







Flume知识点讲解主要从以下几个问题及解答展开
1、Flume概述
Flume是Cloudera提供的一个高可用的、分布式的海量日志采集、聚合和传输的系统,后被捐献给开源软件基金会组织Apache,现已发展成为其顶级项目。其分为两个版本:初始发行版Flume-OG和重构版本Flume-NG。这里介绍一下两者的区别:
1)OG版本中有Master的概念、依赖于Zookeeper,而NG版本中摒弃了Master的概念、 取消了对Zookeeper达到依赖
2)OG和NG版本中Agent功能不一样,组成结构也不一样,OG版本中的Agent用于采集数据,并将数据传输给collector,而NG版本中去掉了collector
3)NG是插件化的,一部分面对用户,工具或系统·开发人员
4)NG使用Thrift、Avro Flume sources可以从Flume0.9.4发送events到Flume1.x
2、什么是Agent,组件有哪些
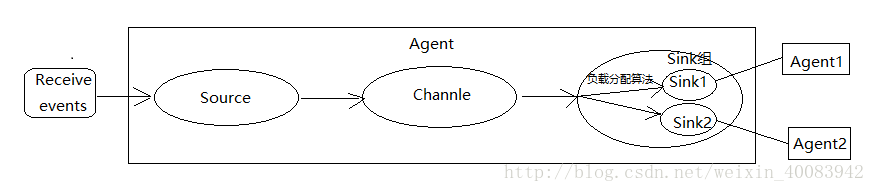
3、支持的拓扑结构有哪些,该怎么实现负载均衡
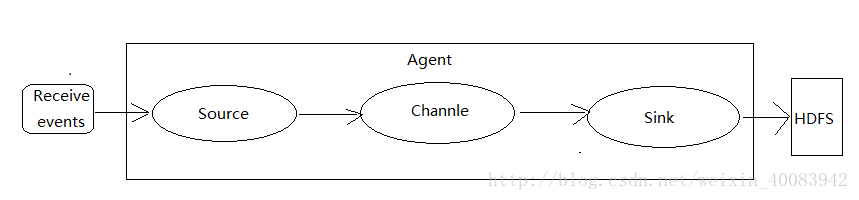
注意:Agent也可以多级相连,比如前两个Agent将数据传输到同一个Agent
实现负载均衡:每台服务器可以运行一个Agent,但是一个Agent里面可以有多个Source和Sink。当Source组里的event流经Channel组,然后进入Sink组,在Sink组内部通过负载均衡算法组中的Sink,接下来就可以选择不同机器上的Agent实现负载均衡。如下图:
4、该怎么选择source、channel、sink
Source、Channel和Sink之间耦合度低,可以相互之间灵活组合使用。在我之前的项目使用了三个Flume,其中第一、二用来采集日志并将数据传输给第三个Flume,第三个Flume的作用就是用来合并日志。这就是Flume中Source、Channel和Sink的灵活使用和选择。
5、怎么设计拓扑结构以达到高可用
6、如何自己开发拦截器来实现我们特殊的要求,比如区分日志、均匀的写kafka分区
7、写kafka是同步写还是异步写
8、Flume配置文件
Flume配置文件,参考官网
# example.conf: A single-node Flume configuration # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1















 481
481











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









