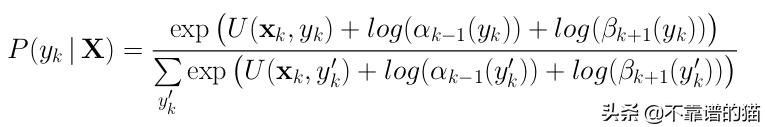
其中α分数来自前向算法,β分数来自后向算法。为了找到标签y * 的最佳序列,我们在每个时间步长取argmax:
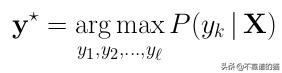
维特比算法(Viterbi algorithm)
但是,事实证明我们不需要计算后向算法以找到最可能的标签序列。相反,我们可以简单地跟踪前向算法期间每个时间步的最大分数。完成后,我们可以跟踪max操作的后向跟踪(argmax),以便解码最大化分数的序列。这正是下面的Python代码所做的:
def decode(self, emissions, mask=None): """Find the most probable sequence of labels given the emissions using the Viterbi algorithm. Args: emissions (torch.Tensor): Sequence of emissions for each label. Shape (batch_size, seq_len, nb_labels) if batch_first is True, (seq_len, batch_size, nb_labels) otherwise. mask (torch.FloatTensor, optional): Tensor representing valid positions. If None, all positions are considered valid. Shape (batch_size, seq_len) if batch_first is True, (seq_len, batch_size) otherwise. Returns: torch.Tensor: the viterbi score for the for each batch. Shape of (batch_size,) list of lists: the best viterbi sequence of labels for each batch. """ if mask is None: mask = torch.ones(emissions.shape[:2], dtype=torch.float) scores, sequences = self._viterbi_decode(emissions, mask) return scores, sequencesdef _viterbi_decode(self, emissions, mask): """Compute the viterbi algorithm to find the most probable sequence of labels given a sequence of emissions. Args: emissions (torch.Tensor): (batch_size, seq_len, nb_labels) mask (Torch.FloatTensor): (batch_size, seq_len) Returns: torch.Tensor: the viterbi score for the for each batch. Shape of (batch_size,) list of lists of ints: the best viterbi sequence of labels for each batch """ batch_size, seq_length, nb_labels = emissions.shape # in the first iteration, BOS will have all the scores and then, the max alphas = self.transitions[self.BOS_TAG_ID, :].unsqueeze(0) + emissions[:, 0] backpointers = [] for i in range(1, seq_length): alpha_t = [] backpointers_t = [] for tag in range(nb_labels): # get the emission for the current tag and broadcast to all labels e_scores = emissions[:, i, tag] e_scores = e_scores.unsqueeze(1) # transitions from something to our tag and broadcast to all batches t_scores = self.transitions[:, tag] t_scores = t_scores.unsqueeze(0) # combine current scores with previous alphas scores = e_scores + t_scores + alphas # so far is exactly like the forward algorithm, # but now, instead of calculating the logsumexp, # we will find the highest score and the tag associated with it max_score, max_score_tag = torch.max(scores, dim=-1) # add the max score for the current tag alpha_t.append(max_score) # add the max_score_tag for our list of backpointers backpointers_t.append(max_score_tag) # create a torch matrix from alpha_t # (bs, nb_labels) new_alphas = torch.stack(alpha_t).t() # set alphas if the mask is valid, otherwise keep the current values is_valid = mask[:, i].unsqueeze(-1) alphas = is_valid * new_alphas + (1 - is_valid) * alphas # append the new backpointers backpointers.append(backpointers_t) # add the scores for the final transition last_transition = self.transitions[:, self.EOS_TAG_ID] end_scores = alphas + last_transition.unsqueeze(0) # get the final most probable score and the final most probable tag max_final_scores, max_final_tags = torch.max(end_scores, dim=1)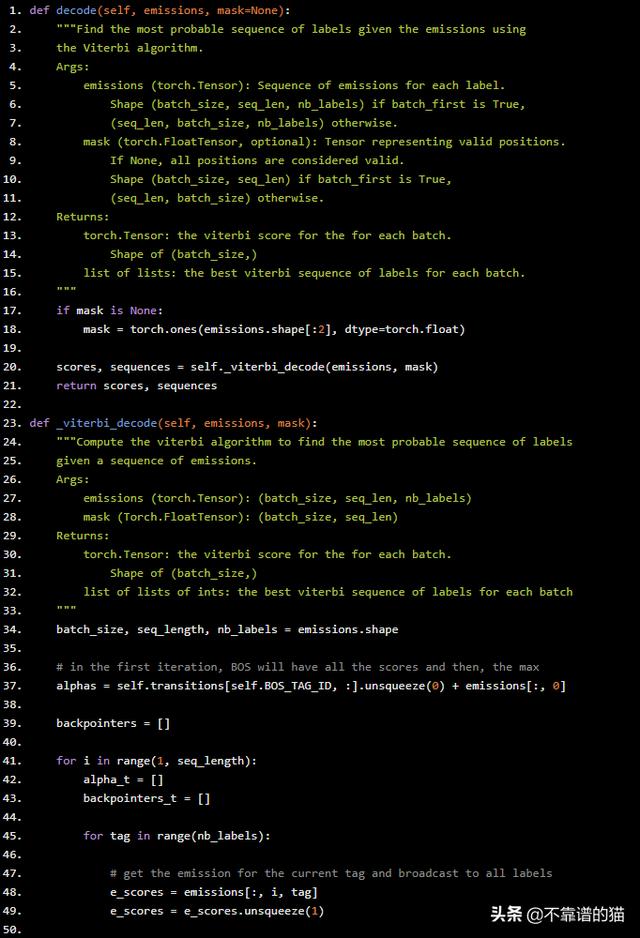
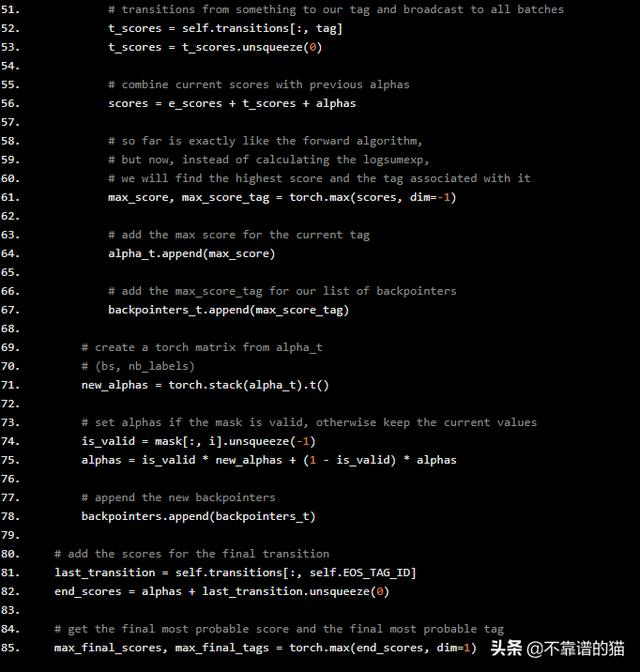
该算法称为维特比算法。它与我们在log_partition函数中使用的前向算法几乎相同,但不是对整个序列进行常规分数,而是具有最大分数和最大化这些分数的标记。换句话说,我们通过操作torch.max替换torch.logsumexp,它返回max和argmax。
现在我们需要做的一切就是选择这些最终的标记,并按照反向跟踪来查找“argmax”标记的整个序列。上述代码的延续部分如下:
# find the best sequence of labels for each sample in the batch best_sequences = [] emission_lengths = mask.int().sum(dim=1) for i in range(batch_size): # recover the original sentence length for the i-th sample in the batch sample_length = emission_lengths[i].item() # recover the max tag for the last timestep sample_final_tag = max_final_tags[i].item() # limit the backpointers until the last but one # since the last corresponds to the sample_final_tag sample_backpointers = backpointers[: sample_length - 1] # follow the backpointers to build the sequence of labels sample_path = self._find_best_path(i, sample_final_tag, sample_backpointers) # add this path to the list of best sequences best_sequences.append(sample_path) return max_final_scores, best_sequencesdef _find_best_path(self, sample_id, best_tag, backpointers): """Auxiliary function to find the best path sequence for a specific sample. Args: sample_id (int): sample index in the range [0, batch_size) best_tag (int): tag which maximizes the final score backpointers (list of lists of tensors): list of pointers with shape (seq_len_i-1, nb_labels, batch_size) where seq_len_i represents the length of the ith sample in the batch Returns: list of ints: a list of tag indexes representing the bast path """ # add the final best_tag to our best path best_path = [best_tag] # traverse the backpointers in backwards for backpointers_t in reversed(backpointers): # recover the best_tag at this timestep best_tag = backpointers_t[best_tag][sample_id].item() # append to the beginning of the list so we don't need to reverse it later best_path.insert(0, best_tag) return best_path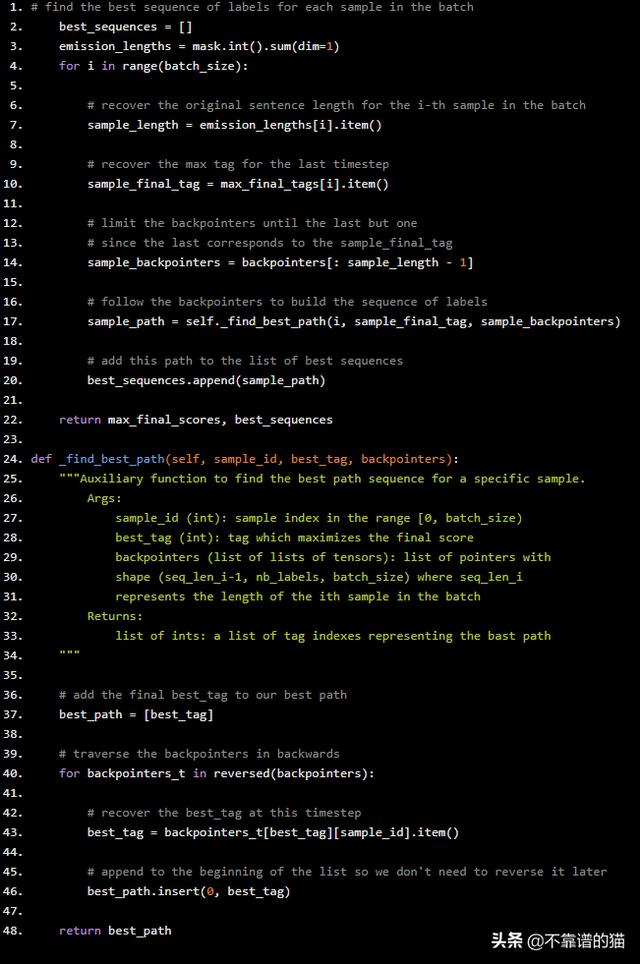
可以看到,对于每个样本,我们都在遍历该样本的backtrace,并且在每个timestep中插入标记,该标记将在best_path的开头最大化分数。因此,在最后,我们有一个列表,其中第一个元素对应于第一个标记,最后一个元素对应于序列的最后一个有效标记(参见第14行)。
结论
如果您想在生产中使用CRF模型,我强烈建议您使用经过良好测试的高效实现,比如pytorch包。















 6665
6665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









