






目标:获取BOSS直聘重点城市岗位信息情况
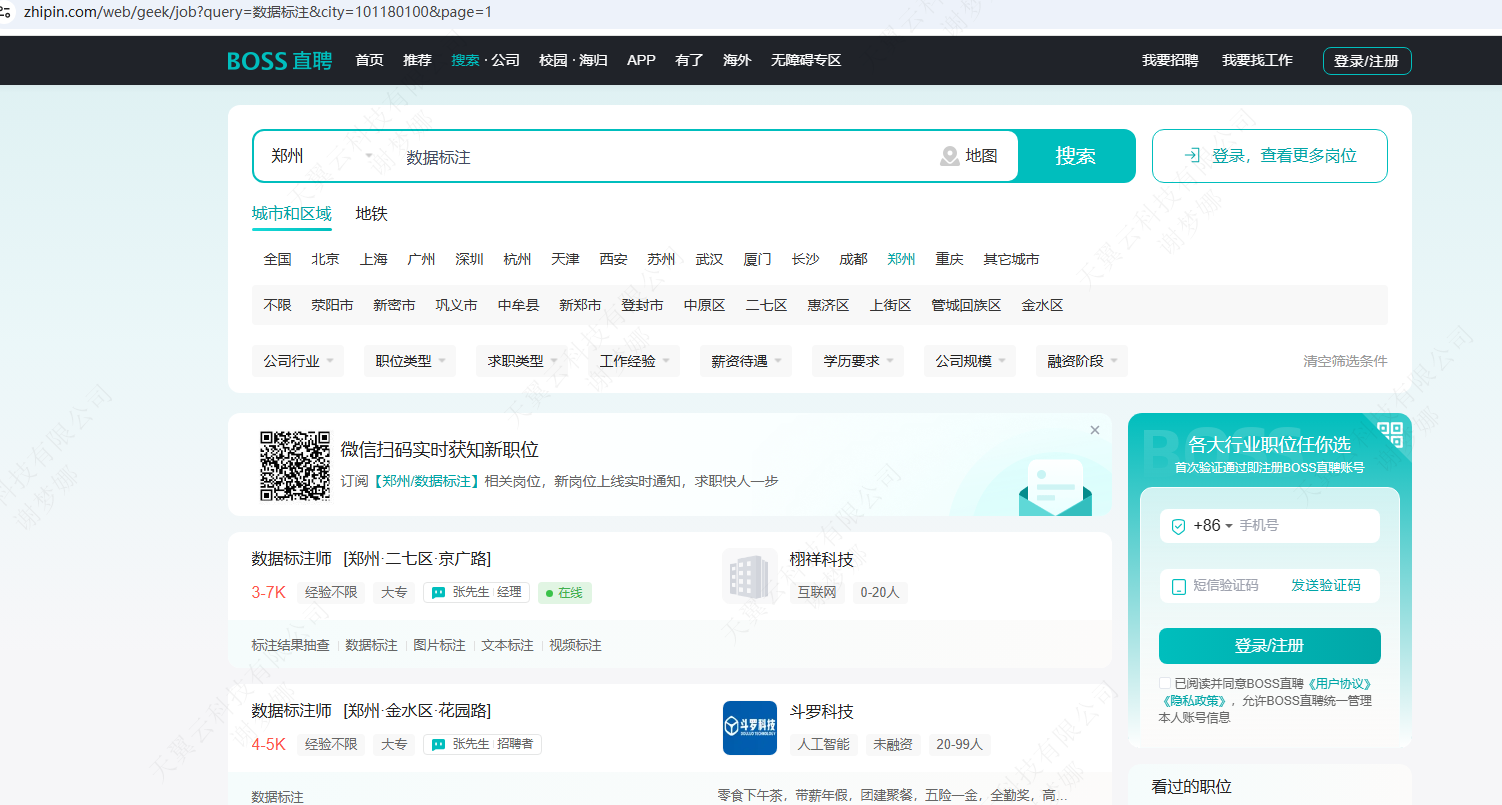
说明:
1、早期是用EDGE浏览器做自动化,发现后面被官网给针对性反爬了,同一页面EDGE浏览器和CHROME浏览器的页面不一致。所以又换成CHROME驱动执行了。
2、如果界面变动抓取的CSS代码也需要随时做调整。
代码:
# -*- coding:utf-8 -*-
import random
from threading import Thread
import pandas as pd
from selenium.webdriver.edge.service import Service
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import re
import sys
import io
import os
from selenium.webdriver.edge.options import Options
from webdriver_manager.microsoft import EdgeChromiumDriverManager
# 修改标准输出的默认编码为 UTF-8
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='gbk', errors='replace')
class Boss(object):
def getData(self):
# service = Service("./driver/msedgedriver.exe") # Edge驱动
# driver = webdriver.Edge(service=service)
service = Service("./driver/chromedriver.exe") # Chrome驱动
driver = webdriver.Chrome(service=service)
driver.get("https://www.zhipin.com/web/user/?ka=header-login")
input("请手动登录后按enter继续...")
query_content = "数据标注"
city_codes = {
# '全国': '100010000',
# '北京': '101010100',
# '上海': '101020100',
# '广州': '101280100',
# '深圳': '101280600',
# '杭州': '101210100',
# '天津': '101030100',
# '西安': '101110100',
# '苏州': '101190400',
# '武汉': '101200100',
# '厦门': '101230200',
# '长沙': '101250100',
# '成都': '101270100',
'郑州': '101180100',
'重庆': '101040100',
# '大同': '101100200',
# '沈阳': '101070100',
# '合肥': '101220100',
# '海口': '101310100',
# '保定': '101090200'
}
for city, city_code in city_codes.items():
print(f'城市: {city}, 代码: {city_code}')
for i in range(10): # 每个城市爬取10页数据
time.sleep(random.uniform(5, 10)) # 随机延迟,避免被封禁
driver.get(f"https://www.zhipin.com/web/geek/job?query={query_content}&city={city_code}&page={i+1}")
print(f"https://www.zhipin.com/web/geek/job?query={query_content}&city={city_code}&page={i+1}")
driver.implicitly_wait(10)
content = driver.find_elements(By.XPATH, '//div/ul/li[@class="job-card-wrapper"]')
for massage in content:
try:
gwm = massage.find_element(By.XPATH, './div/a/div/span[@class="job-name"]').text
gzdz = massage.find_element(By.XPATH, './div/a/div/span/span').text
xz = massage.find_element(By.XPATH, './div/a/div/span[@class="salary"]').text
gznx = massage.find_element(By.XPATH, './div/a/div/ul/li[1]').text
xlyq = massage.find_element(By.XPATH, './div/a/div/ul/li[2]').text
qymc = massage.find_element(By.XPATH, './div/div/div/h3/a').text
qylx = massage.find_element(By.XPATH, './div/div/div/ul/li[1]').text
qygm = massage.find_element(By.XPATH, './div/div/div/ul/li[contains(text(), "人")]').text
# 公司类型、融资情况、公司规模等
data = {
"岗位名": gwm,
"工作地址": gzdz,
"薪资": xz,
"工作年限": gznx,
"学历要求": xlyq,
"公司名称": qymc,
"公司类型":qylx,
"公司规模":qygm
}
print(data)
self.save(data) # 调用保存方法
except Exception as e:
print(e)
driver.quit()
def save(self, data):
filename = "boss职位.csv"
df = pd.DataFrame([data])
# print(df)
if pd.io.common.file_exists(filename):
existing_df = pd.read_csv(filename)
combined_df = pd.concat([existing_df, df], ignore_index=True)
unique_df = combined_df.drop_duplicates(subset=['岗位名'], keep='first')
unique_df.to_csv(filename, index=False, encoding='utf-8')
else:
print("文件保存")
df.to_csv(filename, index=False, encoding='utf-8')
if __name__ == '__main__':
bs = Boss()
threads = bs.getData()
EDGE驱动下载
官网地址
https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
操作步骤
打开Edge浏览器 → 输入 edge://settings/help 查看版本号(如 135.0.3179.73)
访问官网 → 选择对应版本 → 下载驱动
Chrome驱动下载:
官方地址
https://googlechromelabs.github.io/chrome-for-testing/
操作步骤
浏览器输入 chrome://version 查看版本(如 123.0.6312.59)
打开上述链接 → 找到与浏览器主版本号(如 123)匹配的驱动
选择对应操作系统(Windows/Mac/Linux)的 chromedriver-win64.zip 下载
效果图:
登录页面(建议微信扫码):
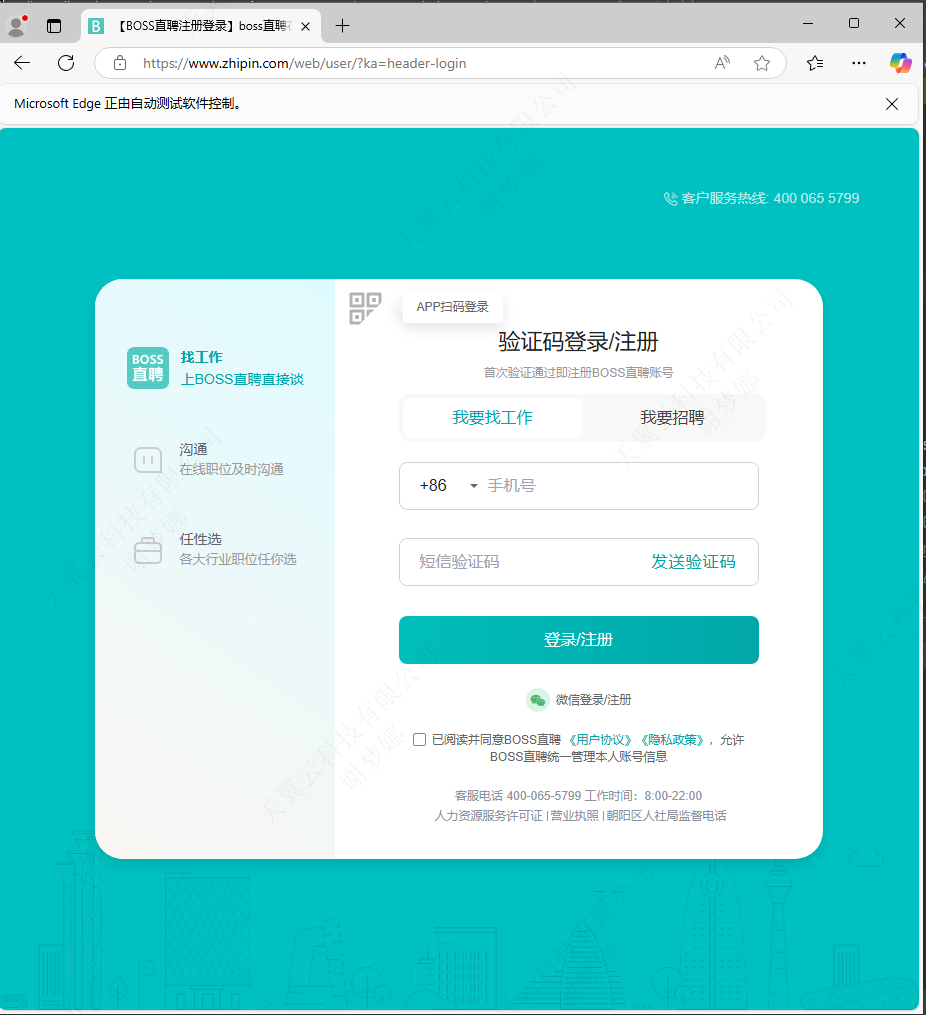
登录后回到控制台按enter继续
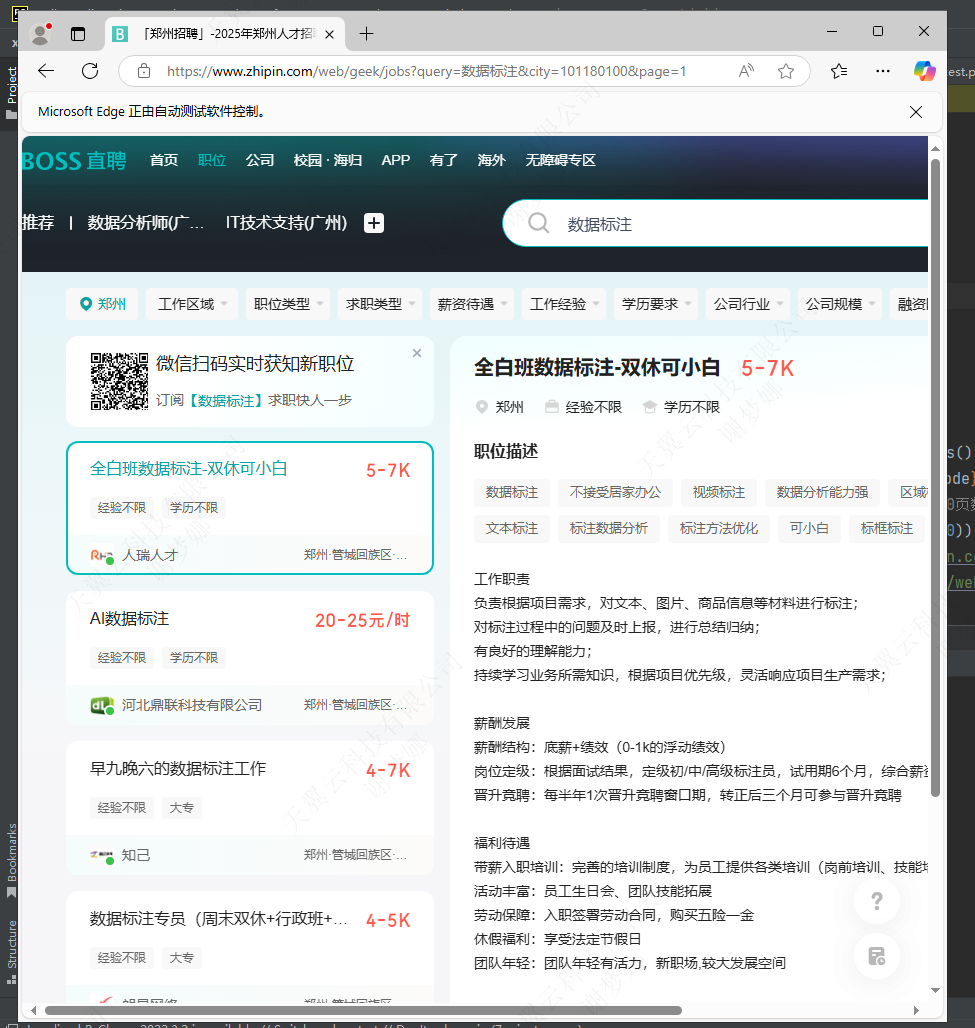
爬取后输出结果图:

参考文章: https://blog.csdn.net/qq_64120277/article/details/143568070

















 2109
2109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









