






前沿
本文章所用的数据均是笔者通过scrapy爬虫从链家网爬取的上海市宝山区二手房交易的数据,关于数据源以及源代码的获取,请访问笔者的GitHub链接:
cavensbee/Scrapygithub.com
2018年末,上海地区的二手房房价开始出现下跌,到2019年,房价又出现短暂的回暖,正好笔者本人住在宝山区附近,就对上海宝山区的当前房价做一次数据分析和可视化报告,本人不才,正在往数据分析师方向成长,用到的技术也只是浅显,还望大牛多多指教
分析流程
1、房价网站的数据爬取
2、对爬取到的数据清洗
3、提出问题
4、构建模型分析
5、对数据可视化
6、报告总结
房价网站的数据爬取
笔者通过Scrapy爬虫,对链家网上海宝山区二手房的房价进行数据爬取。相关Scrapy的核心源码,已经放在GitHub上。
关于爬虫需要爬取的关键字:地区(宝山)、区域、小区名称、户型、面积、单价、总价、朝向、建筑类型、装修状况、关注人数等。
利用Scrapy配合css选择器将数据成功爬取到后,保存为本地csv文件格式,下一步为对本地csv源数据进行清洗和整理。
数据清洗

打开保存的csv文件,此为完全没有做过处理的源数据,下面对数据进行处理。
- 将该数据源用Notepad++打开,将编码格式改为UTF-8-BOM格式,这是为了防止通过Scrapy爬取后的数据用Excel打开后形成乱码,事先用Notepad++打开后重新更改编码格式。再用Excel打开数据源后,发现每一行之间都有一行是空的,选中该数据区域,定位到空值后,选中删除工作表行,将空行全部删除。
- 缺失值处理,通过定位找到缺失值的位置,为保存数据源完整性,通过手动补全,或者平均值补全的方式填补缺失值
- 一致化处理,个别单元格如面积,单价,总价等无法直接运算分列,设置单元格格式等方式处理一下
- 处理异常值,通过筛选,找到异常值,并进行处理
清洗后的数据如下:
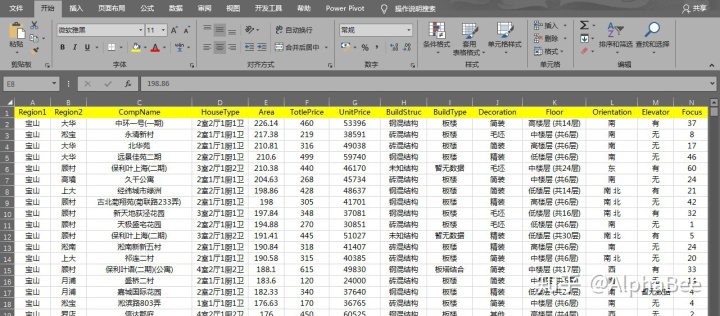
构建分析模型
主要采用MySQL的方式进行分析,将数据源导入Navicate MySQL中。
- 筛选出当前在出售的房源数量排名前十的区域

由此可看出,当前宝山区,顾村在售的房源数量是最多的,经过参考这可能得益于顾村所处的上海地理位置,顾村位于市中心城区最近的近郊城镇,同时有着顾村公园这样一个上海市著名景区,所以笔者推测开发商在此建造商品房会更能吸引买家。
- 筛选出当前在售房源中的热门小区以及所在的区域

由筛选结果可知,大华一村和共富一村这两个小区的在售房源数量最多,大华位于中环以内,离市中心不算远,且交通便利,共富新村则是顾村大型居住社区拓展基地,也是上海规划推进区域性建设的重要项目,可以预计,共富新村也将是上海宝山区的房源热门区域。
- 热点区域的房价排行

从数据中可看出,房价宝山地区的均价最高可到达8万多每平米,而排名前十的均价普遍在6万多每平米。
- 当前在售的热门户型的筛选

从数据中可以看出,2室户的房型是目前在售的主要户型,其次就是三居室,该趋势说明目前在上海的人群倾向于从两居室到三居室的改善。
- 宝山各区域房屋总价的排行
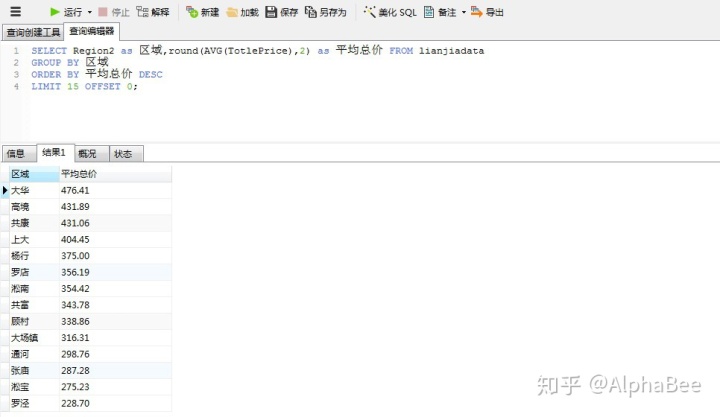
对比上面分析出的数据,可以看出,顾村在平均总价中排行中等,但是拥有的房源数量是最多的,这表明更多有能力购房的需求者,会选择在这一区域购房,而房源数量排行前三的大华,则是宝山区平均总价最高的区域。这可能存在两种结果:
- 总价的过高超过了购房需求者的购买能力范围,同时由于通货膨胀的影响,早期开发商对于该区域的预估存在偏差。
- 存在一种趋势,对比当前在售户型的数据分析可看出,除了两居室,目前在售的热门户型更多的是三居室,相对应的总价也会提高,所以不排除该区域未来会成为宝山区购房需求者的热门关注区域。
数据可视化分析
任何数据都不如图表更加直观和清晰可见,笔者运用Python的numpy包,pandas包,matplotlib包,通过PyCharm工具对以上爬取到的数据进行可视化分析的图表制作。
相关代码请访问笔者的GitHub链接:
cavensbee/Python_matplotlib-pandasgithub.com
导入Python相关的数据包:
import 规范化图形:
mpl.rcParams['font.sans-serif'] = ['FangSong']
#将字体默认设置为仿宋
mpl.rcParams['axes.unicode_minus'] = False
#使图像正常显示'-'负号,而不会出现方块读取数据:
house = pd.read_excel(r'C:UsersAlfaBeeDesktopLianJiaLianJiaDataBaoShanPriceData.xlsx')包含的字段如下:

- 首先针对二手房的面积分布,进行可视化分析
area_level = [0,50,100,150,200,250]
level_label = ['小于50','50-100','100-150','150-200','200-250']
area_cut = pd.cut(house['Area'],area_level,level_label)
level_num = area_cut.value_counts()
x = list(range(0
,len(level_label)))
y = list(level_num)
level_num.plot(kind ='bar',alpha = 0.5)
plt.xticks(fontproperties='songTi',fontsize=16)
plt.yticks(fontproperties='songTi',fontsize=16)
plt.grid(linestyle = '--')
plt.title('二手房面积分布',fontsize = 20)
plt.xlabel('面积',fontsize = 18)
plt.ylabel('数量',fontsize = 18)
plt.legend(('数量',),loc = 0,fontsize = 18)
for a,b in zip(x,y):
plt.text(a,b+0.7,'%.0f' % b,ha = 'center',va = 'bottom',fontsize = 20)
plt.savefig(r'C:UsersAlfaBeeDesktop二手房面积分布.png')
plt.show()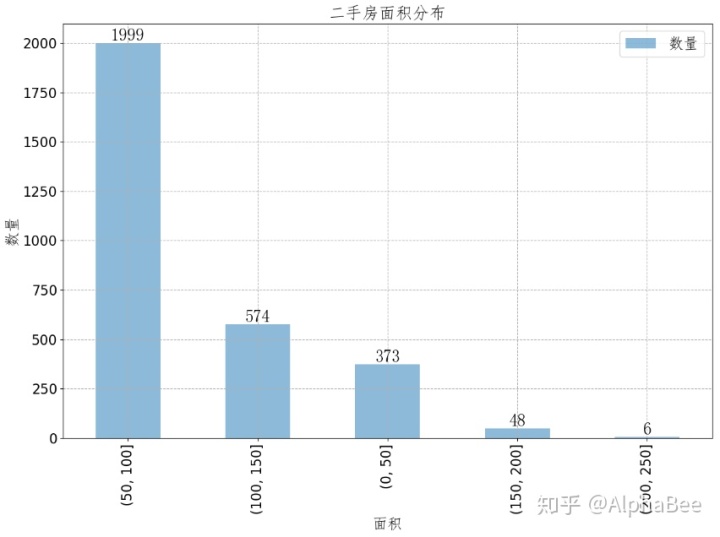
如图表所示,50-100平米的面积是大多数购房需求者选择的面积范围,这一面积范围一般是两居室的房子,而且这一面积的房价一般都在购房需求者的可承受经济能力的范围内,如下图表所示即可很明显的看出。
- 户型数量分布
housetype = house['HouseType'].value_counts()
housetype.head(10).plot(kind = 'bar')
- 各地区房源数量分布
region_num = house.groupby('Region2').size().sort_values(ascending=False)
x = list(range(0,len(region_num)))
y = list(region_num)
region_num.plot(kind = 'bar',alpha = 0.7)
for a,b in zip(x,y):
plt.text(a,b+0.5,'%.0f' % b,ha = 'center',va = 'bottom',fontsize = 20)
plt.show()
上图为针对各个地区的房源数量分布的可视化,可清晰的看出各个地区的房源数量分布,也很明显的看出顾村镇的在售房源数量最多。
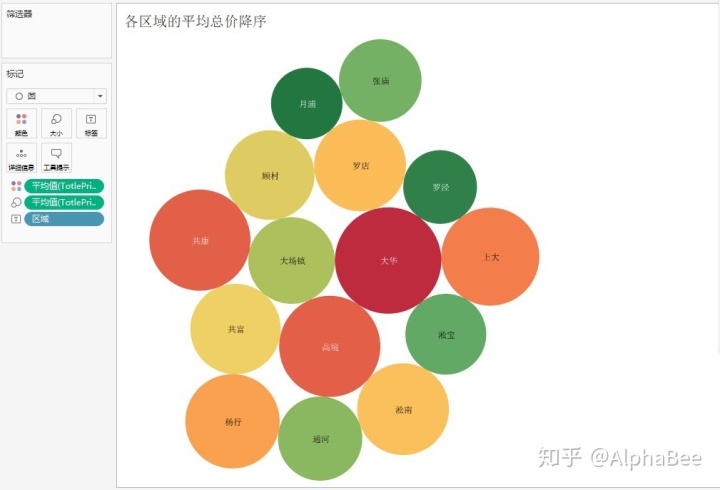
下面利用tableau分别对宝山区各版块的平均单价和平均总价展示可视化图表。
- 利用tableau展示宝山区域平均单价

- 宝山区域的平均总价
报告总结
通过系列的数据筛选分析后,可以很清晰的看出,宝山区的当前房源主要集中在中环以内,且都是离市中心不远的区域;考虑到交通状况和经济环境,相比市区的高昂价格和郊区的偏僻,离市区较近的区域且交通环境较为便利,成为了很多购房需求者的选择;而本次爬取数据源的链家网,也是多针对这些区域发布房源信息,可以预计,未来房屋的价格和购买倾向,会随着市区向郊区扩展而变动,而城郊中心的位置,房屋价格会有提升,慢慢趋向于市区的价格,当然不排除政府调控干预的可能性。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









