







大语言模型的性能与成本一直是业界关注的焦点,曾经业内的共识是训练大模型需要非常多的显卡,但DeepSeek-R1的出现打破了这一格局,DeepSeek在只用了OpenAI几十分之一的成本的情况下,训练出了能对标当时最先进的GPT-o1模型的DeepSeek-R1模型,DeepSeek不但训练成本显著低于OpenAI的模型。且每 100 万 tokens 的输入,R1 比 GPT-o1 模型便宜 90%,输出价格更是降低了 27 倍左右。DeepSeek-R1的发布大大降低了人们对大模型成本的预期,也因此让英伟达股价大跌,下面就来拆解一下DeepSeek成本大幅降低的原因。
推理层面
在大模型领域,“推理”这个中文单词有2个含义,一个是“inference”,指对输入的数据进行处理并生成输出结果的过程;另一个是“reasoning”,指大模型在运行过程中进行思考,并运用各种和逻辑方法来得出结论。
而这章介绍推理的是“inference”,即如何处理输入数据并生成输出结果。大模型的推理引擎有很多,并且都各有特色,这里我列举一些常见的LLM推理引擎:
- Transformers(Hugging Face推出的库,适合实验和学习)
- vLLM(一个高效的推理加速框架)
- SGLang(适合在各种场景下定制推理方式,需要一定技术基础)
- Llama.cpp(纯C/C++实现,不需要安装额外依赖环境,同时支持多种除CUDA以外的GPU调用方式,需要一定技术基础)
- Ollama(对Llama.cpp的封装,使用起来非常简单,对小白友好)
- MLX(专门为苹果芯片优化的机器学习框架)
- Xinference(对
vLLM、SGLang、Llama.cpp、Transformers、MLX的封装,特点是部署快捷、使用简单) - LMDeploy(一个吞吐量比vLLM高的推理加速框架)
下面介绍些常用的推理加速手段
KV Cache
大模型的生成过程是自回归式的,即每次都会输出一个新的token并拼接入序列,反复迭代直到结束。而在这推理过程中有一个步骤是计算自注意力,会对每个输入token计算其对应的Q(Query)、K(Key)和V(Value),并用公式
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
计算注意力分数。而每次自注意力的计算都有大量的重复内容,因此可以将计算结果保存下来留着下次使用,而这就是KV Cache。
多头潜在注意力(MLA)如何压缩KVCache的显存占用
介绍各种推理引擎常用的加速推理方法
Persistent Batch(也叫continuous batching)
说简单点就是用一个模型同时推理多个序列,增加模型吞吐量
KV Cache复用
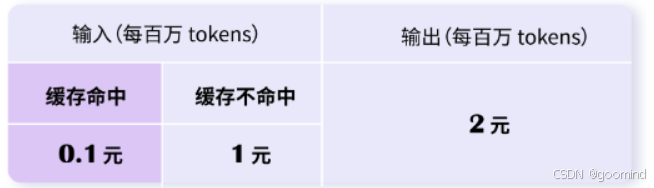
DeepSeek也使用了这种方法,最直观的感受是命中缓存的部分价格是 百万tokens/0.1元,便宜了一个数量级。
KV Cache复用的方法可以参考SGLang的RadixAttention,最核心的思想就是具有相同前缀的输入可以共享KV Cache
SGLang论文:https://arxiv.org/abs/2312.07104
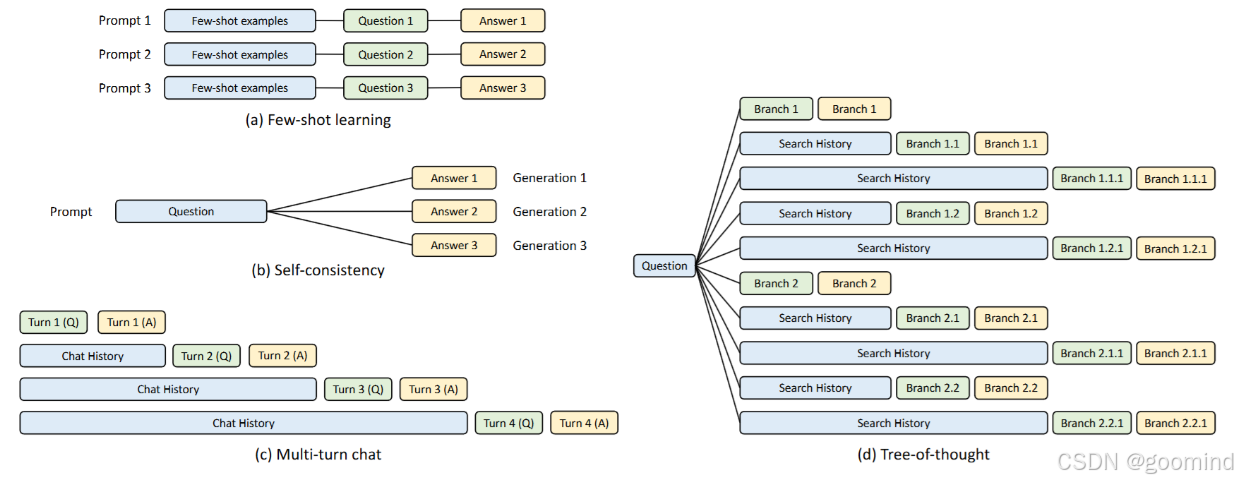
KV Cache共享示例,蓝色框是可共享的部分,绿色框是不可共享的部分,黄色框是不可共享的模型输出。
量化层面
简单介绍下什么是量化,以及介绍下基本的量化思路
介绍点经典工作,如GPTQ,AWQ
KVCache量化
1.58bit的BitNet
这个算法简单到让我头皮发麻,要不是真有人跑通了,我都不敢信这样量化真能跑。

















 904
904

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









