







白盒蒸馏
1. 什么是白盒蒸馏
白盒蒸馏是指在蒸馏过程中使用到教师模型的参数或 logits 的 蒸馏技术.
接下来我们会介绍经典的白盒蒸馏方法和代码实现。
2. MiniLLM
大模型能力的强大也伴随着参数量的膨胀,为了以合理的成本部署大模型,如何将大模型的知识蒸馏到小模型是一个问题。从前,面对有限的状态空间(比如有限的分类类别),教师模型和学生模型的参数量都足以学习每一种类别的模式;而在大模型自回归生成的场景下,学生模型参数变少后,天然地失去了和大模型同等的表达能力,从而传统的蒸馏可能效果不佳。
MiniLLM是一种针对生成式语言模型的全新的KD方法,它是一种白盒蒸馏方法,这种方法使用逆向KL散度,理论上使得学生模型模仿教师模型概率较大的生成结果,忽略教师模型概率不大的生成结果。这样做一定程度放弃了模型生成的多样性,从而实现高性价比的LLM部署落地。
2.1 前向KL散度
前向KL散度是传统蒸馏时使用的损失函数,这里我们再复习一下它的概念:
假设老师分布为 p p p, 学生分布为 q θ q_\theta qθ, θ \theta θ 是学生模型的参数。
前向KL散度可以看成是两个分布相似程度的定义(注意KL散度具有不对称性,不是距离):
K L ( p ∣ ∣ q θ ) = ∑ i p ( i ) l o g p ( i ) q θ ( i ) KL(p||q_\theta) = \sum_i p(i)log\frac{p(i)}{q_\theta(i)} KL(p∣∣qθ)=∑ip(i)logqθ(i)p(i)。
从定义可以看出,在 p p p分布为 0 0 0的地方, q q q分布无论为多少,都不影响这一项为 0 0 0,所以当我们最小化前向KL散度时, q q q会在老师概率分布小的地方分配大的概率。对应到大模型生成上,就是在老师模型输出可能性很小的地方,学生模型却放大了这种可能性,显然这是不符合模型生成预期的。
2.2 逆向KL散度
reversed KL:
K L ( q θ ∣ ∣ p ) = ∑ i q θ ( i ) l o g q θ ( i ) p ( i ) = − ∑ i q θ ( i ) l o g p ( i ) q θ ( i ) KL(q_\theta ||p) = \sum_i q_\theta(i)log\frac{q_\theta(i)}{p(i)} = -\sum_i q_\theta(i)log\frac{p(i)}{q_\theta(i)} KL(qθ∣∣p)=i∑qθ(i)logp(i)qθ(i)=−i∑qθ(i)logqθ(i)p(i)
蒸馏时,使用逆向KL散度代替前向KL散度。最小化逆向KL散度时,老师分布大的地方,学生分布也同步变大,而老师分布小的地方,学生分布会更小。下面这张经典的图片可以看出前向和后向KL的差异。
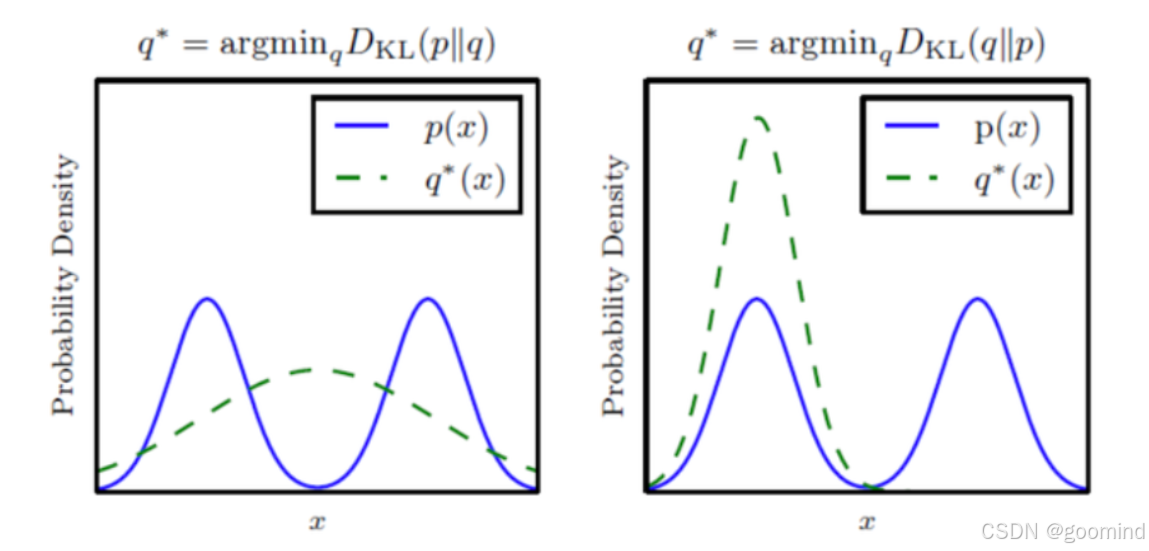
这样直观上看,使用逆向KL散度更加符合生成模型的场景。
2.3 基于策略梯度的优化
MiniLLM的论文中提出了另一个新颖的视角——逆向KL其实可以等价于强化学习,并进行了公式推导。策略梯度是一种强化学习算法:将期望的回报写成一个可导的函数,然后求使得这个函数的最大的策略(比如使用梯度上升)。
由于这部分涉及较多数学公式推导和强化学习,有兴趣的同学可以查看论文自行学习。
3. BabyLlama(实践)
将小模型蒸馏直接应用到了大模型上。它的损失函数是以下两种损失的加权和:
- 和硬损失的交叉熵
- 和软损失的KL散度
损失函数:
def compute_loss(self, model, inputs, return_outputs=False):
# 硬损失,即和ground truth的交叉熵
outputs_student = model(**inputs)
student_loss = outputs_student.loss
# compute teacher output
with torch.no_grad():
all_teacher_logits = []
for teacher in self.teachers:
outputs_teacher = teacher(**inputs)
all_teacher_logits.append(outputs_teacher.logits)
avg_teacher_logits = torch.stack(all_teacher_logits).mean(dim=0)
# assert size
assert outputs_student.logits.size() == avg_teacher_logits.size()
# 软损失,和教师模型输出分布的KL散度
loss_function = nn.KLDivLoss(reduction="batchmean")
loss_logits = (
loss_function(
F.log_softmax(outputs_student.logits / self.args.temperature, dim=-1),
F.softmax(avg_teacher_logits / self.args.temperature, dim=-1),
)
* (self.args.temperature ** 2)
)
# Return weighted student loss
loss = self.args.alpha * student_loss + (1.0 - self.args.alpha) * loss_logits
return (loss, outputs_student) if return_outputs else loss


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









