







(一).算法概念
K-Means算法是一种聚类分析(cluster analysis)的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。
它的基本思想是,通过迭代寻找K个簇(Cluster)的一种划分方案,使得聚类结果对应的损失函数最小。其中,损失函数可以定义为各个样本距离所属簇中心点的误差平方和:
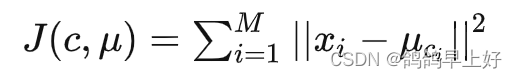
(二).具体步骤
通过迭代不断的划分簇和更新聚类中心,直到每个点与其聚类中心的距离之和最小,停止迭代。要预先知道聚类簇的个数num,和初始化聚类中心centre。聚类簇的个数一般已知。而初始化聚类中心的值是随机初始化的。
选择K个点作为初始质心
repeat
将每个点指派到最近的质心,形成K个簇
重新计算每个簇的质心
until 簇不发生变化或达到最大迭代次数
其中,距离的计算可以选取欧式距离或曼哈顿距离等等。
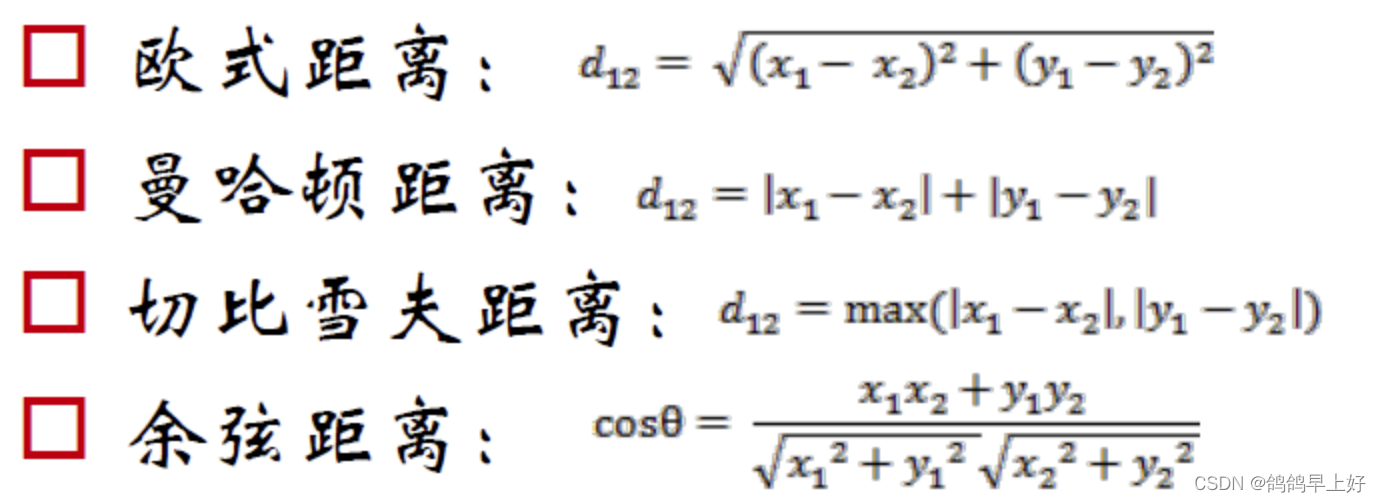
(三).代码实现
1.自定义数据集:
sklearn.datasets.make_classification官网详解:http://sklearn.datasets.make_classification
# 202011000106
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets
# 产生多类单标签数据集,为每个类分配一个或多个正态分布的点集,为测试聚类算法而使用的
# 数据集:
x, y = datasets.make_classification(n_samples=200, # 默认样本个数是100个
n_features=2, # 产生的默认特征 n_features 是两种,0 和 1
n_informative=2, # 信息特征的数量
n_redundant=0, # 冗余特征的数量
n_repeated=0,
n_classes=3, n_clusters_per_class=1, # 有三个类,每个类有一簇
# 剩余都是默认值
weights=None, flip_y=0.01, class_sep=1.0, hypercube=True, shift=0.0, scale=1.0,
shuffle=True, random_state=0)
# 返回值:xarray of shape [n_samples, n_features]是生成的样本;yarray of shape [n_samples]是每个样本的类成员的整数标签。
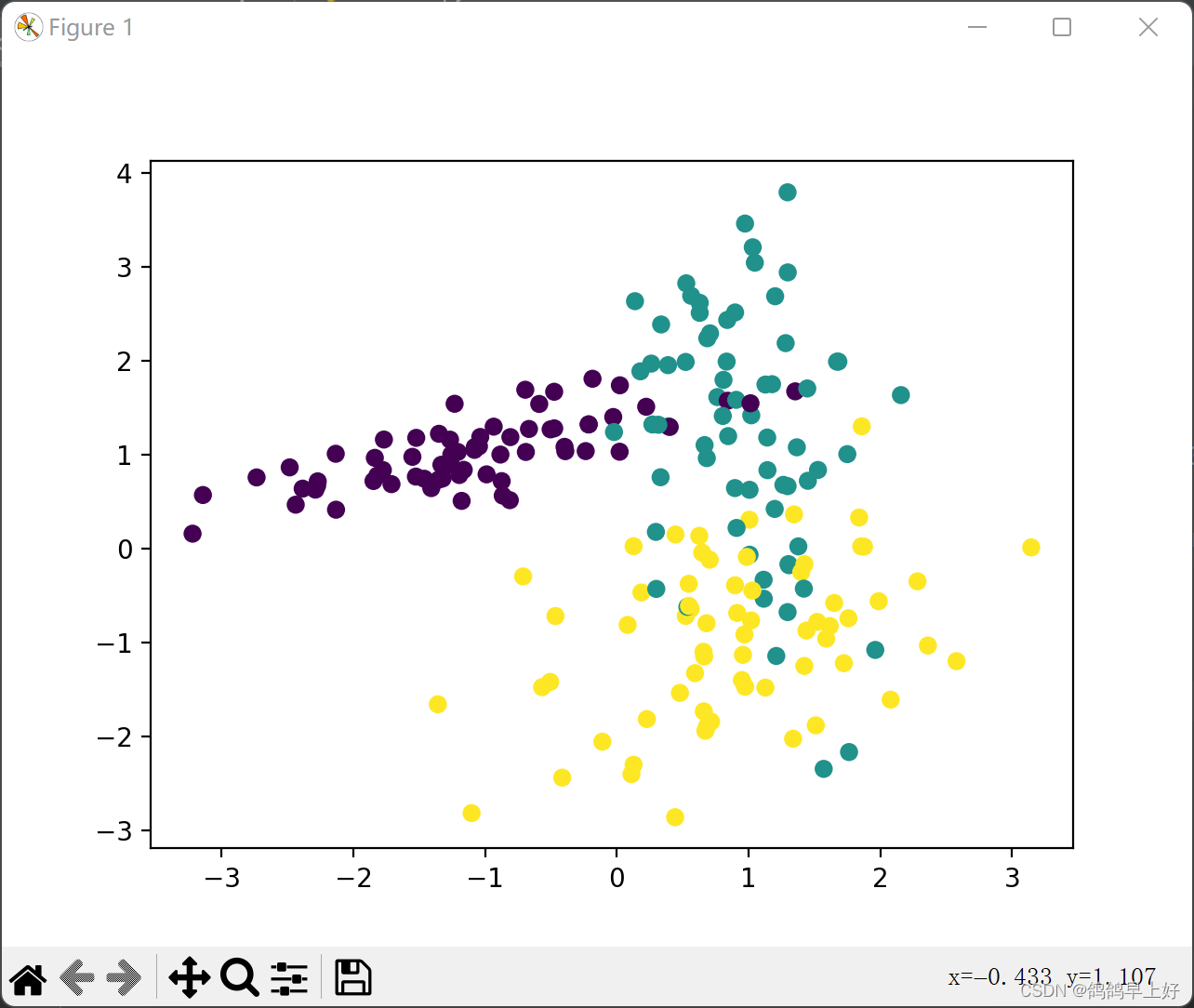
plt.scatter(x[:, 0], x[:, 1], c=y)
# 绘制散点图
plt.show()生成的散点图如下:
2.方法实现
def kmeans(datas, num, threshold, maximum):
# datas:输入数据;
# num:聚类个数;
# threshold:阈值;
# maximum:最大迭代次数
# result:最后聚类的结果
result = np.zeros(len(datas))
# 初始化result,np.zeros返回来一个给定形状和类型的用0填充的数组,即一个由200个0组成的一维数组
# centre:聚类中心
centre = np.random.random((num, len(datas[0])))
# 返回一个num行2列的浮点数,浮点数都是从0-1之间随机取值,维度是2
for i in np.arange(0, maximum):
# 聚类:
result = classify(datas, centre)
# 对于每一次聚类求中心点:
centre1 = centralization(datas, result, centre)
# 欧氏距离:
dis = distance(centre, centre1)
if dis < 0:
break
centre = centre1
print(centre.shape)
return result
更新聚类归属:
def classify(datas, centre):
d = np.zeros((len(datas), len(centre)))
# 输出结果:
# len(datas)=200; len(centre))=num(聚类个数),即d是一个200*num的数组
for i in np.arange(0, len(datas)):
# 一共200个点,每一个点就都要经过聚类
for j in np.arange(0, len(centre)):
# @矩阵乘法:
d[i][j] = (datas[i] - centre[j]) @ (datas[i] - centre[j])
# 样本和各个质心的距离
result = np.argmin(d, axis=1)
# 返回向量中的最小值的索引,可以按行返回或者按列返回,axis=1按行取最小值,即取得距离哪一个类的距离最近
return result求和阈值比较的那个数字:
def distance(datas, centre):
d = np.zeros((len(datas), len(centre)))
# 和上面一样
for i in np.arange(0, len(datas)):
for j in np.arange(0, len(centre)):
d[i][j] = (datas[i] - centre[j]) @ (datas[i] - centre[j])
return np.sqrt(np.sum(d))
# np.sqrt返回一个非负平方根;np.sum对d里面的元素求和更新聚类中心,返回一个新的聚类中心:
def centralization(datas, result, centre):
centre = np.zeros(centre.shape)
# centre.shape输出结果为(3,2),即生成一个3*2的数组
for i, n in zip(result, np.arange(0, len(result))):
# 用序列解包同时遍历多个序列
# https://www.cnblogs.com/Apy-0816/p/11100248.html
centre[i] = centre[i] + datas[n]
for i in np.arange(0, len(centre)):
a = np.sum(result == i)
centre[i] = centre[i] / a
# 更新聚类中心
return centreresult = kmeans(x, 3, 2, 50)
# 输入数据
print(result)
# 打印
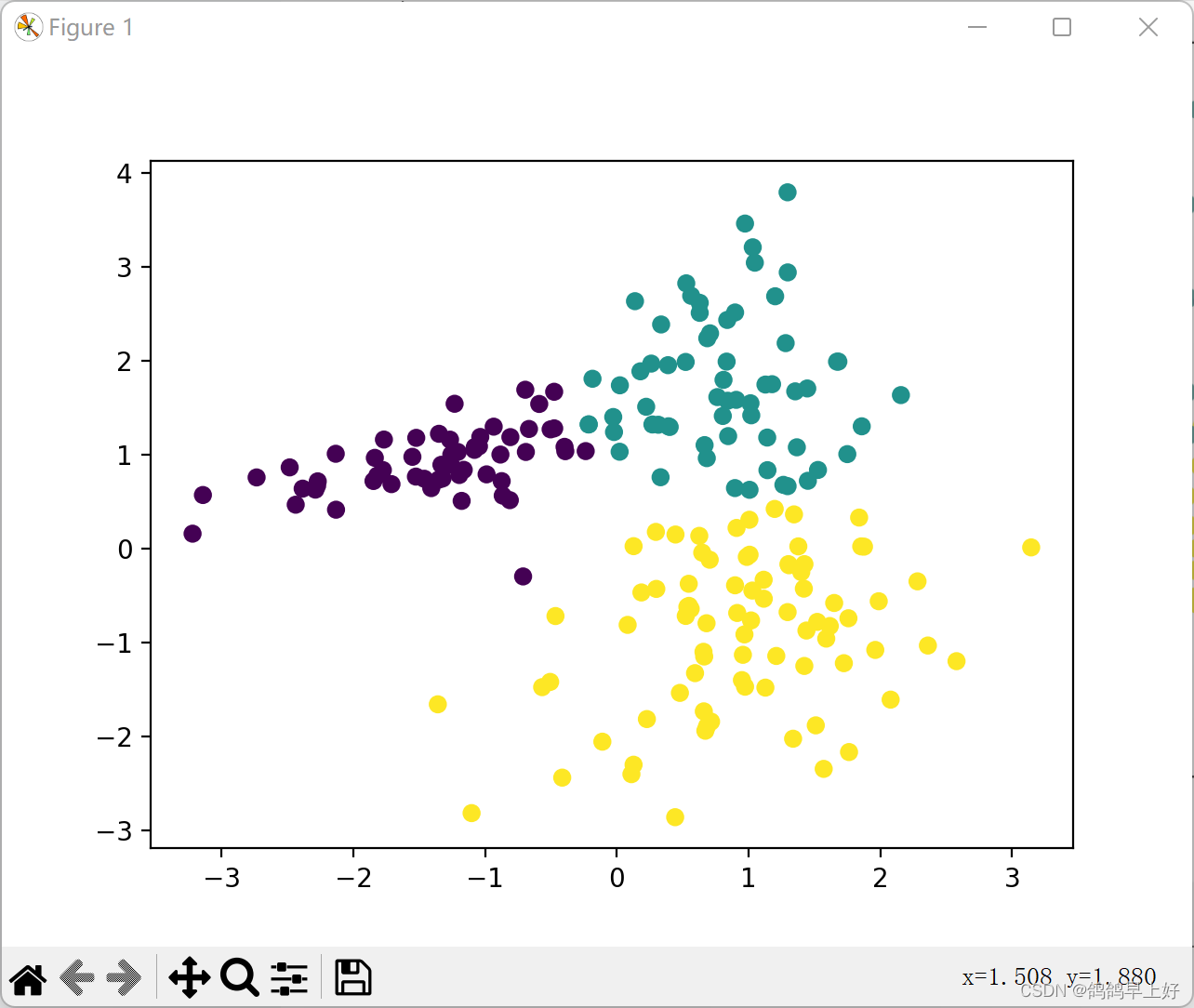
plt.scatter(x[:, 0], x[:, 1], c=result)
plt.show()
# 输出
(四).运行结果
(五).实验问题
一开始运行的时候,发现如下报错:

经过查找,发现是使用np.zeros()错误,是因为zeros()的第一个参数是决定数组的规格的,而第二参数是决定数据类型的,改正后的正确代码如下:
d = np.zeros((len(datas), len(centre)))
即添加双重括号即可解决。

















 842
842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











