






卡尔曼滤波算法思想理解 Kalman filter 第一篇
最近在初步的理解目标跟踪的领域, 其中一个非常经典的算法卡尔曼滤波Kalman filter是需要有很好的理解才行, 由于已经脱离了学校,懂得寻找资源学习就变的非常重要, 我会先找找国内资源有没有好的视频讲解算法, 但通常一搜下来的结果不是一开始就讲公式不讲来由, 不然就是讲的太差还好意思上传的, 对于这样的资源实在不敢花时间观看, 人生短暂, 实在不愿意做这样的赌注, 而确实许多q外的视频确实好,所以接下来我就以matlab官方在youtube 的channel所讲解的Karlman filter 作为学习基础, 并且记录
首先我们需要知道为什么需要卡尔曼滤波?
我们来举一个例子

太空船飞行到火星需要很强大的动力推进才有可能到的了对吧?
但是强大的动力也代表会产生极高的热能, 这热能是会将靠近燃烧室附近的机械组件融化的, 导致太空船损毁,如果要避免这样的问题, 我们必须严格密切的监控燃烧室内的温度, 是不是在推进器周围装个温度sensor就能解决问题? 当然没那么简单, 前面提过超高温度会融化许多的机器组件, 那同样的你的sensor也一样会被融化, 于是我们将sensor装在燃烧室附近温度比较低的地方就行, 但是这样测量到的温度显然是不准确的, 卡尔曼滤波就是解决这样的问题而诞生
注意这里我们引入了一个概念就是 测量measurement
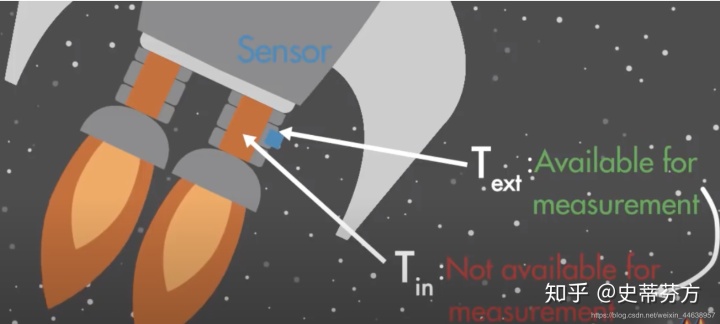
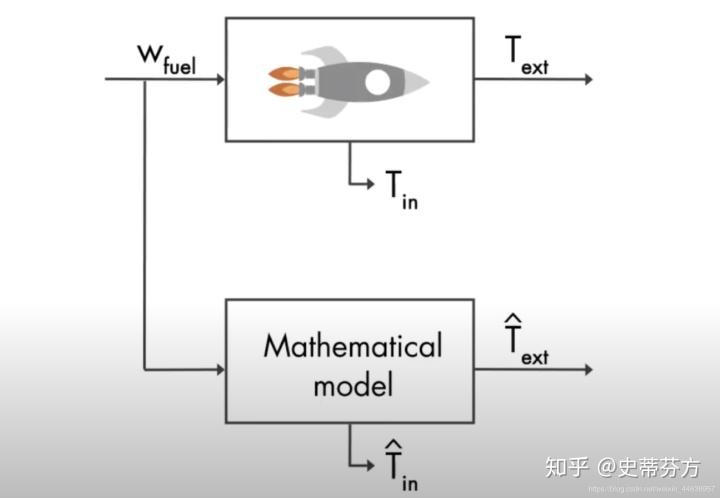
我们继续用太空船这个例子继续说明, W表示输入燃料, Tin, Text分别表示燃烧室内部温度以及外部温度(可以搭配上面的图对照), 大家都知道航天方面的工程计算是必须严谨的, 所以在飞之前肯定已经陈列了许多的计算式来推算出输入W量的燃料会为燃烧室产生多少温度(就是下面的Mathematical model), 也许你在地面上可以模拟的非常精准, 但实际等太空船上了太空又是另一回事了, 所以基本上是没办法单靠设计的数学式就能推算出Tin, Text的, 这个时候我们就需要K来当做控制器, 调和y(测量值)和yhat(预测值)中间的误差,
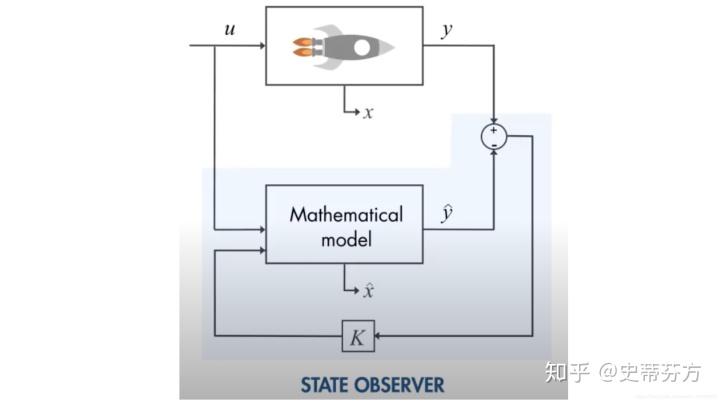
这个K的作用就是想办法将 y 和 yhat 之间的误差降至最小
好 太空船的例子举到这边就可以了, 注意到了这里我们已经引入一共两个概念
- 测量measurement
- 预测prediction
接下来用另一个例子加深印象也同时说明Kalman的原理
假设有一场比赛是关于自动驾驶的汽车, 决定胜出的关键就是 经过多次尝试之后 取最终平均停车的位置, 这个停下来的位置越靠近终点线, 就说明你设计的越好, 也能够胜出这场比赛
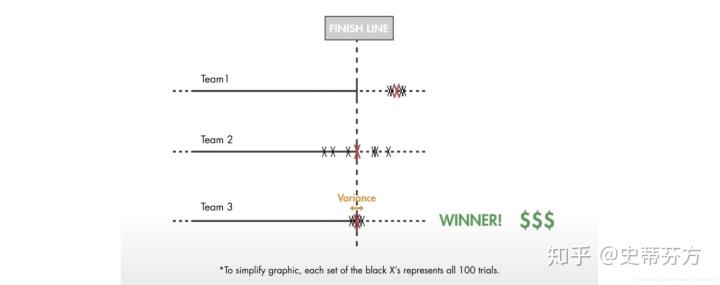
首先看看Team1, 明显偏离了终点线太远了, 而team2呢? 虽然最终平均下来的位置确实在终点线上, 但是你看每一次停车的差距都非常大, 能算胜利吗?, 为了提高鉴别度, 必须将所有数据的方差值考虑进来,
不仅方差要小, 也要平均停车的位置最靠近终点线才算胜出 !
接着我们回到怎么去设计才能让我们的自驾车能够精准的到终点线上
记得我们要设计的是自动驾驶的技术,这可是AI啊! 单靠GPS系统是不够智能的, 且可能会有非常大的误差
我们将自驾车从起始点到终点线停下的整个过程可以用数学式子表达成如下
u 表示速度, yk 表示实际测量出停车的位置
vk 和wk 都表示噪声, 也就是那些随机影响的因素
wk 代表的 可能是风的影响或者任何影响汽车速度变化的因子
我们可以很简单的就认定一件事实, 就是…
正因为yk也受到了噪声的影响, 能100%信任吗? 绝对是不行的吧
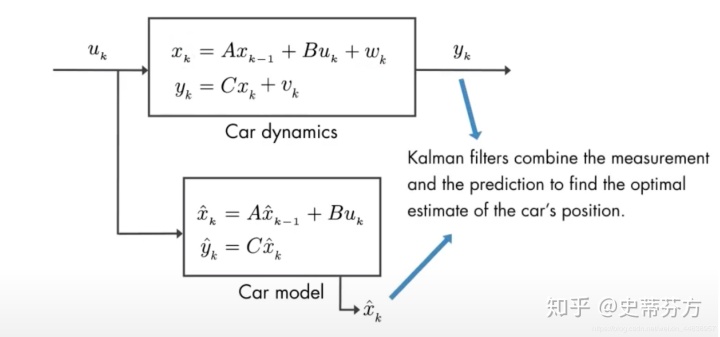
如果我们也能用一个自己设计出的car model来预测出大概的停车位置xhat_k
这个能完全信任吗? 显然也是不行的, 因为推算出的xhat_k是没有噪声的(对应到上图的下半部), 不能表达出实际的情况
所以在一次的强调我们的Kalman要出场了
我们可以用一个概率密度函数图来说明一下上面的整个式子, 在概率密度图上会是怎样的? 如下
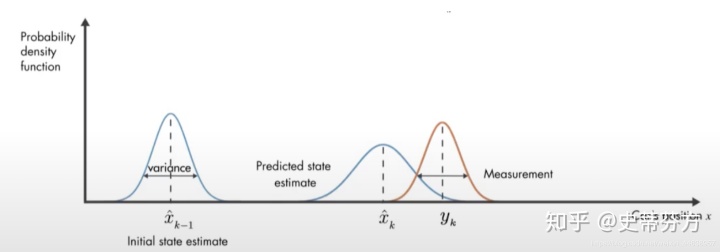
可以看见
- 最左边的初始状态, 也就是k-1的位置
- 满足正态分布, 最可能的起始位置就是中间(平均值)附近的地方
- 中间xhat_k也就是透过model预测出来的位置
- 满足正态分布, 假设在停车点附近停了100次, 而平均下来最可能停的地方就是在分布的中间附近
- 最右边的红色线段就是实际测量值
- 实际测量同上, 也一定满足高斯, 在正中间是最常停的位置
三个值都是满足高斯分布的
最后我们提出一个问题是, 有了预测和测量这两个值, 那对于汽车位置最佳的估计到底是哪里呢?
终于要说到Kalman的核心思想了
最佳的方法就是将这两个预测和测量的分布信息结合, 怎么结合?就是两个概率函数进行相乘
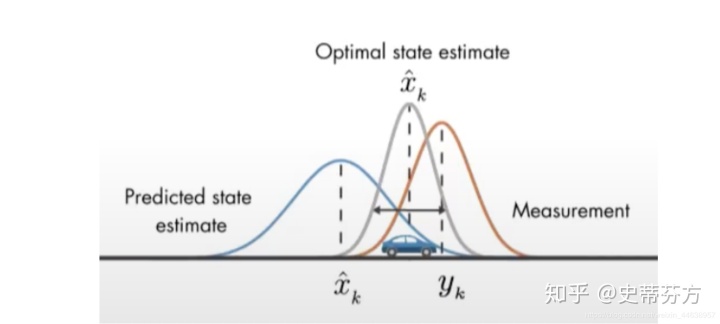
相乘结果如上
相乘后的结果同样满足高斯分布, 但是有更小的方差, 同时最终汽车可能停止的位置也位于该高斯分布的中间位置左右
这就是Kalman滤波的核心思想 !
这篇核心理念的地方就暂时到这边, 下一篇就继续讲讲算法上的概念及实现吧 !
有了图解肯定比直接带入公式讲更容易理解的对吧? 如果有帮助到你理解, 请给我一个赞
写些打加啊
未经同意请勿转载, 转载前麻烦先跟我说一下啦 写些啦
参考
matlab 官方youtube channel















 847
847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









