






一、环境
系统版本 centos7.6
docker版本 Docker version 20.10.10
准备文件:
hadoop-3.3.1.tar.gz #hadoop安装包
hadoopfiles.tar.gz #hadoop内部各种配置文件
jdk1.8.0_201.tar.gz #安装java环境
flink-1.13.6-bin-scala_2.12.tgz #flink安装包
scala-2.12.12.tgz #对应的Scala安装包
CentOS7-Base.repo #换源
二、安装docker
三、封装镜像
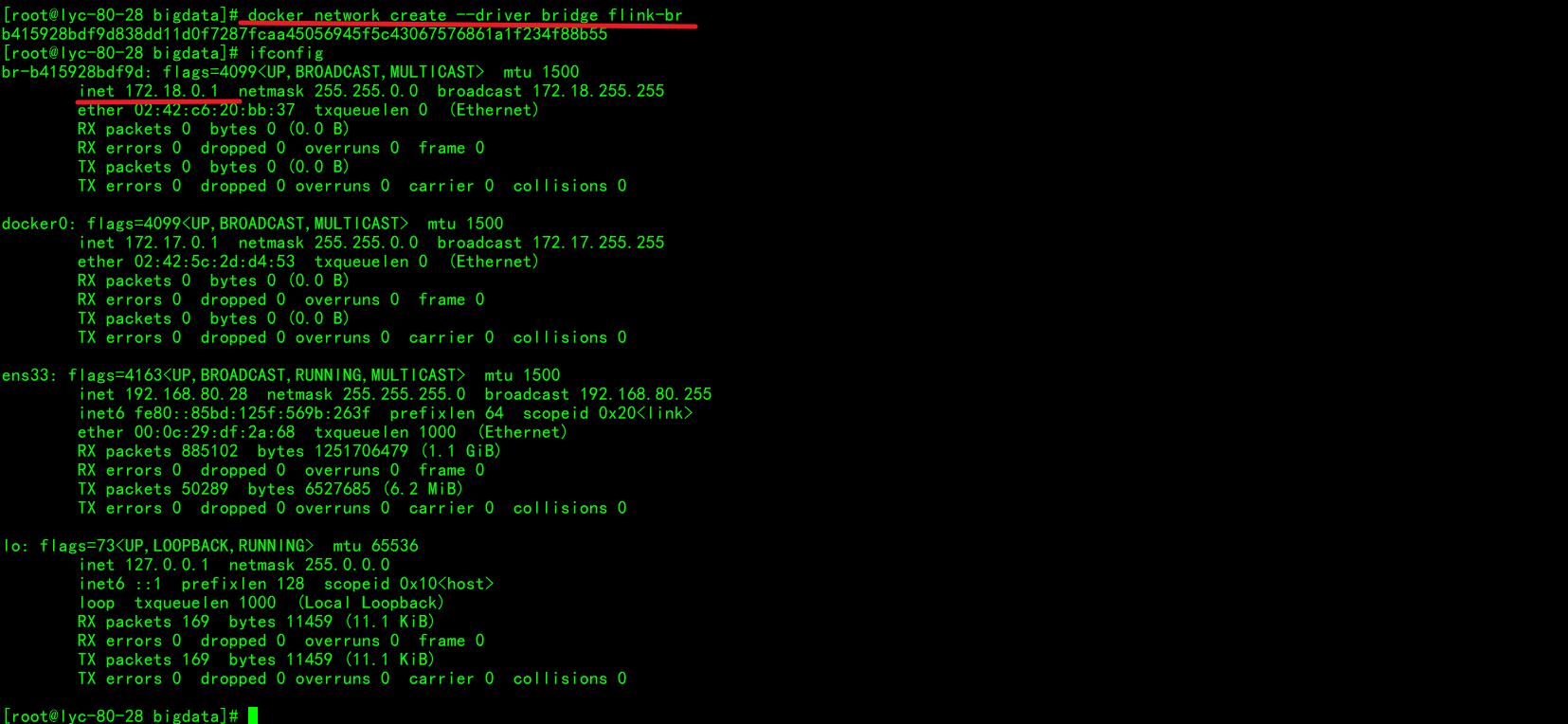
容器换源装包

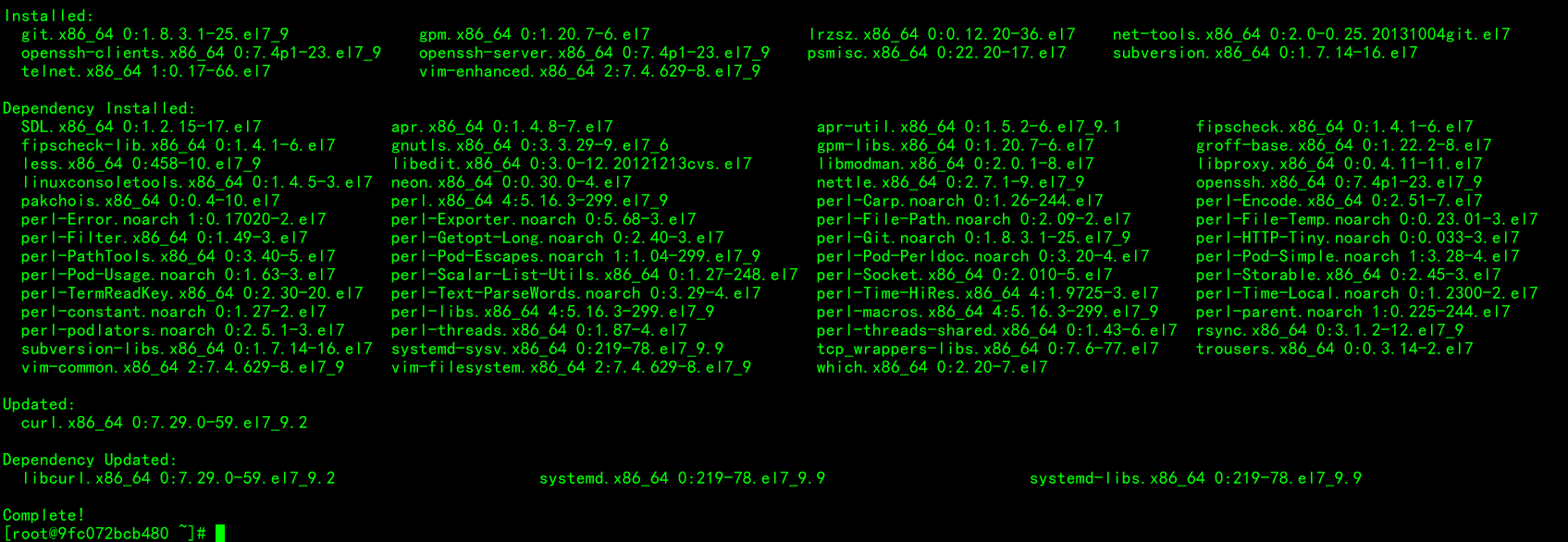
容器开启sshd服务
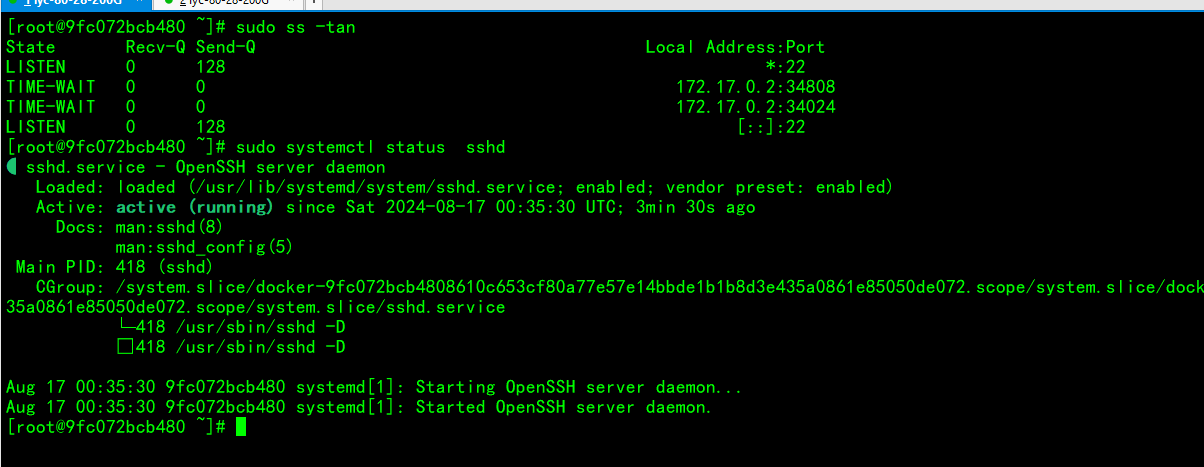
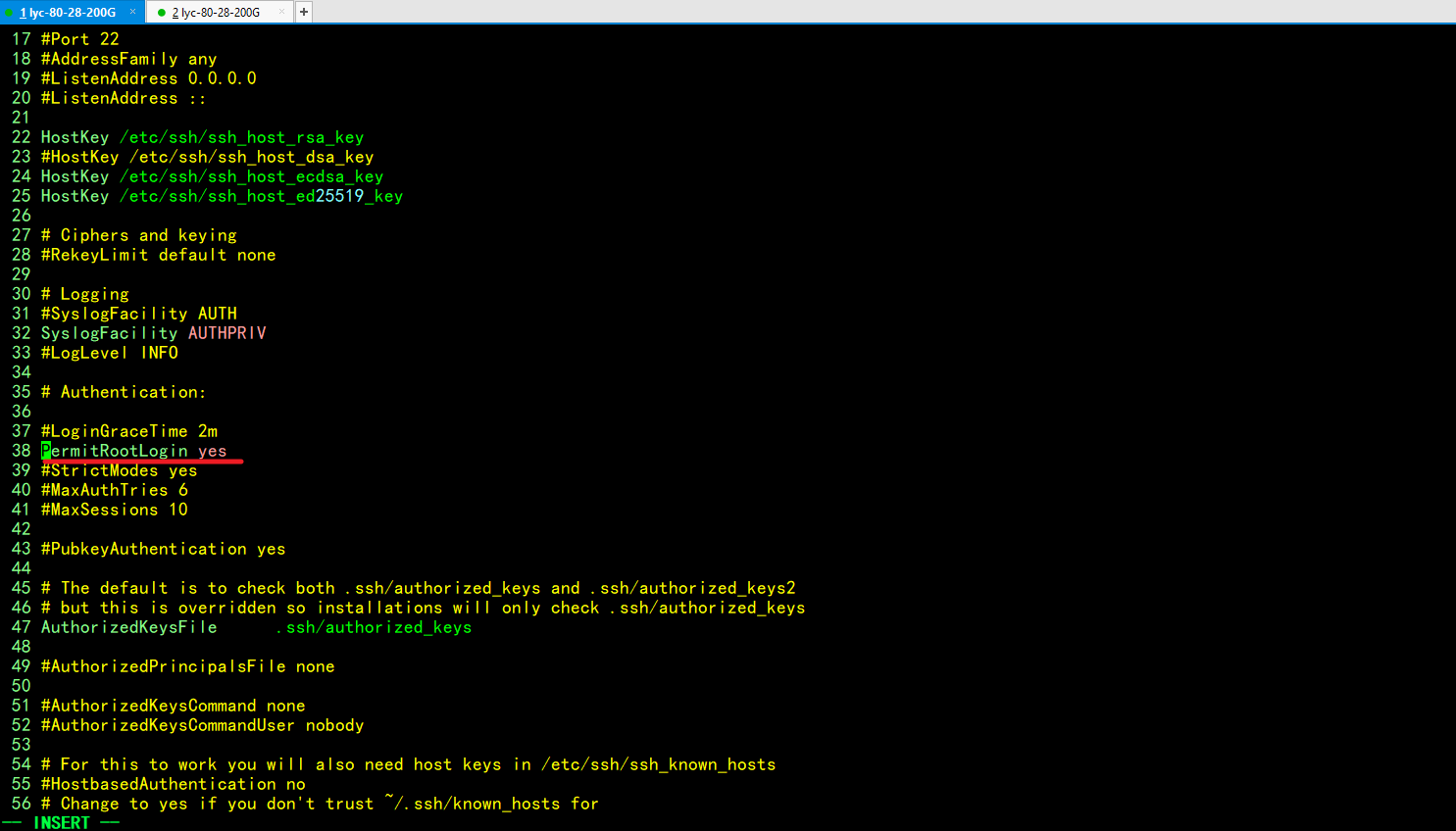
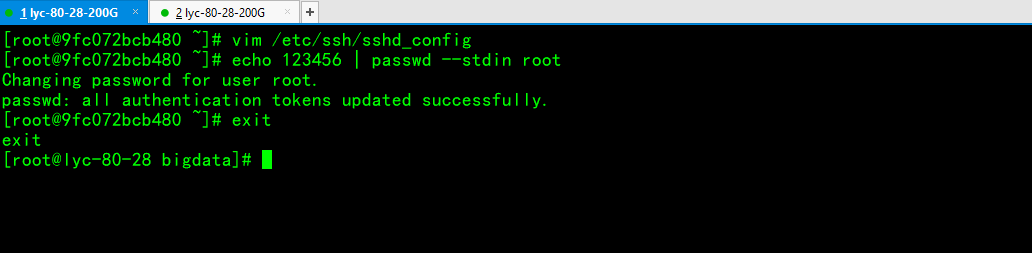
制作centos7-sshd镜像
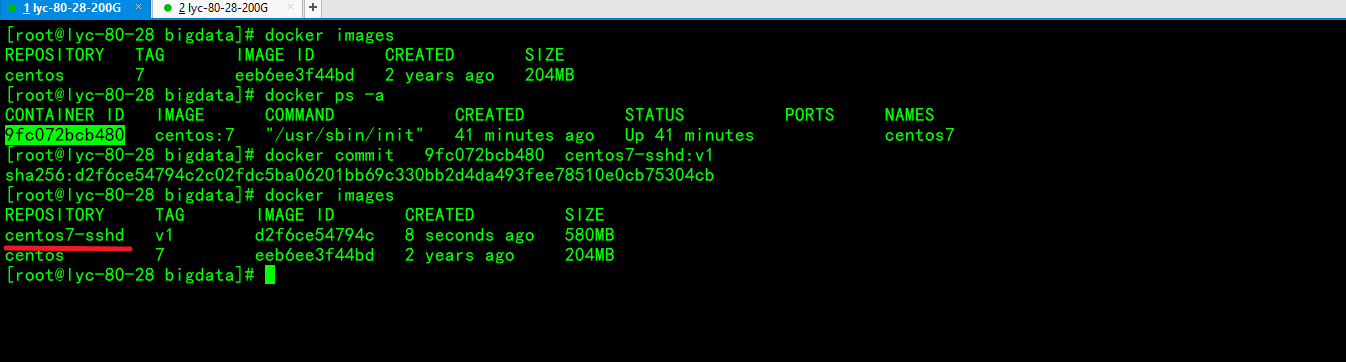
制作centos7-hadoop镜像
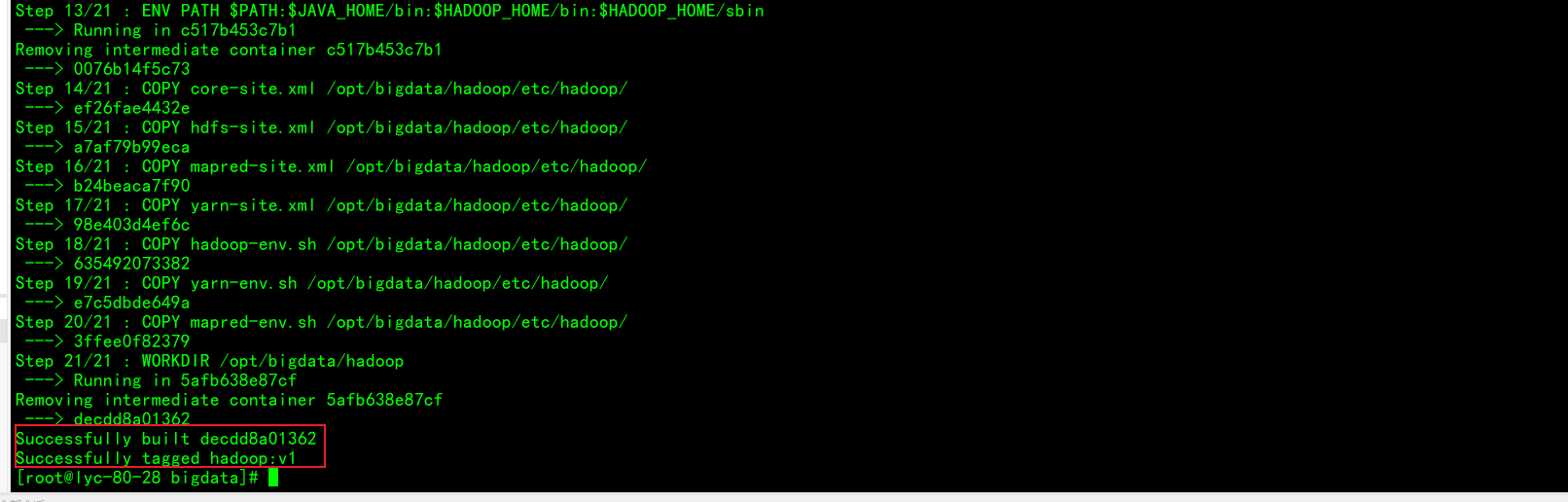
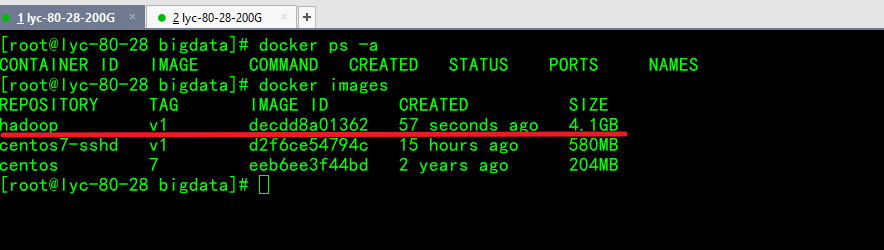
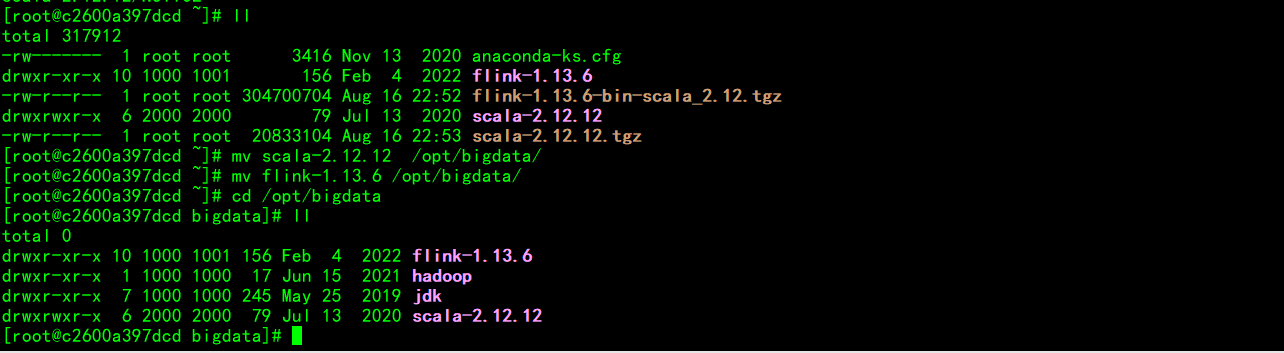
启动刚制作的hadoop镜像

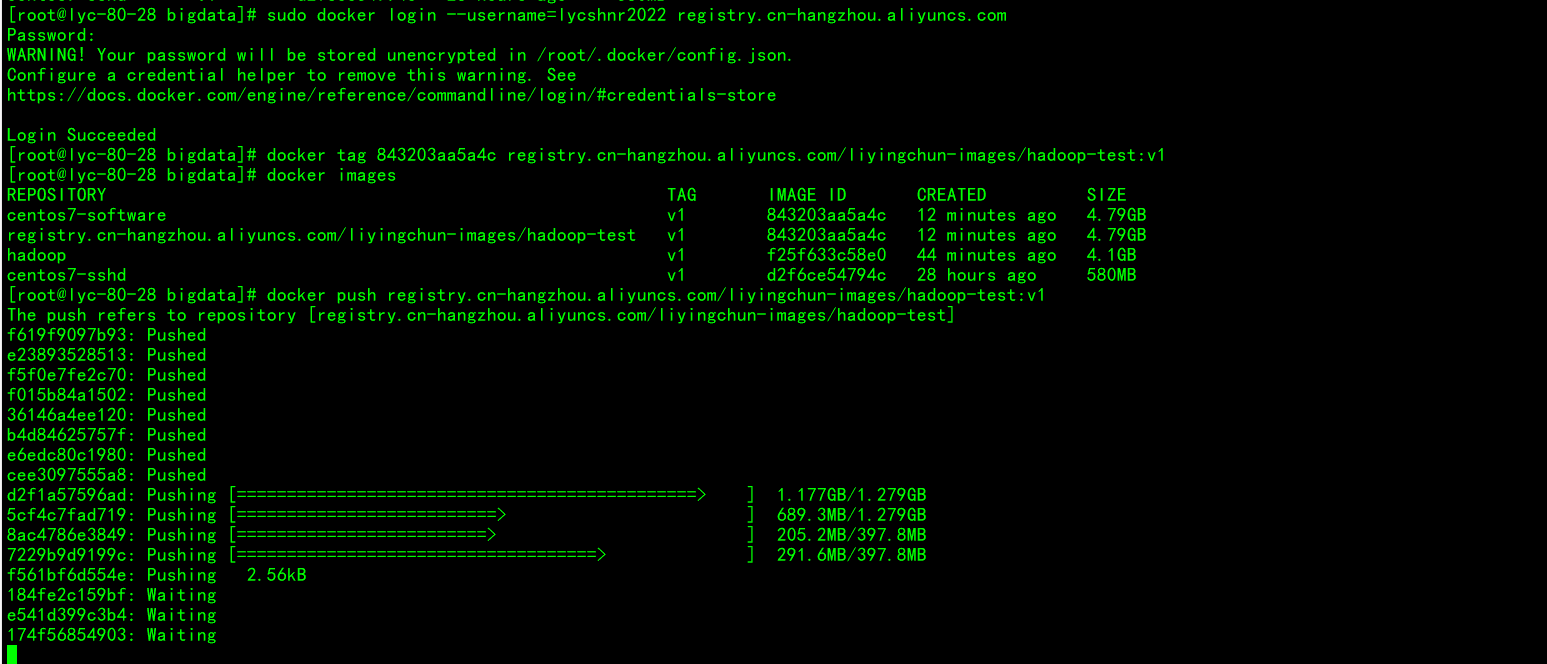
推送镜像到阿里云仓库
至此,咱们的hadoop-flink镜像就制作完毕,下一步就是免密登录,配置hadoop各核心文件参数
四、flink集群实验
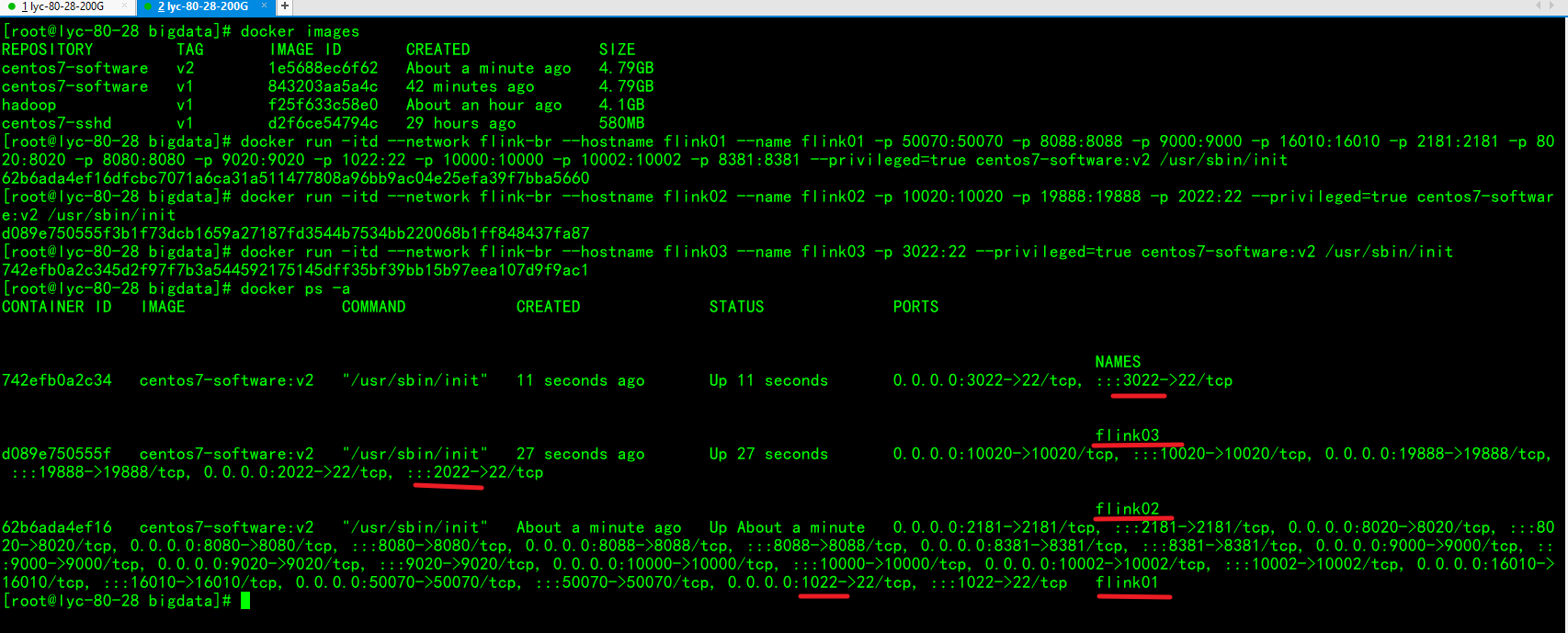
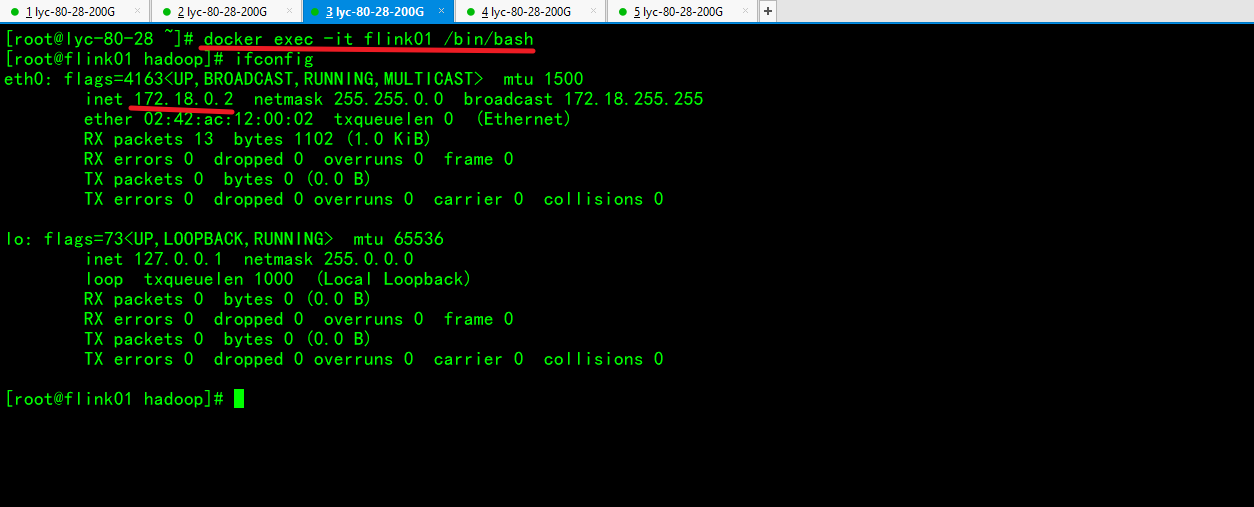
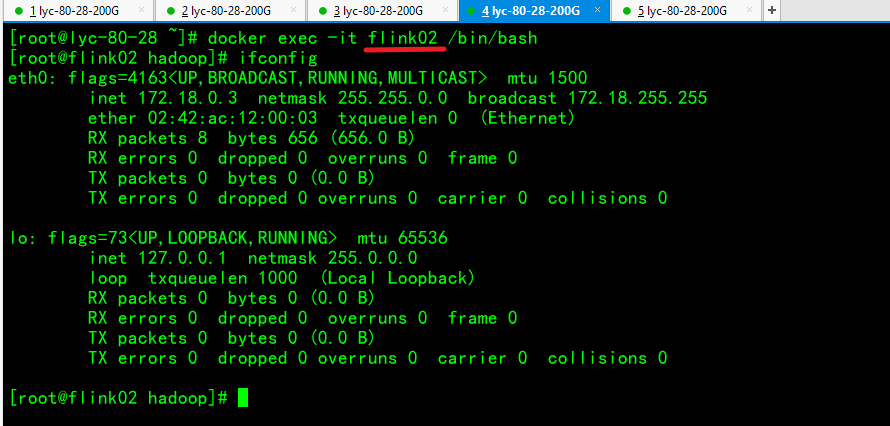
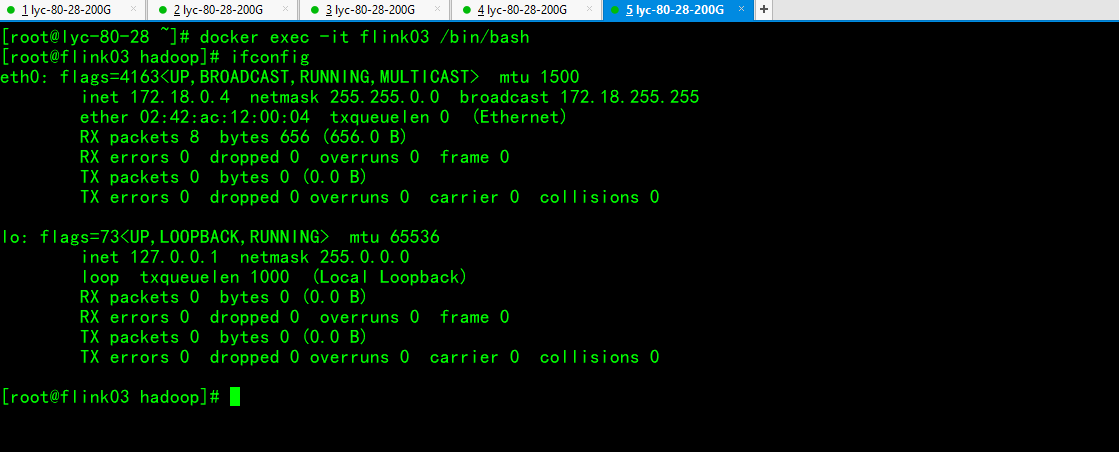
配置免密登录
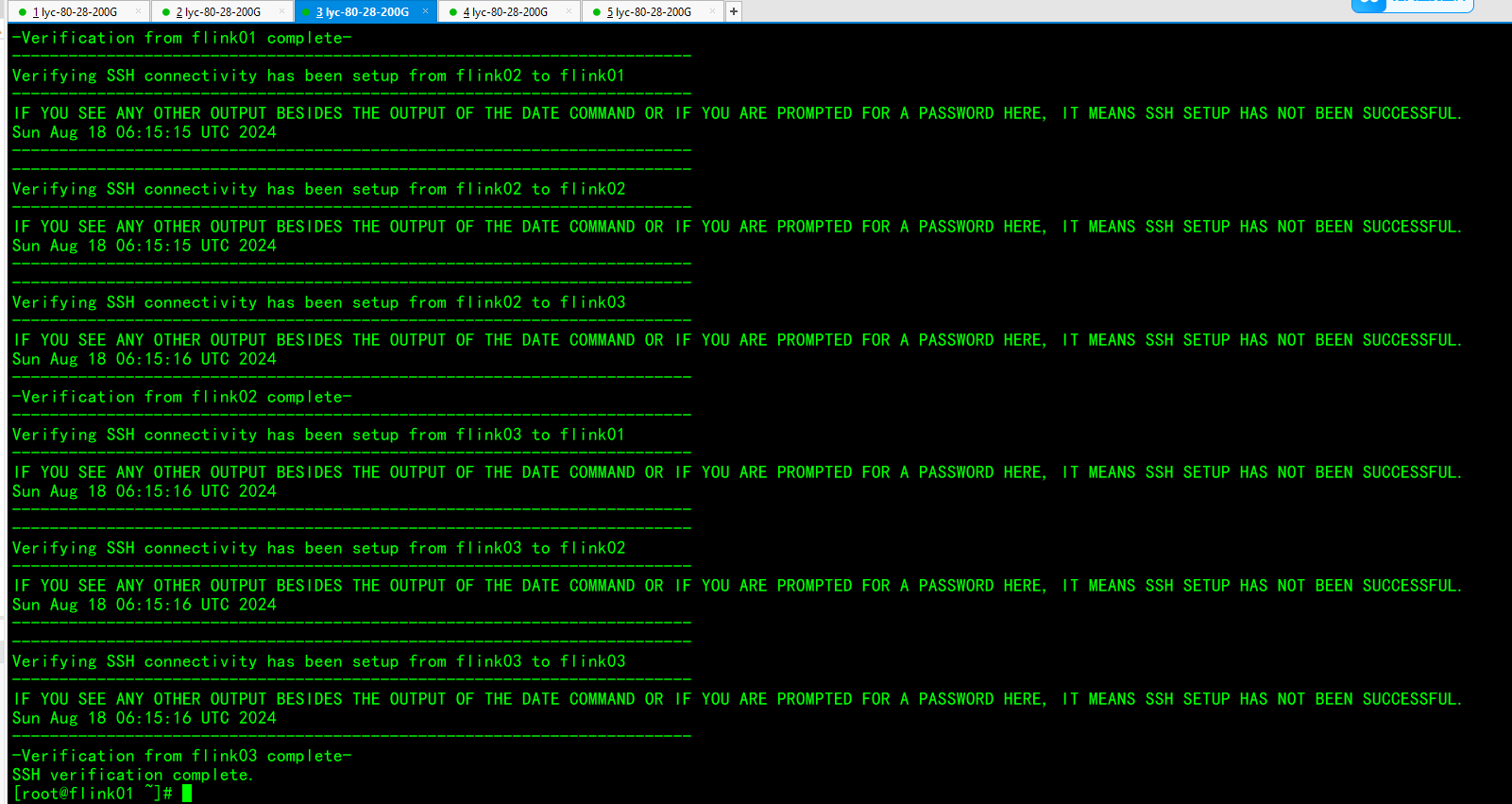
使用脚本进行免密登录设置
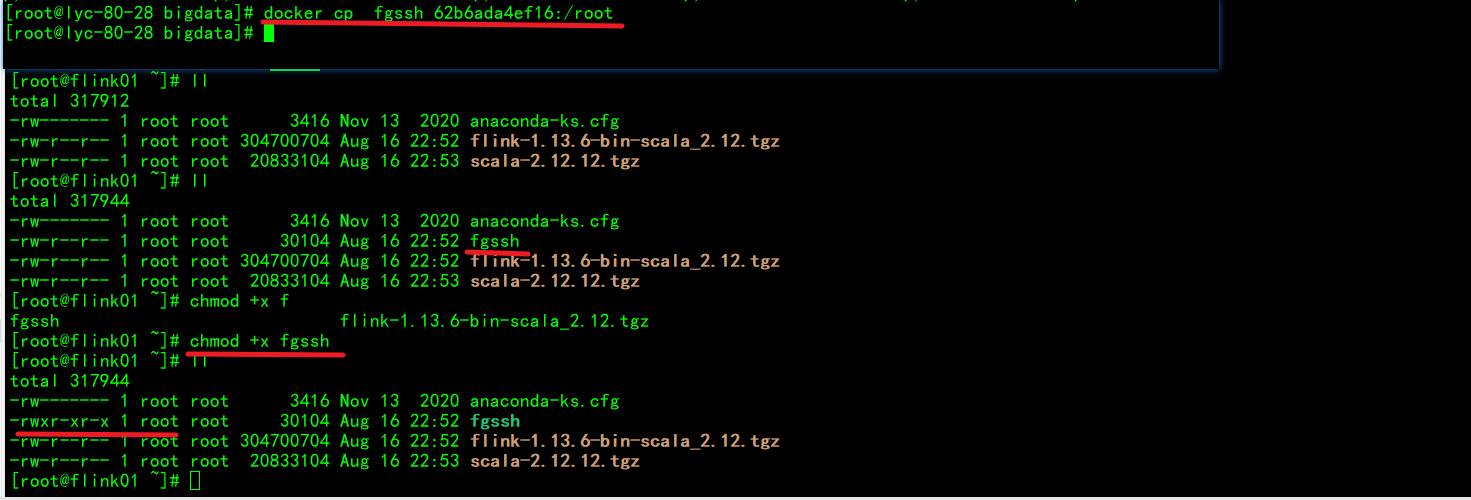


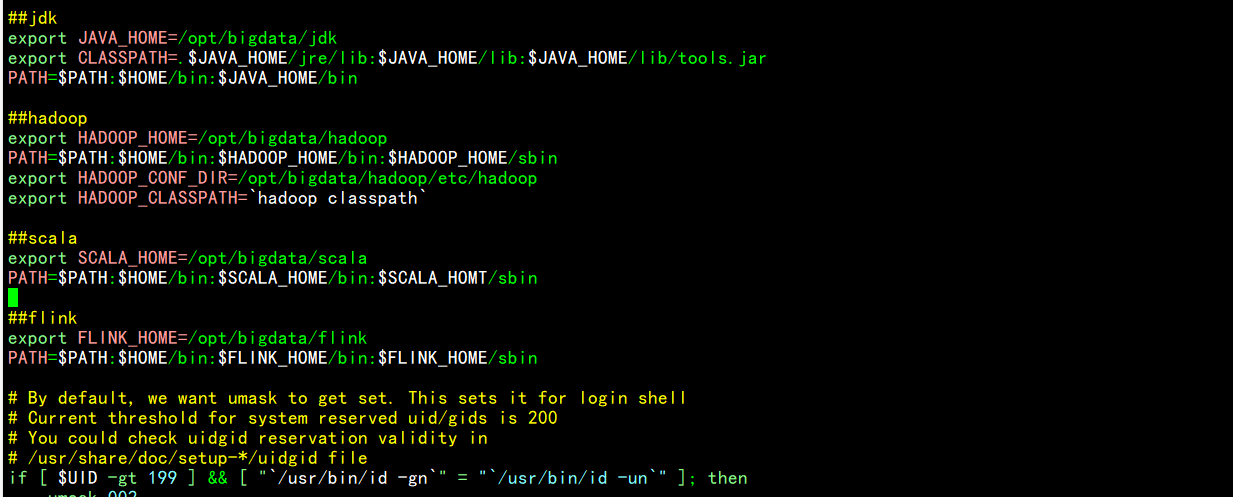
测试环境变量

再次查看hadoop配置文件
集群进行初始化操作
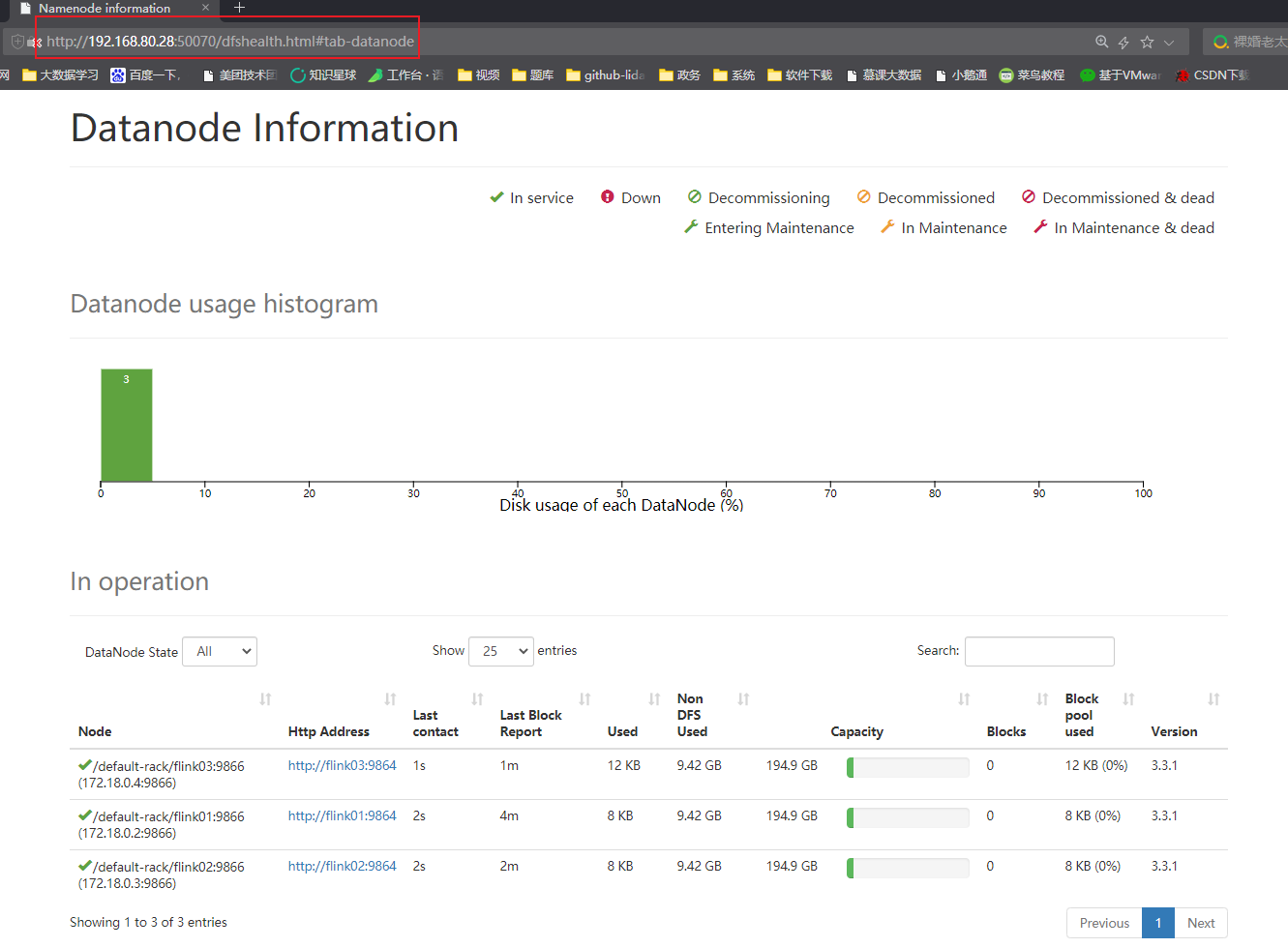
启动集群组件服务

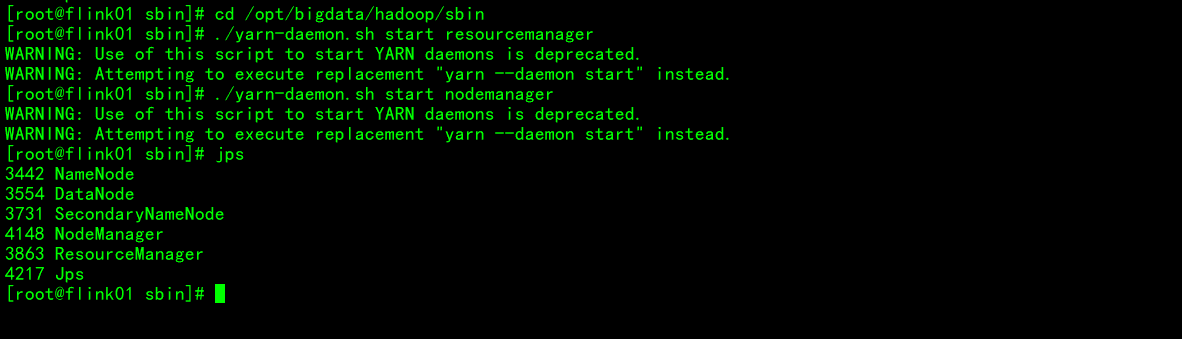
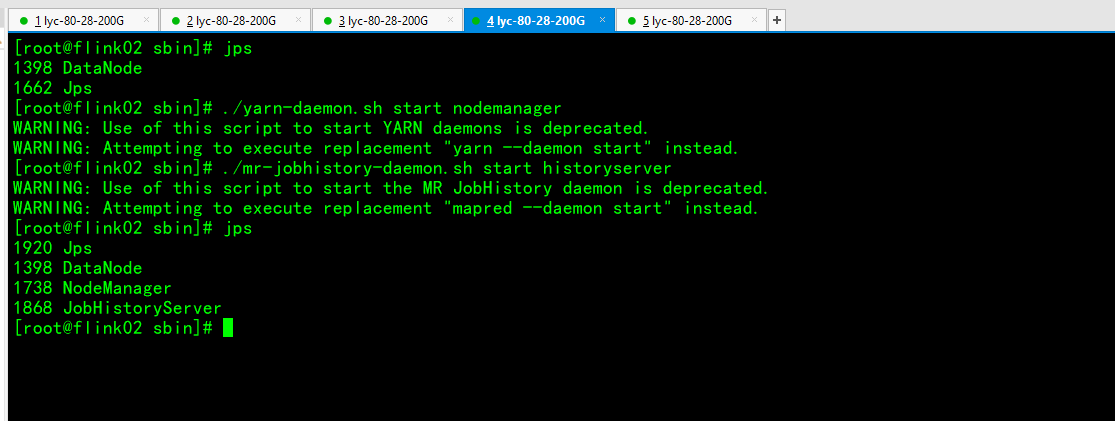
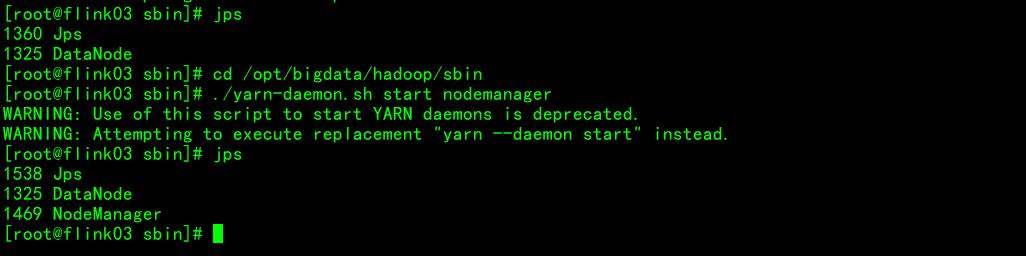
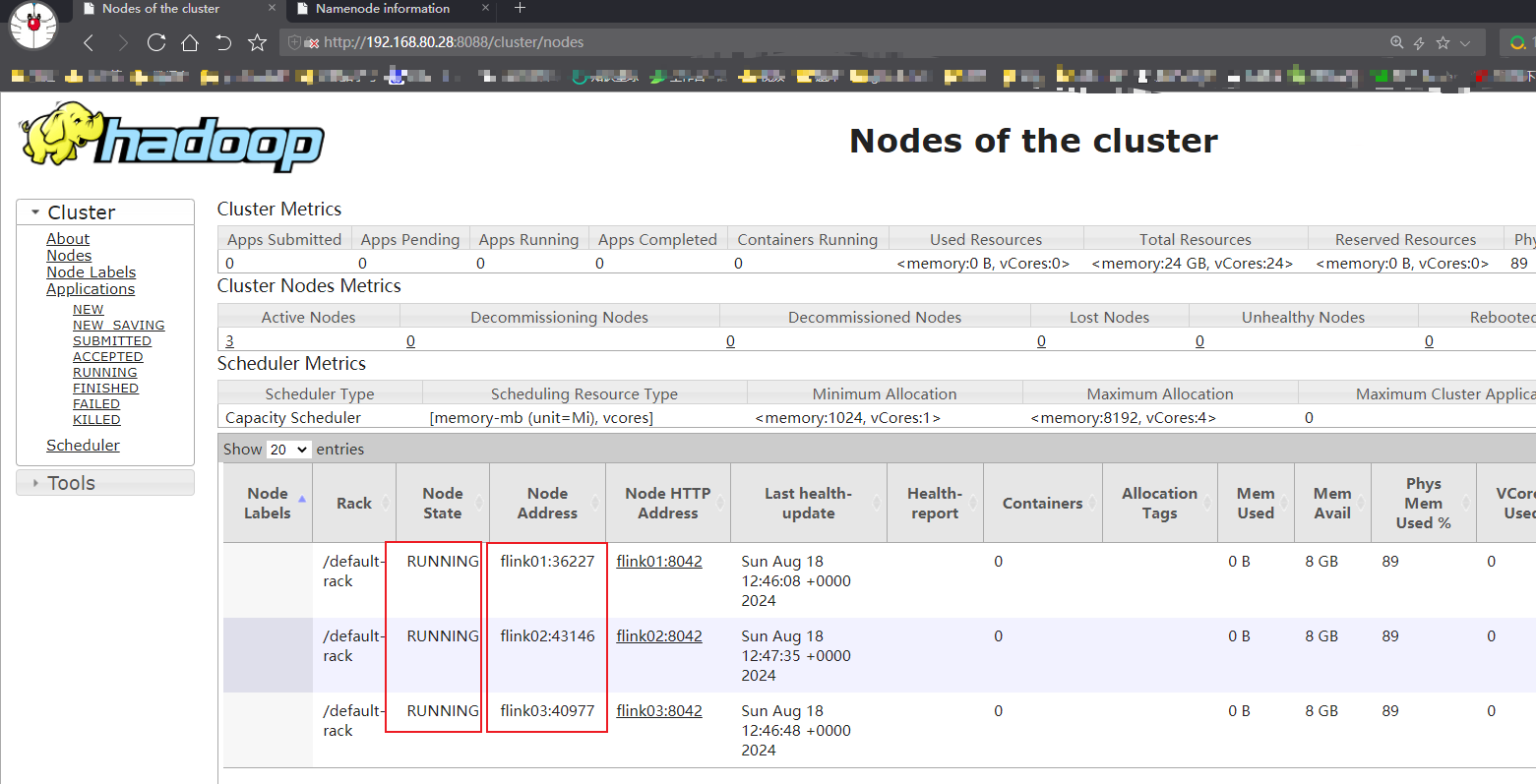
测试flink on yarn
Flink or yarn-session模式
Flink on Yarn-Session 模式指的是在 Yarn 集群中以会话模式运行 Apache Flink 应用程序。在 Session模式下,用户可以创建和维护一个长时间运行的Flink会话,并在该会话中提交多个应用程序,在不同的时间异步地运行它们。这种模式能够充分利用集群资源并提高运行效率。
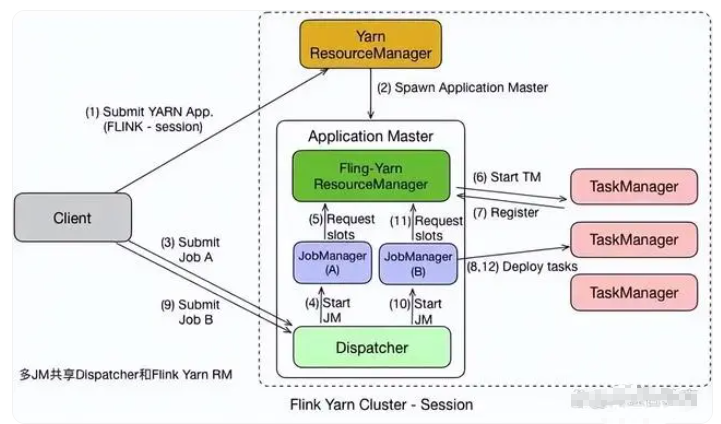
在Session模式下,Flink集群作为长期存在的会话运行,可以被用于提交多个Flink应用程序。
这些应用程序可以共享相同的Flink集群和资源,从而减少了资源占用和管理的负担。
用户可以通过Yarn的管理界面或命令行向Flink集群发送应用程序提交请求。
在接收到提交请求后,Flink会话会根据应用程序的需求分配资源,并启动相应的Flink作业。
在Session模式下,Flink集群和应用程序都可以在同一个Yarn应用程序中运行。对于每个应用程序,Yarn将为该应用程序创建一个不同的容器,容器中会运行一个 Flink TaskManager进程和一个Flink JobManager进程。多个容器中的Flink TaskManager会连接到同一个Flink JobManager,通过该JobManager协调和管理整个Flink集群。
在Flink Session模式中,用户可以通过Web UI或命令行界面来查看每个Flink作业的执行情况、资源使用情况以及日志信息等。同时,Flink支持动态调整任务的资源配置,例如增加某个任务的任务槽数量或内存占用等。
【总结】Flink Session模式是一种长时间运行的Flink集群,可以用于提交多个Flink应用程序,并共享相同的资源和集群。它可以提高资源利用率和运行效率。
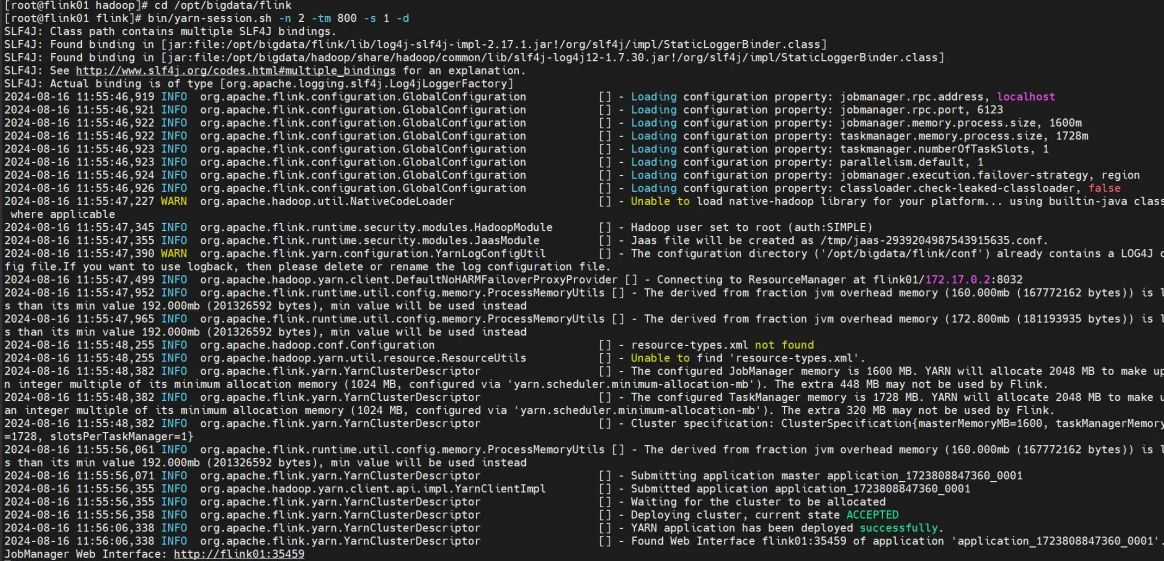

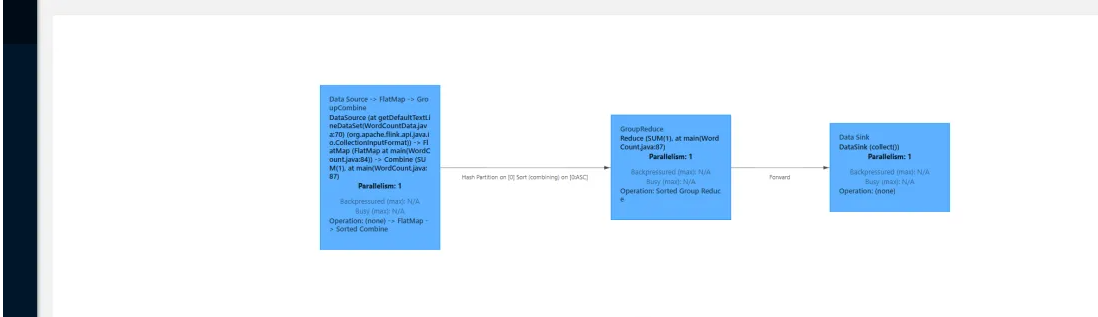
Flink on yarn-Per job模式
Flink on Yarn–Per Job 模式指的是通过向 Yarn 集群提交独立的 Flink 作业来运行 Apache Flink 应用程序。在 Per Job 模式下,每次提交作业时,Flink 会启动一个新的 Flink 集群来运行该作业,作业完成后该集群也会被关闭。这种模式适用于需要独立资源且彼此不相关的场景。
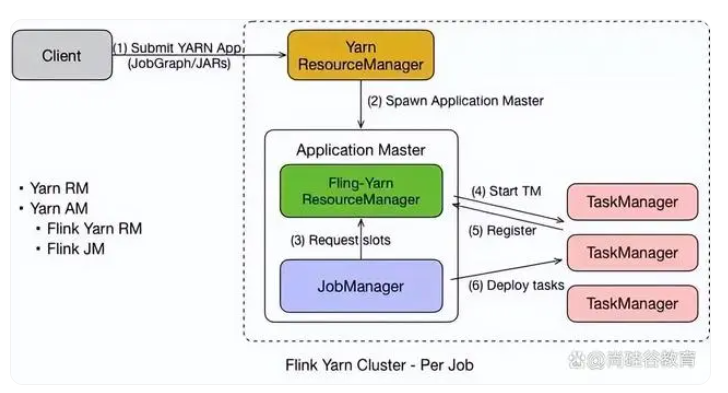
在 Per Job 模式下,用户需要为每个应用程序创建单独的 Yarn 应用程序并调整相应的参数和配置。每个应用程序都会启动一个新的、独立的 Flink 集群,该集群只为当前作业提供资源。
在 Per Job 模式下,Flink 应用程序可以使用 Yarn 集群中的所有可用资源,从而可以充分利用集群资源,并在有限的时间内完成计算任务。
Yarn 的 ResourceManager 会为每个 Flink 作业分配所需的资源,启动相应的容器并进行初始化。
Flink 集群将由一个 JobManager 和多个 TaskManager 组成,它们负责管理和执行传入的作业。
在 Flink Per Job 模式下,用户可以通过 Web UI 或命令行界面来查看每个 Flink 作业的执行情况、资源使用情况以及日志信息等。同时,用户也可以在提交作业之前配置 Flink 集群的参数和资源限制,例如任务槽数量、内存占用等。
【总结】Flink on Yarn–Per Job 模式适用于需要独立资源且彼此不相关的场景。它通过向 Yarn 集群提交独立的 Flink 作业来运行应用程序,并为每个作业启动一个新的 Flink 集群,从而充分利用集群资源,提高了应用程序的计算效率。

集群模式

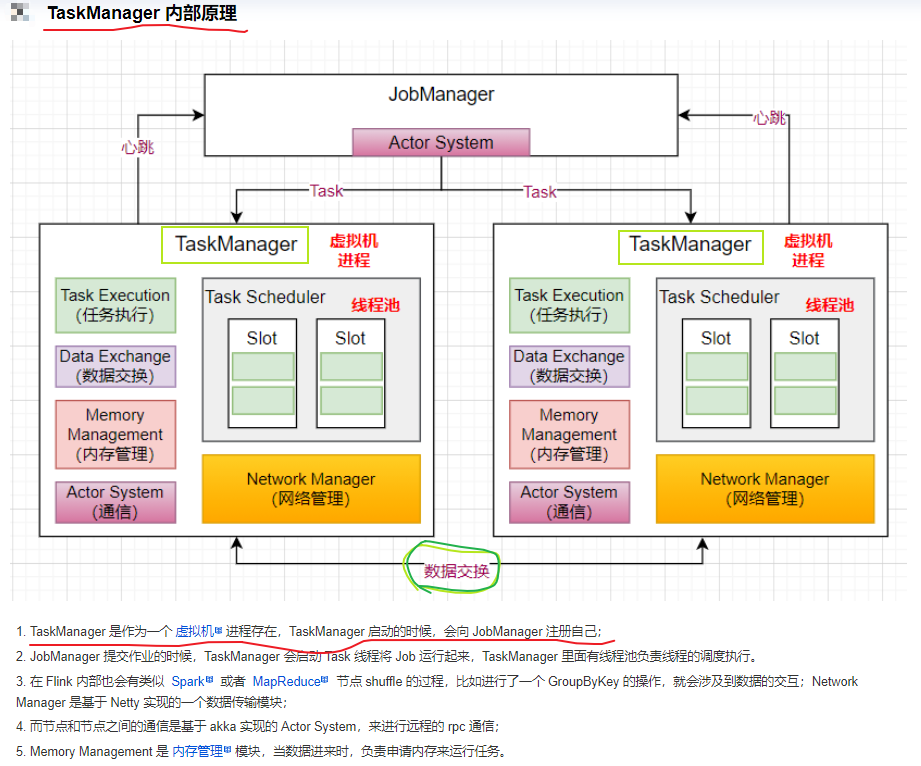



启动集群


















 2896
2896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









