








环境
1.首先在linux环境下载python3和scrapy
下载及解压压缩包 Python-3.x.x.tgz,3.x.x 为你下载的对应版本号
# tar -zxvf Python-3.6.1.tgz
# cd Python-3.6.1
# ./configure
# make && make install
# python3 -V
Python 3.6.1
添加环境变量 详情查看https://www.runoob.com/python3/python3-install.html
安装 Scrapy
pip3 install scrapy
新建项目
scrapy startproject lj_sz
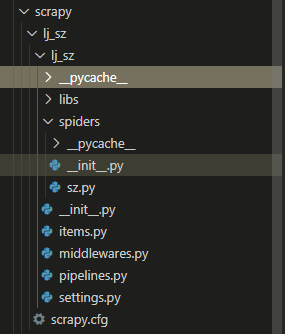
2.下面大致介绍这些目录和文件的作用:
scrapy.cfg:项目的总配置文件,通常无须修改。
lj_sz:项目的 Python 模块,程序将从此处导入 Python 代码。
lj_sz/items.py:用于定义项目用到的 Item 类。Item 类就是一个 DTO(数据传输对象),通常就是定义 N 个属性,该类需要由开发者来定义。
lj_sz/pipelines.py:项目的管道文件,它负责处理爬取到的信息。该文件需要由开发者编写。
lj_sz/settings.py:项目的配置文件,在该文件中进行项目相关配置。
lj_sz/spiders:在该目录下存放项目所需的蜘蛛,蜘蛛负责抓取项目感兴趣的信息。3.定义 items.py 类,该类仅仅用于定义项目需要爬取的 N 个属性:
import scrapy
class LjSzItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
total_price = scrapy.Field()
unit_price = scrapy.Field()
trade_time = scrapy.Field()
region = scrapy.Field()
location = scrapy.Field()
url = scrapy.Field()4.编写 Spider 类
Scrapy 为创建 Spider 提供了 scrapy genspider 命令,该命令的语法格式如下
scrapy genspider [options] <name> <domain>
在命令行窗口中进入 ZhipinSpider 目录下,然后执行如下命令即可创建一个 Spider:
scrapy genspider sz "sz.lianjia.com"运行上面命令,即可在 lj_sz 项目的 lj_sz/spider 目录下找到一个 sz.py 文件 ,编辑sz.py
import scrapy
from lj_sz.items import LjSzItem
from bs4 import BeautifulSoup
import sys
import json
import re
class SzSpider(scrapy.Spider):
name = 'sz'
allowed_domains = ['sz.lianjia.com']
start_urls = [
'https://sz.lianjia.com/chengjiao/luohuqu/pg1',
'https://sz.lianjia.com/chengjiao/futianqu/pg1',
'https://sz.lianjia.com/chengjiao/nanshanqu/pg1',
'https://sz.lianjia.com/chengjiao/yantianqu/pg1',
'https://sz.lianjia.com/chengjiao/baoanqu/pg1',
'https://sz.lianjia.com/chengjiao/longgangqu/pg1',
'https://sz.lianjia.com/chengjiao/longhuaqu/pg1',
'https://sz.lianjia.com/chengjiao/guangmingqu/pg1',
'https://sz.lianjia.com/chengjiao/pingshanqu/pg1',
'https://sz.lianjia.com/chengjiao/dapengxinqu/pg1',
]
def parse(self, response):
item = LjSzItem()
# print(response.request.url)
for li in response.xpath('/html/body/div[5]/div[1]/ul//li'):
item['region'] = [self.getRegion(response)]
url = li.xpath('./div/div[@class="title"]/a/@href').extract_first()
print(url)
if url:
# 请求详情页
yield scrapy.Request(
url,
callback=self.detail_parse,
meta={"item": item}
)
# # 下一页递归爬
new_links = response.xpath('//div[contains(@page-data, "totalPage")]/@page-data').extract()
totalPage = json.loads(new_links[0])['totalPage']
nowPage = json.loads(new_links[0])['curPage']
# print('页数情况',totalPage)
print('当前------------------------------页',nowPage)
print()
if nowPage < totalPage :
now_url = response.request.url
urlList = now_url.split('/pg')
# next_url = 'https://sz.lianjia.com/chengjiao/dapengxinqu/pg' + str(nowPage+1) + '/'
next_url = urlList[0] + '/pg' + str(nowPage+1) + '/'
yield scrapy.Request(next_url,meta={
'dont_redirect': True,
'handle_httpstatus_list': [301,302],
'item':item
}, callback=self.parse)
def getRegion(self, response):
regionList = ['luohuqu','futianqu','nanshanqu','yantianqu','baoanqu','longgangqu','longhuaqu','guangmingqu','pingshanqu','dapengxinqu']
regionMap = {
'luohuqu' : '罗湖区',
'futianqu' : '福田区',
'nanshanqu': '南山区',
'yantianqu': '盐田区',
'baoanqu' : '宝安区',
'longgangqu': '龙岗区',
'longhuaqu': '龙华区',
'guangmingqu': '光明区',
'pingshanqu': '坪山区',
'dapengxinqu': '大鹏新区',
}
for region in regionList:
if region in response.request.url:
return regionMap[region]
return None
# 爬取详情页数据
def detail_parse(self, response):
# 接收上级已爬取的数据
item = response.meta['item']
#一级内页数据提取
originHtml = response.xpath("/html/body/script[11]/text()").extract()[0]
originHtml = str(originHtml)
location = re.findall(r"resblockPosition:'(.*)'", originHtml)
item['location'] = location
item['total_price'] = response.xpath('/html/body/section[1]/div[2]/div[2]/div[1]/span/i/text()').extract()
item['title'] = response.xpath('/html/body/div[4]/div/text()').extract()
item['unit_price'] = response.xpath('/html/body/section[1]/div[2]/div[2]/div[1]/b/text()').extract()
item['trade_time'] = response.xpath('/html/body/div[4]/div/span/text()').extract()
item['url'] = [response.request.url]
# 二级内页地址爬取
# yield scrapy.Request(item['url'] + "&123", meta={'item': item}, callback=self.detail_parse2)
# 有下级页面爬取 注释掉数据返回
yield item5. 修改pipeline类
这个类是对爬取的文件最后的处理,一般为负责将所爬取的数据写入文件或数据库中.
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pandas as pd
import pymysql
class LjSzPipeline:
def process_item(self, item, spider):
scrapyData = []
# 链接数据库
conn=pymysql.connect('127.0.0.1','***','******')
# 选择数据库
conn.select_db('ectouch')
cur=conn.cursor()
sql="insert into lj_sz_scrapy (city_desc,region, title, trade_time, total_price,total_unit,unit_price,unit_unit,location,url) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)";
self.getData(item,scrapyData)
print(scrapyData)
try:
# 执行sql语句
insert=cur.executemany(sql,scrapyData)
print ('批量插入返回受影响的行数:',insert)
# 提交到数据库执行
conn.commit()
except:
# 如果发生错误则回滚
conn.rollback()
print ('错误')
conn.close()
# print("title:",item['title'])
# print("url:",item['url'])
# print("total_price:",item['total_price'])
# print("unit_price:",item['unit_price'])
# print("trade_time:",item['trade_time'])
# print("region:",item['region'])
# print("location:",item['location'])
print('============='*10)
return
def getData(self, item, scrapyData):
df = pd.DataFrame({"city_desc": '深圳', "region": item['region'], "title": item["title"],"trade_time":item["trade_time"],
"total_price":item["total_price"],"total_unit":'万',"unit_price":item['unit_price'],"unit_unit":'元/平',"location":item['location'],"url":item['url']})
def reshape(r):
scrapyData.append(tuple(r))
df.apply(reshape,axis=1)
return
# mysql表结构
# CREATE TABLE `lj_sz_scrapy` (
# `id` int(10) unsigned NOT NULL AUTO_INCREMENT,
# `city_desc` varchar(155) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT '城市',
# `region` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT '区',
# `title` varchar(155) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT '标题',
# `trade_time` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT '交易时间',
# `total_price` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '0.00' COMMENT '总价',
# `total_unit` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT '总价单位',
# `unit_price` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '0.00' COMMENT '单价',
# `unit_unit` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT '单价单位',
# `location` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT 'location',
# `url` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT 'url',
# `created_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
# `updated_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
# `x` decimal(10,5) NOT NULL DEFAULT '0.00000' COMMENT 'x',
# `y` decimal(10,5) NOT NULL DEFAULT '0.00000' COMMENT 'y',
# PRIMARY KEY (`id`),
# KEY `title` (`title`) USING BTREE
# ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci; 6.修改settings类
ROBOTSTXT_OBEY = False// 改为false
DEFAULT_REQUEST_HEADERS = {
"User-Agent" : "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0",
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
DOWNLOAD_DELAY = 0.5// 人性化点别太快
DOWNLOADER_MIDDLEWARES = {
'lj_sz.middlewares.LjSzDownloaderMiddleware': 543,
}
ITEM_PIPELINES = {
'lj_sz.pipelines.LjSzPipeline': 300,
}
HTTPERROR_ALLOWED_CODES = [301]7.更改代理防止ip被封
购买快代理 https://www.kuaidaili.com/usercenter/tps/
class LjSzDownloaderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
# #设置代理 快代理购买隧道代理
proxy = 'tps156.kdlapi.com:15818'
user_password = 'XXXXXXXXX:XXXX'
b64_user_password = base64.b64encode(user_password.encode('utf-8'))
proxyAuth = 'Basic' + b64_user_password.decode('utf-8')
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
request.headers['User-Agent'] = random.choice(self.user_agents)
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
#消除关闭证书验证的警告
urllib3.disable_warnings();
request.meta['proxy'] = self.proxy
request.headers['Proxy-Authorization'] = self.proxyAuth
# return request
# return None
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)e8.执行
scrapy crawl sz
9.结果

动态ip获取https://www.kuaidaili.com/usercenter/overview/
快代理 隧道代理 https://www.kuaidaili.com/doc/api/
github源码 git@github.com:drt9527/Python3-Scrapy.git















 287
287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









