1、repartition
1.1、官方解释
- 返回一个新的RDD具有 (numPartitions) 指定的分区数,可以通过该方法进行RDD并行度(分区数)的修改
- 如果要减少RDD分区数的话,建议使用使用coalesce方法,可以避免shuffle

从上可看出,repartition 底层其实是调用了coalesce 方法,且shuffle参数指定为 true
1.2、代码示例
val data: RDD[Int] = sc.parallelize(1 to 10, 5)
val data1: RDD[(Int, Int)] = data.mapPartitionsWithIndex(
(pi, pt) => {
pt.map(e => (pi, e))
}
)
data1.foreach(println)
println("================分割线================")
data1.repartition(3).mapPartitionsWithIndex(
(pi, pt) => {
pt.map(e => (pi, e))
}
).foreach(println)
1.3、job运行截图
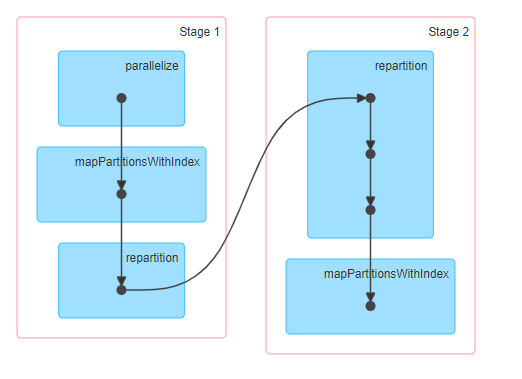
1.4、小结
- 无论是将增加或者减少分区数,使用repartition必然会造成shuffle
- repartition(num) 相当于 coalesce (num,true) ,既使用 coalesce 中shuffle参数为true,必然会产生shuffle无论分区是增加或者减少
2、coalesce
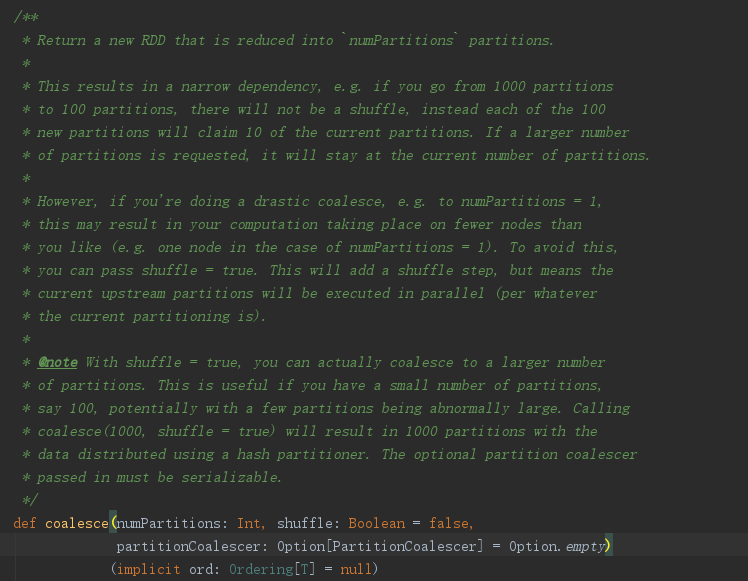
1.1、官方解释
- 返回一个新的RDD具有 (numPartitions) 指定的分区数
- shuffle 为 false,结果会是一个窄依赖,如果把1000个分区重分区到100个分区里面,则结果每个分区都包含前面的10个分区数据,如果重分区数大于当前分区数,则保持当前分区数(通俗理解:
- 当前分区数 < 重分区数,则当前分区数与重分区数一致,没效果;
- 当前分区数 > 重分区数,则把当前分区数分散到重分区中,通过IO方式,不走shuffle)
- shuffle 为 true,则效果与 repartition 一致
1.2、代码示例
val data: RDD[Int] = sc.parallelize(1 to 10, 5)
val data1: RDD[(Int, Int)] = data.mapPartitionsWithIndex(
(pi, pt) => {
pt.map(e => (pi, e))
}
)
val repartition: RDD[(Int, Int)] = data1.coalesce(3, false)
val res: RDD[(Int, (Int, Int))] = repartition.mapPartitionsWithIndex(
(pi, pt) => {
pt.map(e => (pi, e))
}
)
data1.foreach(println)
println("=============================")
res.foreach(println)
1.3、job运行截图
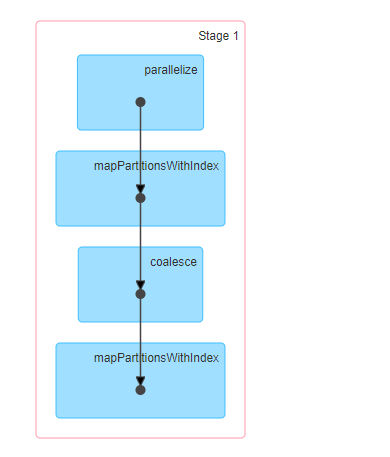
1.4、小结
- 在使用 coalesce 时,shuffle参数为false时,最常见的用途是减少分区数,如:经过filter后减少分区数
- 当shuffle参数为true时,效果与repartition一致
3、总结
- repartition 底层其实是调用了coalesce 方法,且shuffle参数指定为 true
- 减少分区数,推荐使用 coalesce 且不产生shuffle,代价很少



























 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









