







-
1、逻辑斯特回归为什么要对特征进行离散化?
解析:
在工业界,很少直接将连续值作为逻辑回归模型的特征输入,而是将连续特征离散化为一系列0、1特征交给逻辑回归模型,这样做的优势有以下几点:
a. 离散特征的增加和减少都很容易,易于模型的快速迭代;
b. 稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展;
c. 离散化后的特征对异常数据有很强的鲁棒性:比如一个特征是年龄>30是1,否则0。如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰;
d. 逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合;
e. 离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力;
f. 特征离散化后,模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。当然处于区间相邻处的样本会刚好相反,所以怎么划分区间是门学问;
g. 特征离散化以后,起到了简化了逻辑回归模型的作用,降低了模型过拟合的风险。
李沐曾经说过:模型是使用离散特征还是连续特征,其实是一个“海量离散特征+简单模型” 同 “少量连续特征+复杂模型”的权衡。既可以离散化用线性模型,也可以用连续特征加深度学习。 -
2、LR和SVM的联系与区别?
解析:
联系:
1、LR和SVM都可以处理分类问题,且一般都用于处理线性二分类问题(在改进的情况下可以处理多分类问题)
2、两个方法都可以增加不同的正则化项,如l1、l2等等。所以在很多实验中,两种算法的结果是很接近的。
区别:
1、LR是参数模型,SVM是非参数模型。
2、从目标函数来看,区别在于逻辑回归采用的是logistic loss,SVM采用的是hinge loss,这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。
3、SVM的处理方法是只考虑support vectors,也就是和分类最相关的少数点,去学习分类器。而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重。
4、逻辑回归相对来说模型更简单,好理解,特别是大规模线性分类时比较方便。而SVM的理解和优化相对来说复杂一些,SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算。
5、logic 能做的 svm能做,但可能在准确率上有问题,svm能做的logic有的做不了。 -
3、LR与线性回归的区别与联系?
解析:
LR在线性回归的实数范围输出值上施加sigmoid函数将值收敛到0~1范围, 其目标函数从差平方和函数变为对数损失函数, 以提供最优化所需导数(sigmoid函数是softmax函数的二元特例, 其导数均为函数值的f*(1-f)形式)。
1)都是广义的线性回归
2)经典线性模型的优化目标函数是最小二乘,而逻辑回归则是负对数似然函数,
3)线性回归在整个实数域范围内进行预测,敏感度一致,而分类范围,需要在[0,1]。逻辑回归就是一种减小预测范围,将预测值限定为[0,1]间的一种回归模型,因而对于这类问题来说**,逻辑回归的鲁棒性比线性回归的要好**。
*4、请问(决策树、Random Forest、Booting、Adaboot)GBDT和XGBoost的区别是什么?
解析:
集成学习的集成对象是学习器. Bagging和Boosting属于集成学习的两类方法. Bagging方法有放回地采样同数量样本训练每个学习器, 然后再一起集成(简单投票); Boosting方法使用全部样本(可调权重)依次训练每个学习器, 迭代集成(平滑加权).
决策树属于最常用的学习器, 其学习过程是从根建立树, 也就是如何决策叶子节点分裂. ID3/C4.5决策树用信息熵计算最优分裂, CART决策树用基尼指数计算最优分裂, xgboost决策树使用二阶泰勒展开系数计算最优分裂.
下面所提到的学习器都是决策树:
Bagging方法:
学习器间不存在强依赖关系, 学习器可并行训练生成, 集成方式一般为投票;
Random Forest属于Bagging的代表, 放回抽样, 每个学习器随机选择部分特征去优化;
Boosting方法:
学习器之间存在强依赖关系、必须串行生成, 集成方式为加权和;
Adaboost属于Boosting, 采用指数损失函数替代原本分类任务的0/1损失函数;
GBDT属于Boosting的优秀代表, 对函数残差近似值进行梯度下降, 用CART回归树做学习器, 集成为回归模型;
xgboost属于Boosting的集大成者, 对函数残差近似值进行梯度下降, 迭代时利用了二阶梯度信息, 集成模型可分类也可回归. 由于它可在特征粒度上并行计算, 结构风险和工程实现都做了很多优化, 泛化, 性能和扩展性都比GBDT要好。
随机森林Random Forest是一个包含多个决策树的分类器。AdaBoost,则是英文"Adaptive Boosting"(自适应增强)的缩写。GBDT(Gradient Boosting Decision Tree),即梯度上升决策树算法,相当于融合决策树和梯度上升boosting算法。
xgboost类似于gbdt的优化版,不论是精度还是效率上都有了提升。与gbdt相比,具体的优点有:
1.损失函数是用泰勒展式二项逼近,而不是像gbdt里的就是一阶导数
2.对树的结构进行了正则化约束,防止模型过度复杂,降低了过拟合的可能性
3.节点分裂的方式不同,gbdt是用的gini系数,xgboost是经过优化推导后的
-
5、怎么理解决策树、xgboost能处理缺失值?而有的模型(svm)对缺失值比较敏感?
决策树模型怎么处理异常值?
随机森林(Random Forests)有两种解决缺失值的方法(Random forests - classification description):
1)(快速简单但效果差):把数值型变量(numerical variables)中的缺失值用其所对应的类别中(class)的中位数(median)替换。把描述型变量(categorical variables)缺失的部分用所对应类别中出现最多的数值替代(most frequent non-missing value)。以数值型变量为例:
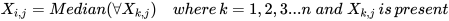
2)(耗时费力但效果好):虽然依然是使用中位数和出现次数最多的数来进行替换,方法2引入了权重。即对需要替换的数据先和其他数据做相似度测量(proximity measurement)也就是下面公式中的Weight( ),在补全缺失点是相似的点的数据会有更高的权重W。以数值型变量为例:
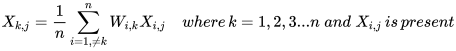
Breiman说明了第二种方法的效果更好,但需要的时间更长。这也是为什么工具包中一般不提供数据补全的功能,因为会影响到工具包的效率。xgboost怎么处理缺失值?
xgboost处理缺失值的方法和其他树模型不同。xgboost把缺失值当做稀疏矩阵来对待,本身的在节点分裂时不考虑的缺失值的数值。缺失值数据会被分到左子树和右子树分别计算损失,选择较优的那一个。如果训练中没有数据缺失,预测时出现了数据缺失,那么默认被分类到右子树。

这样的处理方法固然巧妙,但也有风险:即我们假设了训练数据和预测数据的分布相同,比如缺失值的分布也相同,不过直觉上应该影响不是很大:)什么样的模型对缺失值更敏感?
树模型对于缺失值的敏感度较低,大部分时候可以在数据有缺失时使用。
涉及到距离度量(distance measurement)时,如计算两个点之间的距离,缺失数据就变得比较重要。因为涉及到“距离”这个概念,那么缺失值处理不当就会导致效果很差,如K近邻算法(KNN)和支持向量机(SVM)。
线性模型的代价函数(loss function)往往涉及到距离(distance)的计算,计算预测值和真实值之间的差别,这容易导致对缺失值敏感。
神经网络的鲁棒性强,对于缺失数据不是非常敏感,但一般没有那么多数据可供使用。
贝叶斯模型对于缺失数据也比较稳定,数据量很小的时候首推贝叶斯模型。
总结来看,对于有缺失值的数据在经过缺失值处理后:
1)数据量很小,用朴素贝叶斯
2)数据量适中或者较大,用树模型,优先 xgboost
3)数据量较大,也可以用神经网络
4)避免使用距离度量相关的模型,如KNN和SVM -
6、如何进行特征选择?
解析:
特征选择是一个重要的数据预处理过程,主要有两个原因:一是减少特征数量、降维,使模型泛化能力更强,减少过拟合;二是增强对特征和特征值之间的理解
常见的特征选择方式:
- 去除方差较小的特征
- 正则化。1正则化能够生成稀疏的模型。L2正则化的表现更加稳定,由于有用的特征往往对应系数非零。
- 随机森林,对于分类问题,通常采用基尼不纯度或者信息增益,对于回归问题,通常采用的是方差或者最小二乘拟合。一般不需要feature engineering、调参等繁琐的步骤。它的两个主要问题,1是重要的特征有可能得分很低(关联特征问题),2是这种方法对特征变量类别多的特征越有利(偏向问题)。
- 稳定性选择。是一种基于二次抽样和选择算法相结合较新的方法,选择算法可以是回归、SVM或其他类似的方法。它的主要思想是在不同的数据子集和特征子集上运行特征选择算法,不断的重复,最终汇总特征选择结果,比如可以统计某个特征被认为是重要特征的频率(被选为重要特征的次数除以它所在的子集被测试的次数)。理想情况下,重要特征的得分会接近100%。稍微弱一点的特征得分会是非0的数,而最无用的特征得分将会接近于0。
- 7、数据预处理?
解析:
- 缺失值,填充缺失值fillna:
i. 离散:None,
ii. 连续:均值。
iii. 缺失值太多,则直接去除该列 - 连续值:离散化。有的模型(如决策树)需要离散值
- 对定量特征二值化。核心在于设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0。如图像操作
- 皮尔逊相关系数,去除高度相关的列
-
8、数据不平衡问题?
解析:
采样,对小样本加噪声采样,对大样本进行下采样
数据生成,利用已知样本生成新的样本
进行特殊的加权,如在Adaboost中或者SVM中
采用对不平衡数据集不敏感的算法
改变评价标准:用AUC/ROC来进行评价
采用Bagging/Boosting/ensemble等方法
在设计模型的时候考虑数据的先验分布 -
9、常见的分类算法有哪些?他们各自的优缺点是什么?
解析:
贝叶斯分类法
优点:
1)所需估计的参数少,对于缺失数据不敏感。
2)有着坚实的数学基础,以及稳定的分类效率。
缺点:
1)假设属性之间相互独立,这往往并不成立。(喜欢吃番茄、鸡蛋,却不喜欢吃番茄炒蛋)。
2)需要知道先验概率。
3)分类决策存在错误率。决策树
优点:
1)不需要任何领域知识或参数假设。
2)适合高维数据。
3)简单易于理解。
4)短时间内处理大量数据,得到可行且效果较好的结果。
5)能够同时处理数据型和常规性属性。
缺点:
1)对于各类别样本数量不一致数据,信息增益偏向于那些具有更多数值的特征。
2)易于过拟合。
3)忽略属性之间的相关性。
4)不支持在线学习。支持向量机
优点:
1)可以解决小样本下机器学习的问题。
2)提高泛化性能。
3)可以解决高维、非线性问题。超高维文本分类仍受欢迎。
4)避免神经网络结构选择和局部极小的问题。
缺点:
1)对缺失数据敏感。
2)内存消耗大,难以解释。
3)运行和调差略烦人。K近邻
优点:
1)思想简单,理论成熟,既可以用来做分类也可以用来做回归;
2)可用于非线性分类;
3)训练时间复杂度为O(n);
4)准确度高,对数据没有假设,对outlier不敏感;
缺点:
1)计算量太大
2)对于样本分类不均衡的问题,会产生误判。
3)需要大量的内存。
4)输出的可解释性不强。Logistic回归
优点:
1)速度快。
2)简单易于理解,直接看到各个特征的权重。
3)能容易地更新模型吸收新的数据。
4)如果想要一个概率框架,动态调整分类阀值。
缺点:
特征处理复杂。需要归一化和较多的特征工程。神经网络
优点:
1)分类准确率高。
2)并行处理能力强。
3)分布式存储和学习能力强。
4)鲁棒性较强,不易受噪声影响。
缺点:
1)需要大量参数(网络拓扑、阀值、阈值)。
2)结果难以解释。
3)训练时间过长。Adaboost
优点:
1)adaboost是一种有很高精度的分类器。
2)可以使用各种方法构建子分类器,Adaboost算法提供的是框架。
3)当使用简单分类器时,计算出的结果是可以理解的。而且弱分类器构造极其简单。
4)简单,不用做特征筛选。
5)不用担心overfitting。
缺点:
对outlier比较敏感 -
10、说说常见的优化算法及其优缺点?
解析:
1)随机梯度下降
优点:可以一定程度上解决局部最优解的问题
缺点:收敛速度较慢
2)批量梯度下降
优点:容易陷入局部最优解
缺点:收敛速度较快
3)mini_batch梯度下降
综合随机梯度下降和批量梯度下降的优缺点,提取的一个中和的方法。
4)牛顿法
牛顿法在迭代的时候,需要计算Hessian矩阵,当维度较高的时候,计算 Hessian矩阵比较困难。
5)拟牛顿法
拟牛顿法是为了改进牛顿法在迭代过程中,计算Hessian矩阵而提取的算法,它采用的方式是通过逼近Hessian的方式来进行求解。
具体而言
从每个batch的数据来区分
梯度下降:每次使用全部数据集进行训练
优点:得到的是最优解
缺点:运行速度慢,内存可能不够
随机梯度下降:每次使用一个数据进行训练
优点:训练速度快,无内存问题
缺点:容易震荡,可能达不到最优解
Mini-batch梯度下降
优点:训练速度快,无内存问题,震荡较少
缺点:可能达不到最优解
从优化方法上来分:
随机梯度下降(SGD)
缺点
选择合适的learning rate比较难
对于所有的参数使用同样的learning rate
容易收敛到局部最优
可能困在saddle point
SGD+Momentum
优点:
积累动量,加速训练
局部极值附近震荡时,由于动量,跳出陷阱
梯度方向发生变化时,动量缓解动荡。
Nesterov Mementum
与Mementum类似,优点:
避免前进太快
提高灵敏度
AdaGrad
优点:
控制学习率,每一个分量有各自不同的学习率
适合稀疏数据
缺点
依赖一个全局学习率
学习率设置太大,其影响过于敏感
后期,调整学习率的分母积累的太大,导致学习率很低,提前结束训练。
RMSProp
优点:
解决了后期提前结束的问题。
缺点:
依然依赖全局学习率
Adam
Adagrad和RMSProp的合体
优点:
结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点
为不同的参数计算不同的自适应学习率
也适用于大多非凸优化 - 适用于大数据集和高维空间
牛顿法
牛顿法在迭代的时候,需要计算Hessian矩阵,当维度较高的时候,计算 Hessian矩阵比较困难
拟牛顿法
拟牛顿法是为了改进牛顿法在迭代过程中,计算Hessian矩阵而提取的算法,它采用的方式是通过逼近Hessian的方式来进行求解。
-
11、RF与GBDT之间的区别与联系?
解析:
1)相同点:都是由多棵树组成,最终的结果都是由多棵树一起决定。
2)不同点:
a 组成随机森林的树可以分类树也可以是回归树,而GBDT只由回归树组成
b 组成随机森林的树可以并行生成,而GBDT是串行生成
c 随机森林的结果是多数表决表决的,而GBDT则是多棵树累加之和
d 随机森林对异常值不敏感,而GBDT对异常值比较敏感
e 随机森林是减少模型的方差,而GBDT是减少模型的偏差
f 随机森林不需要进行特征归一化。而GBDT则需要进行特征归一化 -
12、逻辑回归相关问题?
解析:
(1)公式推导一定要会
(2)逻辑回归的基本概念
这个最好从广义线性模型的角度分析,逻辑回归是假设y服从Bernoulli分布。
(3)L1-norm和L2-norm
其实稀疏的根本还是在于L0-norm也就是直接统计参数不为0的个数作为规则项,但实际上却不好执行于是引入了L1-norm;而L1norm本质上是假设参数先验是服从Laplace分布的,而L2-norm是假设参数先验为Gaussian分布,我们在网上看到的通常用图像来解答这个问题的原理就在这。
但是L1-norm的求解比较困难,可以用坐标轴下降法或是最小角回归法求解。
(4)LR和SVM对比
首先,LR和SVM最大的区别在于损失函数的选择,LR的损失函数为Log损失(或者说是逻辑损失都可以)、而SVM的损失函数为hinge loss。
其次,两者都是线性模型。
最后,SVM只考虑支持向量(也就是和分类相关的少数点)
(5)LR和随机森林区别
随机森林等树算法都是非线性的,而LR是线性的。LR更侧重全局优化,而树模型主要是局部的优化。
(6)常用的优化方法
逻辑回归本身是可以用公式求解的,但是因为需要求逆的复杂度太高,所以才引入了梯度下降算法。
一阶方法:梯度下降、随机梯度下降、mini 随机梯度下降降法。随机梯度下降不但速度上比原始梯度下降要快,局部最优化问题时可以一定程度上抑制局部最优解的发生。
二阶方法:牛顿法、拟牛顿法:
这里详细说一下牛顿法的基本原理和牛顿法的应用方式。牛顿法其实就是通过切线与x轴的交点不断更新切线的位置,直到达到曲线与x轴的交点得到方程解。在实际应用中我们因为常常要求解凸优化问题,也就是要求解函数一阶导数为0的位置,而牛顿法恰好可以给这种问题提供解决方法。实际应用中牛顿法首先选择一个点作为起始点,并进行一次二阶泰勒展开得到导数为0的点进行一个更新,直到达到要求,这时牛顿法也就成了二阶求解问题,比一阶方法更快。我们常常看到的x通常为一个多维向量,这也就引出了Hessian矩阵的概念(就是x的二阶导数矩阵)。
缺点:牛顿法是定长迭代,没有步长因子,所以不能保证函数值稳定的下降,严重时甚至会失败。还有就是牛顿法要求函数一定是二阶可导的。而且计算Hessian矩阵的逆复杂度很大。
拟牛顿法: 不用二阶偏导而是构造出Hessian矩阵的近似正定对称矩阵的方法称为拟牛顿法。拟牛顿法的思路就是用一个特别的表达形式来模拟Hessian矩阵或者是他的逆使得表达式满足拟牛顿条件。主要有DFP法(逼近Hession的逆)、BFGS(直接逼近Hession矩阵)、 L-BFGS(可以减少BFGS所需的存储空间)。
-
13、SVM、LR、决策树的对比?
解析:
模型复杂度:SVM支持核函数,可处理线性非线性问题;LR模型简单,训练速度快,适合处理线性问题;决策树容易过拟合,需要进行剪枝
损失函数:SVM hinge loss; LR L2正则化; adaboost 指数损失
数据敏感度:SVM添加容忍度对outlier不敏感,只关心支持向量,且需要先做归一化; LR对远点敏感
数据量:数据量大就用LR,数据量小且特征少就用SVM非线性核 -
14、当神经网络的调参效果不好时,从哪些角度思考?(不要首先归结于overfiting)
解析:
1)是否找到合适的损失函数?(不同问题适合不同的损失函数)(理解不同损失函数的适用场景)
2)batch size是否合适?batch size太大 -> loss很快平稳,batch size太小 -> loss会震荡(理解mini-batch)
3)是否选择了合适的激活函数?(各个激活函数的来源和差异)
4)学习率,学习率小收敛慢,学习率大loss震荡(怎么选取合适的学习率)
5)是否选择了合适的优化算法?(比如adam)(理解不同优化算法的适用场景)
6)是否过拟合?(深度学习拟合能力强,容易过拟合)(理解过拟合的各个解决方案)
a. Early Stopping
b. Regularization(正则化)
c. Weight Decay(收缩权重)
d. Dropout(随机失活)
e. 调整网络结构 -
15、你有哪些深度学习(rnn、cnn)调参的经验?
解析一
cnn的调参主要是在优化函数、embedding的维度还要残差网络的层数几个方面。
优化函数方面有两个选择:sgd、adam,相对来说adam要简单很多,不需要设置参数,效果也还不错。
embedding随着维度的增大会出现一个最大值点,也就是开始时是随维度的增加效果逐渐变好,到达一个点后,而后随维度的增加,效果会变差。
残差网络的层数与embedding的维度有关系,随层数的增加,效果变化也是一个凸函数。
另外还有激活函数,dropout层和batchnormalize层的使用。激活函数推荐使用relu,dropout层数不易设置过大,过大会导致不收敛,调节步长可以是0.05,一般调整到0.4或者0.5就可找到最佳值。
解析二
一、参数初始化
下面几种方式,随便选一个,结果基本都差不多。但是一定要做。否则可能会减慢收敛速度,影响收敛结果,甚至造成Nan等一系列问题。
下面的n_in为网络的输入大小,n_out为网络的输出大小,n为n_in或(n_in+n_out)*0.5
Xavier初始法论文:http://jmlr.org/proceedings/papers/v9/glorot10a/glorot10a.pdf
He初始化论文:https://arxiv.org/abs/1502.01852
A)uniform均匀分布初始化:w = np.random.uniform(low=-scale, high=scale, size=[n_in,n_out])
①Xavier初始法,适用于普通激活函数(tanh,sigmoid):scale = np.sqrt(3/n)
②He初始化,适用于ReLU:scale = np.sqrt(6/n)
B)normal高斯分布初始化:w = np.random.randn(n_in,n_out) * stdev # stdev为高斯分布的标准差,均值设为0
①Xavier初始法,适用于普通激活函数 (tanh,sigmoid):stdev = np.sqrt(n)
②He初始化,适用于ReLU:stdev = np.sqrt(2/n)
C)svd初始化:对RNN有比较好的效果。参考论文:https://arxiv.org/abs/1312.6120
二、数据预处理方式
zero-center ,这个挺常用的.X -= np.mean(X, axis = 0) # zero-centerX /= np.std(X, axis = 0) # normalize
PCA whitening,这个用的比较少.
三、训练技巧
要做梯度归一化,即算出来的梯度除以minibatch size
clip c(梯度裁剪): 限制最大梯度,其实是value = sqrt(w12+w22….),如果value超过了阈值,就算一个衰减系系数,让value的值等于阈值: 5,10,15
dropout对小数据防止过拟合有很好的效果,值一般设为0.5,小数据上dropout+sgd在我的大部分实验中,效果提升都非常明显.因此可能的话,建议一定要尝试一下。 dropout的位置比较有讲究, 对于RNN,建议放到输入->RNN与RNN->输出的位置.关于RNN如何用dropout,可以参考这篇论文:http://arxiv.org/abs/1409.2329
adam,adadelta等,在小数据上,我这里实验的效果不如sgd, sgd收敛速度会慢一些,但是最终收敛后的结果,一般都比较好。如果使用sgd的话,可以选择从1.0或者0.1的学习率开始,隔一段时间,在验证集上检查一下,如果cost没有下降,就对学习率减半. 我看过很多论文都这么搞,我自己实验的结果也很好. 当然,也可以先用ada系列先跑,最后快收敛的时候,更换成sgd继续训练.同样也会有提升.据说adadelta一般在分类问题上效果比较好,adam在生成问题上效果比较好。
除了gate之类的地方,需要把输出限制成0-1之外,尽量不要用sigmoid,可以用tanh或者relu之类的激活函数.1. sigmoid函数在-4到4的区间里,才有较大的梯度。之外的区间,梯度接近0,很容易造成梯度消失问题。2. 输入0均值,sigmoid函数的输出不是0均值的。
rnn的dim和embdding size,一般从128上下开始调整. batch size,一般从128左右开始调整.batch size合适最重要,并不是越大越好.
word2vec初始化,在小数据上,不仅可以有效提高收敛速度,也可以可以提高结果.
四、尽量对数据做shuffle
LSTM 的forget gate的bias,用1.0或者更大的值做初始化,可以取得更好的结果,来自这篇论文:http://jmlr.org/proceedings/papers/v37/jozefowicz15.pdf, 我这里实验设成1.0,可以提高收敛速度.实际使用中,不同的任务,可能需要尝试不同的值.
Batch Normalization据说可以提升效果,不过我没有尝试过,建议作为最后提升模型的手段,参考论文:Accelerating Deep Network Training by Reducing Internal Covariate Shift
如果你的模型包含全连接层(MLP),并且输入和输出大小一样,可以考虑将MLP替换成Highway Network,我尝试对结果有一点提升,建议作为最后提升模型的手段,原理很简单,就是给输出加了一个gate来控制信息的流动,详细介绍请参考论文: http://arxiv.org/abs/1505.00387
来自@张馨宇的技巧:一轮加正则,一轮不加正则,反复进行。
五、Ensemble
Ensemble是论文刷结果的终极核武器,深度学习中一般有以下几种方式
同样的参数,不同的初始化方式
不同的参数,通过cross-validation,选取最好的几组
同样的参数,模型训练的不同阶段,即不同迭代次数的模型。
不同的模型,进行线性融合. 例如RNN和传统模型.
更多深度学习技巧,请参见专栏:炼丹实验室 - 知乎专栏(链接:https://zhuanlan.zhihu.com/easyml)
本解析一来源@萧瑟,链接:https://www.zhihu.com/question/41631631/answer/94816420
解析三
@罗浩.ZJU:其实我发现现在深度学习越来越成熟,调参工作比以前少了很多,绝大多数情况自己设计的参数都不如教程和框架的默认参数好,不过有一些技巧我一直都在用的
(1)relu+bn。这套好基友组合是万精油,可以满足95%的情况,除非有些特殊情况会用identity,比如回归问题,比如resnet的shortcut支路,sigmoid什么的都快从我世界里消失了
(2)dropout 。分类问题用dropout ,只需要最后一层softmax 前用基本就可以了,能够防止过拟合,可能对accuracy提高不大,但是dropout 前面的那层如果是之后要使用的feature的话,性能会大大提升
(3)数据的shuffle 和augmentation 。这个没啥好说的,aug也不是瞎加,比如行人识别一般就不会加上下翻转的,因为不会碰到头朝下的异型种
(4)降学习率。随着网络训练的进行,学习率要逐渐降下来,如果你有tensorboard,你有可能发现,在学习率下降的一瞬间,网络会有个巨大的性能提升,同样的fine-tuning也要根据模型的性能设置合适的学习率,比如一个训练的已经非常好的模型你上来就1e-3的学习率,那之前就白训练了,就是说网络性能越好,学习率要越小
(5)tensorboard。以前不怎么用,用了之后发现太有帮助,帮助你监视网络的状态,来调整网络参数
(6)随时存档模型,要有validation 。这就跟打游戏一样存档,把每个epoch和其对应的validation 结果存下来,可以分析出开始overfitting的时间点,方便下次加载fine-tuning
(7)网络层数,参数量什么的都不是大问题,在性能不丢的情况下,减到最小
(8)batchsize通常影响没那么大,塞满卡就行,除了特殊的算法需要batch大一点
(9)输入减不减mean归一化在有了bn之后已经不那么重要了
上面那些都是大家所知道的常识,也是外行人觉得深度学习一直在做的就是这些很low的东西,其实网络设计上博大精深,这也远超过我的水平范畴,只说一些很简单的
(10)卷积核的分解。从最初的5×5分解为两个3×3,到后来的3×3分解为1×3和3×1,再到resnet的1×1,3×3,1×1,再xception的3×3 channel-wise conv+1×1,网络的计算量越来越小,层数越来越多,性能越来越好,这些都是设计网络时可以借鉴的
(11)不同尺寸的feature maps的concat,只用一层的feature map一把梭可能不如concat好,pspnet就是这种思想,这个思想很常用
(12)resnet的shortcut确实会很有用,重点在于shortcut支路一定要是identity,主路是什么conv都无所谓,这是我亲耳听resnet作者所述
(13)针对于metric learning,对feature加个classification 的约束通常可以提高性能加快收敛
-
16、CNN最成功的应用是在CV,那为什么NLP和Speech的很多问题也可以用CNN解出来?为什么AlphaGo里也用了CNN?这几个不相关的问题的相似性在哪里?CNN通过什么手段抓住了这个共性?
解析:
以上几个不相关问题的相关性在于,都存在局部与整体的关系,由低层次的特征经过组合,组成高层次的特征,并且得到不同特征之间的空间相关性。如下图:低层次的直线/曲线等特征,组合成为不同的形状,最后得到汽车的表示。
CNN抓住此共性的手段主要有四个:局部连接/权值共享/池化操作/多层次结构。
局部连接使网络可以提取数据的局部特征;权值共享大大降低了网络的训练难度,一个Filter只提取一个特征,在整个图片(或者语音/文本) 中进行卷积;池化操作与多层次结构一起,实现了数据的降维,将低层次的局部特征组合成为较高层次的特征,从而对整个图片进行表示。
《 CNN笔记:通俗理解卷积神经网络》。(链接:http://blog.csdn.net/v_july_v/article/details/51812459) -
17、如何解决梯度消失和梯度膨胀?
解析:
(1)梯度消失:
根据链式法则,如果每一层神经元对上一层的输出的偏导乘上权重结果都小于1的话,那么即使这个结果是0.99,在经过足够多层传播之后,误差对输入层的偏导会趋于0
可以采用ReLU激活函数有效的解决梯度消失的情况,也可以用Batch Normalization解决这个问题。关于深度学习中 Batch Normalization为什么效果好?参见:https://www.zhihu.com/question/38102762
(2)梯度膨胀
根据链式法则,如果每一层神经元对上一层的输出的偏导乘上权重结果都大于1的话,在经过足够多层传播之后,误差对输入层的偏导会趋于无穷大
可以通过激活函数来解决,或用Batch Normalization解决这个问题。















 9305
9305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









