






 AMD发布Matrix Core技术,应用于新款AMD Instinct MI100加速器,旨在深度学习和HPC领域提供卓越性能。MI100拥有11.5 TFLOPS的FP64峰值性能和46.1 TFLOPS的FP32 Matrix峰值性能,支持PyTorch和TensorFlow等框架,提供高速HBM2内存和PCIe Gen 4.0接口。
AMD发布Matrix Core技术,应用于新款AMD Instinct MI100加速器,旨在深度学习和HPC领域提供卓越性能。MI100拥有11.5 TFLOPS的FP64峰值性能和46.1 TFLOPS的FP32 Matrix峰值性能,支持PyTorch和TensorFlow等框架,提供高速HBM2内存和PCIe Gen 4.0接口。

AMD 发布 Instinct MI100 加速器,它使用最新 Matrix Core 技术,是面向 HPC 和 AI 的新型加速系统。AMD 表示这是全球最快的 HPC GPU,也是首个超越 10 teraflops (FP64) 性能障碍的 x86 服务器 GPU。
机器之心报道,编辑:魔王、小舟。

当前,GPU 已经成为深度学习训练的标配,而针对深度学习中的 Tensor 操作,各大厂商在设计软硬件时都会做特别优化,其中知名的就是英伟达的 Tensor Core。
今日,对标英伟达 Tensor core,一直发展迅猛的 AMD 也推出了类似功能单元 Matrix Core。同时,基于 Matrix Core 技术,AMD 发布了新型 AMD Instinct MI100 加速器,据称是全球最快的 HPC GPU 和首个超越 10 teraflops (FP64) 性能障碍的 x86 服务器 GPU。
据 AMD 官方介绍,AMD Instinct MI100 GPU 配备了全新 AMD CDNA 架构,使用第二代 AMD EPYC 处理器,是面向 HPC 和 AI 的新型加速系统。
在性能上,MI100 为 HPC 提供了高达 11.5 TFLOPS 的 FP64 峰值性能,为 AI 和机器学习提供了高达 46.1 TFLOPS 的 FP32 Matrix 峰值性能。
与 AMD 的上一代加速器相比,MI100 凭借新的 AMD Matrix Core 技术,为 AI 训练提供了近 7 倍的 FP16 理论峰值浮点性能提升。
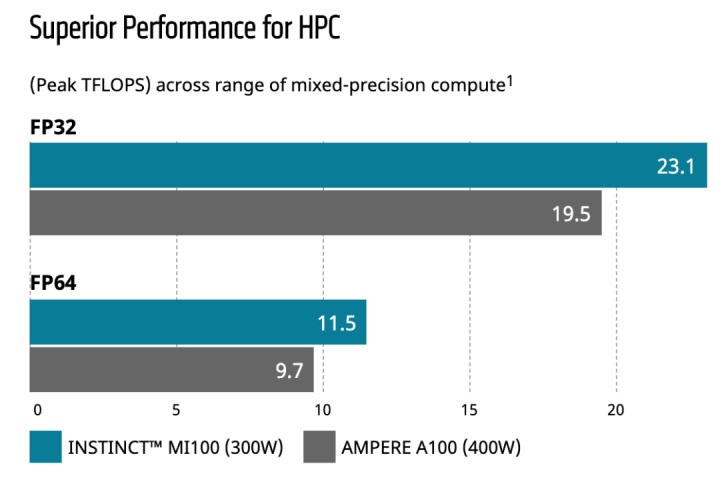

AMD Instinct MI100 为 HPC 和 AI 提供优秀的性能(图源:https://www.amd.com/zh-hans/products/server-accelerators/instinct-mi100)
MI100 的具体规格参见下表:
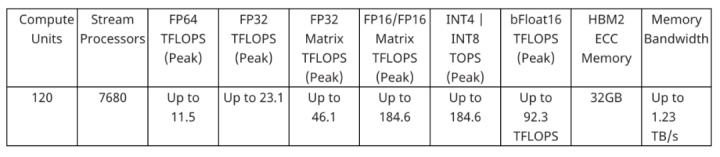
AMD 数据中心 GPU 和加速处理公司副总裁 Brad McCredie 表示:「AMD Instinct MI100 的推出,标志着 AMD 朝着百亿亿级计算迈出了重要的一步。这款新型加速器专为科学计算中重要的工作负载打造,结合 AMD ROCm 开放软件平台后,能够为科学家和研究人员在 HPC 中的工作提供坚实的基础。」
此外,AMD 还推出了 ROCm 4.0。ROCm 开发者软件平台旨在为百亿亿级计算提供基础,包括编译器、编程 API 和库。此次推出的 ROCm 4.0 针对基于 MI100 的系统进行了优化,将编译器升级为开源版本,并支持 OpenMP 5.0 和 HIP。经过 ROCm 4.0 优化,PyTorch 和 Tensorflow 框架可以基于 MI100 实现更高的性能。
AMD Instinct MI100 加速器的特性
以下是 AMD Instinct MI100 加速器的关键能力和特性:
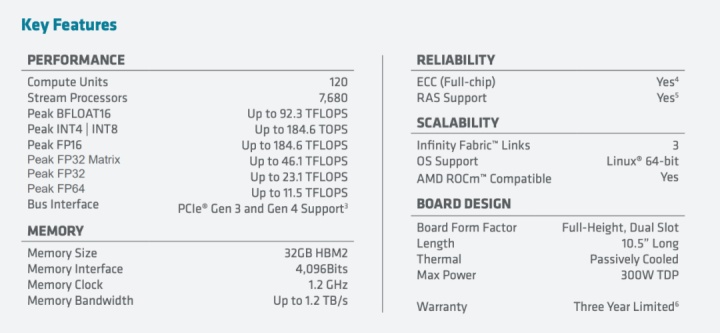
AMD Instinct MI100 的关键特性一览表(图源:https://www.amd.com/system/files/documents/instinct-mi100-brochure.pdf)
- 全新的 AMD CDNA 架构:该架构专为 AMD GPU 适应百亿亿级计算时代而打造,是 MI100 加速器的核心,能够提供卓越的性能和能效。
- 适应 HPC 工作负载的 FP64 和 FP32 顶尖性能:峰值 FP64 和峰值 FP32 的性能分别达到 11.5 TFLOPS 和 23.1 TFLOPS,行业领先。
- 全新的 Matrix Core 技术:适合多种单精度和混合精度矩阵运算(如 FP32、FP16、bFloat16、Int8 和 Int4)的超强性能,从而提升 HPC 和 AI 的收敛性能。
- 第二代 AMD Infinity Fabric 技术:Instinct MI100 提供大约二倍的 PCIe 4.0 接口 P2P 峰值 I/O 带宽,每块 GPU 配置三条 AMD Infinity Fabric 总线,总带宽高达 340 GB/s。在服务器上,MI100 GPU 可以配置两个全连接 quad GPU hive,每个提供高达 552 GB/s 的 P2P I/O 带宽,从而实现快速数据共享。
- 超快 HBM2 内存:32GB 高带宽 HBM2 内存,时钟速率为 1.2 GHz,可以提供超高的 1.23 TB/s 内存带宽,以支持大型数据集,并消除数据进出内存的瓶颈。
- 支持业内最新的 PCIe Gen 4.0:支持最新的 PCIe Gen 4.0 技术,提供高达 64GB/s 的 CPU 到 GPU 理论数据传输带宽。
原文链接:https://ir.amd.com/news-events/press-releases/detail/981/amd-announces-worlds-fastest-hpc-accelerator-for


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









