







- 算法简介
K-means方法是聚类中的经典算法,数据挖掘十大经典算法之一;算法接受参数k,然后将事先输入的n个数据对象划分为k个聚类以便使得所获得的聚类满足聚类中的对象相似度较高,而不同聚类中的对象相似度较小。
- 算法思想
以空间中k个点为中心进行聚类,对最靠近他们的对象归类,通过迭代的方法,逐次更新各聚类中心的值,直到得到最好的聚类结果。
- 算法描述
(1)适当选择c个类的初始中心;
(2)在第k次迭代中,对任意一个样本,求其到c各中心的距离,将该样本归到距离最短的那个中心所在的类;
(3)利用均值等方法更新该类的中心值;
(4)对于所有的C个聚类中心,如果利用(2)(3)的迭代法更新后,值保持不变,则迭代结束;否则继续迭代。
- python实现
# 创建数据
from sklearn.datasets.samples_generator import make_blobs
import matplotlib.pyplot as plt
x,y_true = make_blobs(n_samples = 300, #生成300条数据
centers = 4, #四类数据
cluster_std = 0.5, #方差,决定数据离散程度
random_state = 0)
print(x[:5])
print(y_true[:5])
plt.scatter(x[:,0],x[:,1],s = 10,alpha = 0.8)
plt.grid()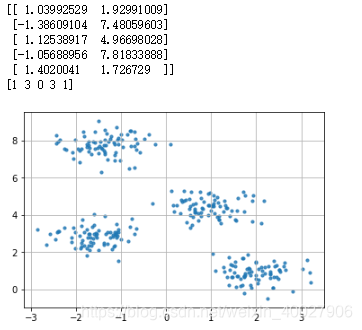
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 4)
kmeans.fit(x)
y_kmeans = kmeans.predict(x)
# 中心位置
centroids = kmeans.cluster_centers_
plt.scatter(x[:,0],x[:,1],c = y_kmeans, cmap = 'Dark2',s = 50 , alpha = 0.5,marker = 'x' )
plt.scatter(centroids[:,0],centroids[:,1],c = [0,1,2,3],cmap = 'Dark2',s = 70,marker='o')
plt.title('K-means 300 points\n')
plt.xlabel('Value1')
plt.ylabel('Value2')
plt.grid()
- K-means算法与KNN算法比较
| K-means | KNN |
| 非监督学习 | 监督学习 |
| 聚类算法 | 分类算 |
| 输入数据不带有label,是杂乱的数据 | 输入的数据带有label,是明确的数据 |
| 有明显前期训练过程 | 没有前期训练过程 |














 1055
1055











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









