






本文是在阅读完《Residual Attention Network for Image Classification》所做的笔记,
由于本人对注意力机制了解甚浅,笔记当中若有不恰当的地方,还望指出。
0 前言
计算机视觉中的注意力机制的基本思想是让模型学会专注,把注意力集中在重要的信息上而忽视不重要的信息。
举个简单的例子,对于图像分类任务,有只狗在广阔无垠的沙漠里漫步,模型能识别出有只狗,那假如狗是在茂密的森林里散步呢,模型有可能识别不出来,这是为什么呢?
因为模型并没有把注意力放在狗上,而是放在整张图上,这样一旦换了背景,模型很有可能会分类出错。而我们人类却能很好地对此进行分类,因为我们只关注场景中是否有狗,而不关注背景究竟是沙漠还是森林,可以简单地理解这就是注意力机制。
那如果让模型也像我们一样只关注场景中是否有狗,那岂不是分类会更准?是的,会更准。
1 介绍
接下来本文将介绍Residual Attention Network,它是一种注意力网络。受注意力机制和深度神经网络的启发,作者提出了Residual Attention Network,它主要包含数个堆积的Attention Module,每一个Module专注于不同类型的注意力信息,而这样简单地堆积Attention Module会对特征的表达有负面的,所以作者提出了Attention Residual Learning。
Residual Attention Network的结构如下:

在详细介绍Residual Attention Network的设计之前,先看看它的优点。
优点:
(1) 生成的特征更具判别度,即在特征空间中,类内差距小,类间差距大
(2) 逐渐增加Attention Module的数量,能持续提高模型的性能
(3) 能以端到端的训练方式整合到深层网络当中
原因:
(1) Stacked network structure:分工不同,不同的Attention Module能捕获不同的注意力信息,这里的不同模块是指所处的位置不同,而模块的结构是一样的
(2) Attention Residual Learning:Stacked network structure会导致性能明显的下降,于是提出了Attention Residual Learning,这个会在下面介绍
(3) Bottom-up top-down feedforward attention
2 网络设计
2.0 Attention Module
Residual Attention Network由多个Attention Module组成。每一个Attention Module分为两条branch,一条是mask branch,另一条是trunk branch。trunk branch负责提取特征,mask branch负责生成注意力信息(即权重)。
假定一个模块H的输入是x,trunk branch的输出是T(x),mask branch的输出是M(x),则模块H的输出是
在Attention Module中,mask不仅做为前向传播的特征选择器,还做为反向传播的梯度过滤器,公式一看便知,
其中
那为什么要使用多个Attention Module呢?
如果只使用单个的Attention Module,会存在以下问题:
(1) 图片的背景可能是混乱的、复杂的,前景的形态可能是多变的,例如不同的狗在不同的背景之下,而这把这样的重任交给单个的Attention Module,这样效果肯定是不如人意的
(2) 单个Attention Module只修正特征一次,如果恰好这次的修正是不恰当的,也就是注意力发挥的作用是负面的,那后续的特征就没有得到再次修正的机会了,那这样的结果肯定也是不如人意的
当然了,Residual Attention Network很好地解决了上述的两个问题,它使用多个Attention Module,每一个trunk branch有其对应的mask branch,这样不同的mask branch就能学到不同的注意力信息。

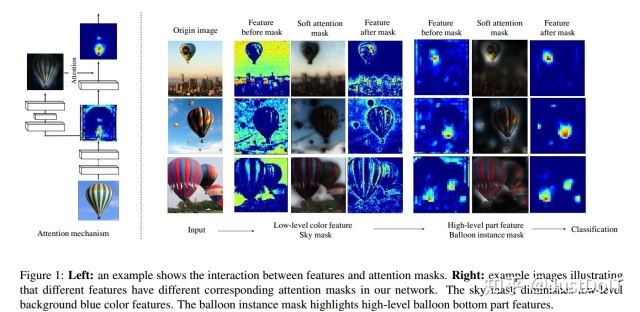
如上图,这是一张热空气气球的图片,在Low-level处,有对应的Sky mask清除蓝色的颜色特征,同时在High-level处,有对应的Ballon instance mask修正part feature。
2.1 Attention Residual Learning
然而,简单地堆积Attention Module却会导致性能的明显下降。这其中的原因有两个,一是mask的值是在0-1之间,如果特征图反复地和mask做点乘运算,无疑会降低深层特征层的值(0.9 * 0.9 * 0.9*0.9 ......会变得很小),另一个是soft mask会破坏trunk branch的良好特性。
为此,作者提出了attention residual learning。Attention Module的输出H可重新定义为:

在介绍处提到的Bottom-up top-down feedforward attention其实就是这里的down sample和up sample。
堆积Attention Module并使用Attention residual learning,能使模型在保留重要的特征情况下还不破坏原始特征的特性。堆积的Attention Modules能渐渐地修正特征图,从下图可知,层数越深,特征越清晰。
2.2 Soft Mask Branch
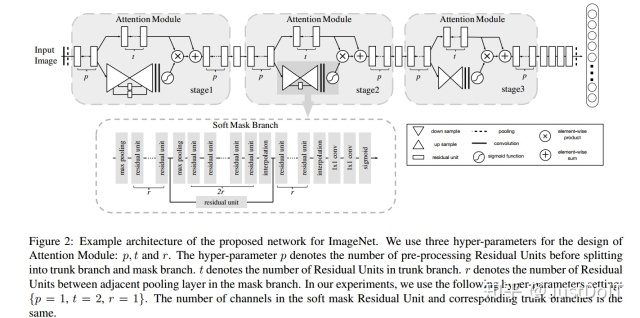

其中r表示的是相邻最大池化之间残差模块的数目,上图就是其中一个Soft Mask Branch,包括fast feed-forward sweep和top-down feedback step,前者用于快速地收集整张图片的全局信息,后者用于把全局信息和原始特征图结合起来。
2.3 Spatial Attention and Channel Attenion
对应于mixed attention、channel attention、spatial attention这三种注意力机制,作者分别使用了三种不同类型的激活函数。对于mixed attention
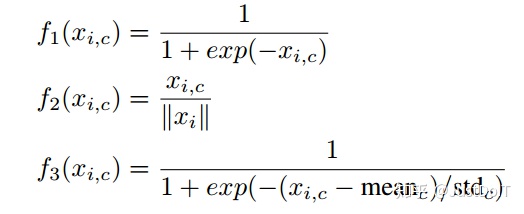
其中i是像素点的位置,c是对应的通道位置,
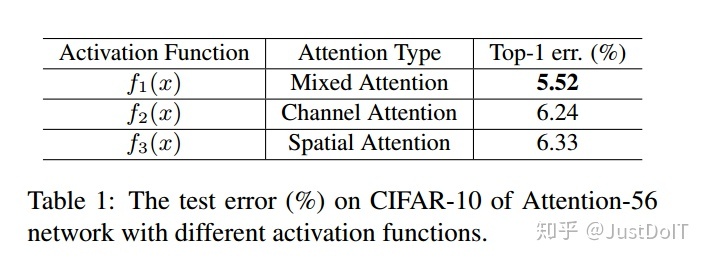
实验结果如上图,mixed attention的效果最好,这表示让Attention Module自适应地改变而不添加额外的约束会获得更好的性能。
3 总结
作者提出了Residual Attention Network,它包含数个Attention Module,并使用了Attention Residual Learning。Residual Attention Network效果好的原因有两,一是包含数个Attention Module,这样每个Attention Module都能关注不同类型的注意力信息,二是把top-down注意力机制整合到bottom-up top-down feedforward结构当中。















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









