









0、前言
我们先来看一下,spark提交任务的脚本,这里的deploy-mode就是本篇文章的重点,表示着提交模式,分别只有client客户端模式和cluster集群模式
spark-submit
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 1 \
--class org.apache.spark.examples.SparkPi \
${SPARK_HOME}/examples/jars/spark-examples.jar \
1、通用的提交流程
- 启动Driver进程,并向集群管理器注册应用程序
- 集群资源管理器根据任务配置文件分配并启动Executor
- Executor启动之后反向到Driver注册,Driver已经获取足够资源可以运行
- Driver开始执行main函数,Spark查询为懒执行,当执行到action算子时开始反向推算,根据宽依赖进行stage的划分,随后每一个stage对应一个taskset,taskset中有多个task,根据本地化原则,task会被分发到指定的Executor去执行
- 【一个stage的所有task都执行完毕之后,会在各个节点本地的磁盘文件中写入计算中间结果,然后Driver就会调度运行下一个stage。下一个stage的task的输入数据就是上一个stage输出的中间结果】
- Executor在执行期间会不断向Driver进行通信,汇报任务运行情况
2、client提交流程
- Driver在任务提交的本地机器运行,并向Master(资源管理器)注册应用程序
- Master根据submit脚本的资源配置,启用相应的Worker
- 在Worker(节点)上启动所有的Executor,Executor反向到Driver注册
- Driver开始执行main函数,之后执行到Action算子时,开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行
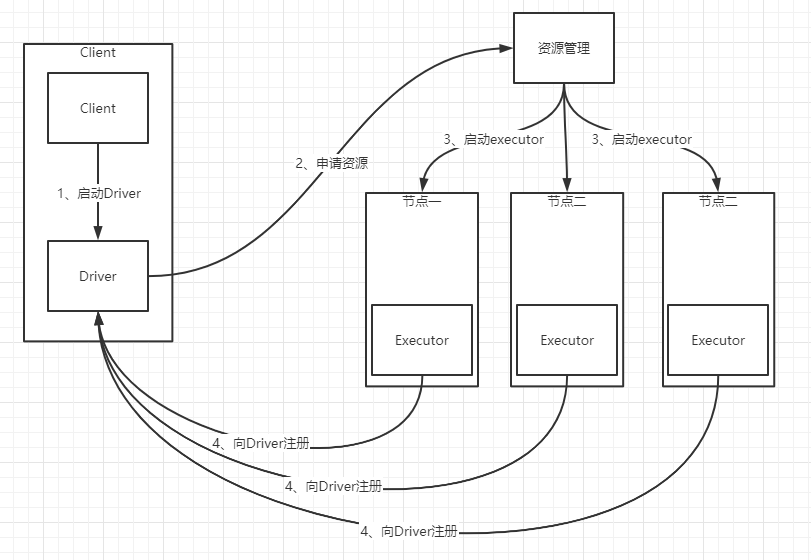
- 从上图可知,driver进程是启动在提交任务的client机器上
3、cluster提交流程
- 任务提交后,Master(资源管理器)会找到一个Worker(节点)启动Driver进程,Driver启动后向Master注册应用程序
- Master根据submit脚本的资源配置,启用相应的Worker
- 在Worker上启动所有的Executor,Executor反向到Driver注册
- Driver开始执行main函数,之后执行到Action算子时,开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行
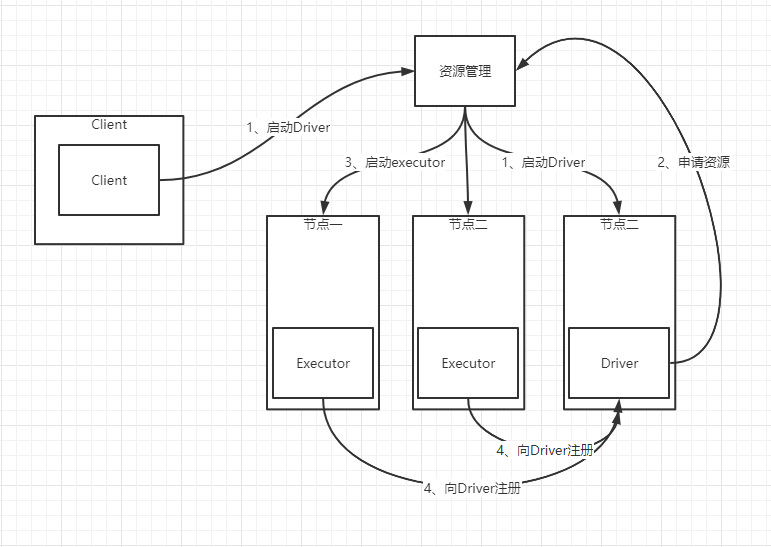
- 从上图可知,driver进程是启动在资源集群的节点上
4、总结
- deploy-mode的client与cluster模式的区别就在于:driver进程启动的位置,如果是在本地机器上则是client,在集群节点上则是cluster
- 上图中的资源管理、资源节点,可以对应到Spark自带的Master-Worker主从模式,也可以对应到yarn、mesos等资源管理器















 96
96











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









