







数据准备
选择UCI数据集中的Bike Sharing数据集(http://archive.ics.uci.edu/ml/datasets/Bike+Sharing+Dataset)进行实验。
场景:预测共享单车租借数量。
特征:季节、月份、时间(0~23)、节假日、星期、工作日、天气、温度、体感温度、湿度、风速
预测目标:每一小时的单车租用数量
1、下载数据集并打开
终端输入命令
cd ~/pythonwork/PythonProject/data
wget http://archive.ics.uci.edu/ml/machine-learning-databases/00275/Bike-Sharing-Dataset.zip
unzip -j Bike-Sharing-Dataset.zip
cat hour.csv|more
打开hour.csv(以小时为单位的租界数量)
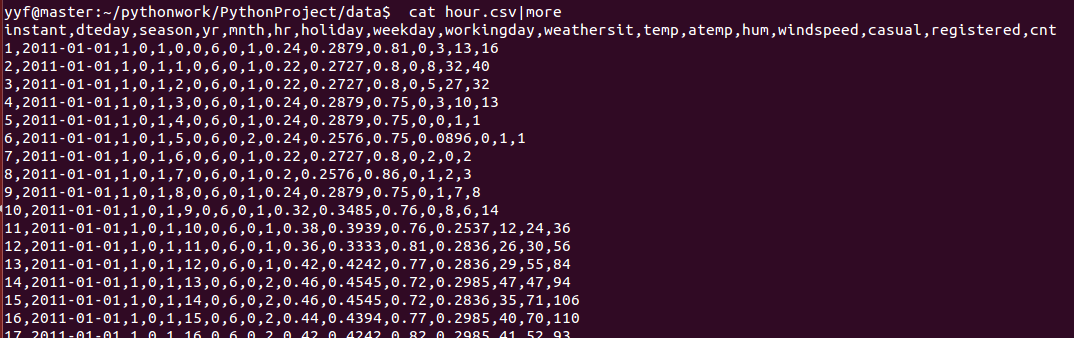
字段说明及相应处理:
- instant:序号,忽略
- dteday:日期,忽略
- season:季节(1: spring、2: summer、3: fall、4: winter),特征字段
- yr:年份(0:2011,1:2012),忽略
- mnth:月份(1~12),特征字段
- hr:时间(0~23)特征字段
- holiday:节假日(0:非节假日,1:节假日),特征字段
- weekday:星期,特征字段
- workingday:工作日,特征字段
- weathersit:天气:1~4表示好天气~恶劣天气分级,特征字段
- temp:摄氏度(除以41标准化),特征字段
- atemp:实际感觉温度(除以50标准化),特征字段
- hum:湿度(除以100标准化),特征字段
- windspeed:风速(除以67标准化),特征字段
- casual:临时会员此时段租借的数量,忽略
- registered:正式会员此时段租借的数量,忽略
- cnt:此时段租借的总数量,预测目标
2、打开IPython/Jupyter Notebook导入数据
终端输入命令运行IPython/Jupyter Notebook
cd ~/pythonwork/ipynotebook
PYSPARK_DRIVER_PYTHON=ipython PYSPARK_DRIVER_PYTHON_OPTS="notebook" MASTER=local[*] pyspark
在IPython/Jupyter Notebook中输入以下命令导入并读取数据:
## 定义路径
global Path
if sc.master[:5]=="local":
Path="file:/home/yyf/pythonwork/PythonProject/"
else:
Path="hdfs://master:9000/user/yyf/"
## 读取hour.tsv
print("开始导入数据...")
rawData = sc.textFile(Path+"data/hour.csv")
header = rawData.first() # 第一行为字段说明行
## 删除第一行
rData = rawData.filter(lambda x: x != header)
## 取出前2项数据
print(rData.take(2))
## 以逗号每一行
lines = rData.map(lambda x: x.split(","))
print("共有:"+str(lines.count())+"项数据")返回结果:

数据预处理
1、处理特征
## 处理特征
## 处理特征
import numpy as np
def convert_float(v):
"""处理数值, 将字符串转化为float"""
return float(v)
def process_features(line):
"""处理特征,line为字段行"""
## 处理季节特征
SeasonFeature = [convert_float(value) for value in line[2]]
## 处理余下的特征
Features = [convert_float(value) for value in line[4:14]]
# 返回拼接的总特征列表
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









