






————线程
1. 创建线程有哪些方式
thread:单继承、重写run方法,而不是start方法
runnable:实现接口,重写run方法
callable:使用futureTask或者future拿线程的执行结果

threadpool:

实际底层都是用runnable实现的
2. jvm垃圾收集过程与调优
3. 为什么不建议使用executors
无限队列
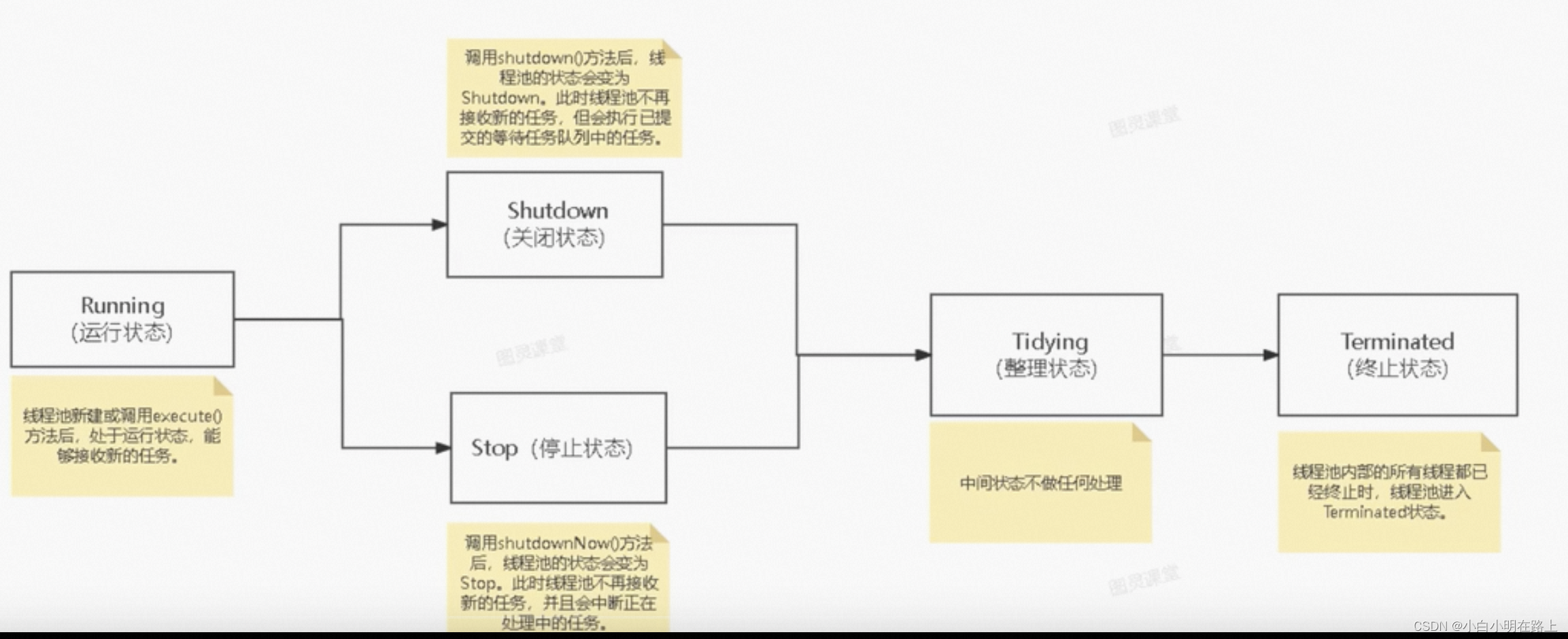
4. 线程池有哪些状态
5. sychronized和reentrantLock的区别

6. ThreadLocal有哪些应用场景,它的底层是如何实现的
threadLocalMap 线程安全 线程共享数据
7. reentrantLock的公平锁和非公平锁如何实现的


8. sychronized锁升级过程
偏向锁(单线程) 轻量级锁(多线程无并发,用户态) 重量级锁(多线程并发,内核态) 自旋锁
 9. tomcat为什么要使用自定义类加载器
9. tomcat为什么要使用自定义类加载器
jdk双亲委派
tom可以部署多个应用,每个应用存在很多类,并且应用类是独立的且可相同,每个应用是一个独立的加载器,去加载自己的类,从而类隔离
—————微服务与分布式
10. 微服务有什么好处

11. 微服务挑战
成本增加、复杂性挑战、部署挑战、一致性、监控与故障排除
12. 微服务解决方案
dobbo+zk(rpc)、netflix(闭源)、spring cloud alibaba
13. 微服务组件
注册中心nacos、consul、zk+dobbo,配置中心nacos config,远程调用feign、rpc,api网关gateway、分布式事务、熔断器sentinel、限流与降级sentinel、追踪和监控
14. 注册中心用来干什么的
管理各个服务的地址和元数据组件,用来服务发现和服务注册
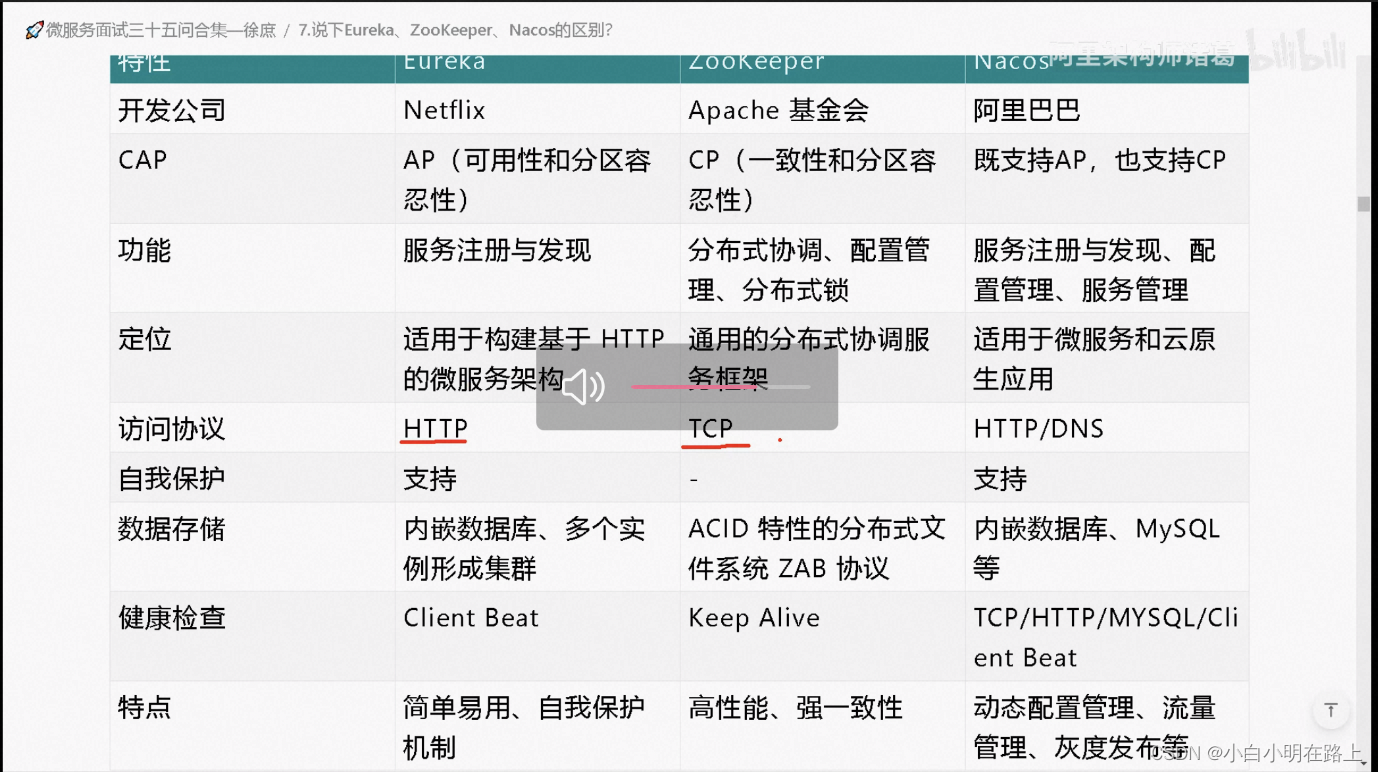
15. eureka、zk和nacos区别
16. 什么是分布式系统
不同组件部署在不同的服务器上,通过网络通信和协调的系统,也可以是一个组件的多个副本组成集群
17. 微服务与分布式系统区别
微服务如果不同组件部署在不同的服务器就是分布式系统。分布式不是微服务,不同领域,系统部署方式,微服务是应用架构
18. 分布式cap原则
p 分区容错性、c一致性(所有节点在任意时间看到的数据是一样的)、a可用性(服务是一直可用,异步请求不可同步等待)
19. base理论:基于cap演化
ba:基本可用 、s:软状态、e:最终一致性
20. 分布式事务
ACID:原子性、一致性、隔离性、持久性
21. 实现方案
2PC(数据库):准备阶段(开启事务、业务流程。缺点:全局阻塞、资源浪费)、提交/回滚
事务协调者首先询问所有参与者是否都ok,ok后进行事务提交,全局阻塞。问题:如果有参与者询问阶段就不可用,则会浪费
3PC:canCommit、preCommit、doCommit(仍然全局阻塞,只是节约了询问阶段可能会出现不可用情况的资源浪费)
事务协调者先问参与者都在不在,然后事务协调者首先询问所有参与者是否都ok,ok后进行事务提交,全局阻塞
TCC(try(业务检查一下是否可用)、confirm(提交)、cancel):代码逻辑,实现Tcc三个方法。1. try阶段 2.confirm。事务间不阻塞,粒度变小,异常执行cancel
saga(流水线事务):不要求隔离性。 1.提交事务 2.完成 异常情况:反向回滚
消息最终一致性:消息重试
22. 分布式锁的实现方案
1)数据库
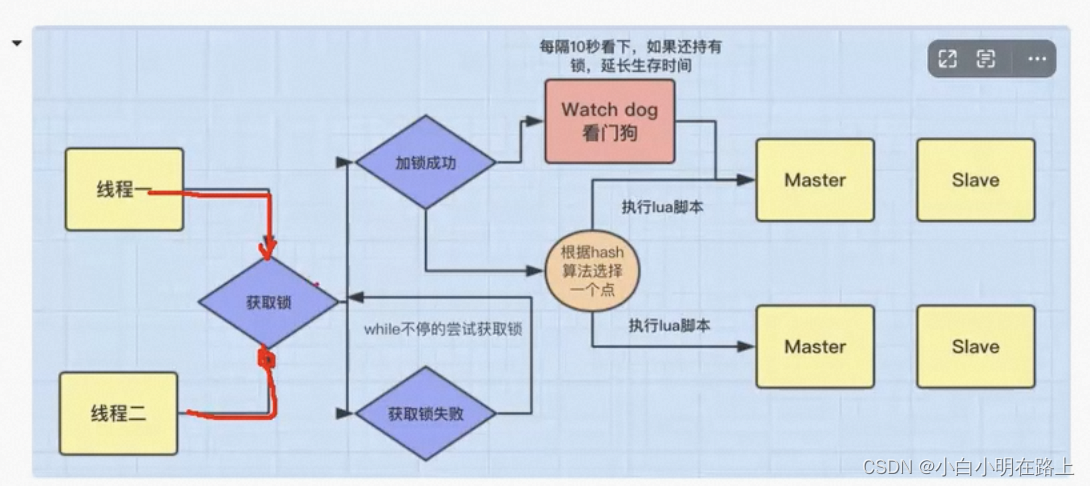
2)redis(setnx、redisson看门狗逻辑,每隔10秒看一眼,延长生存时间,使用lua脚本,保证原子性,使用红锁(所有节点都完成同步才返回上锁成功))
3) zk:根据线程来的顺序创建临时节点,处理完成释放节点,按顺序执行节点,且用watch监视节点是否释放,如果现在是最前面的节点,则执行
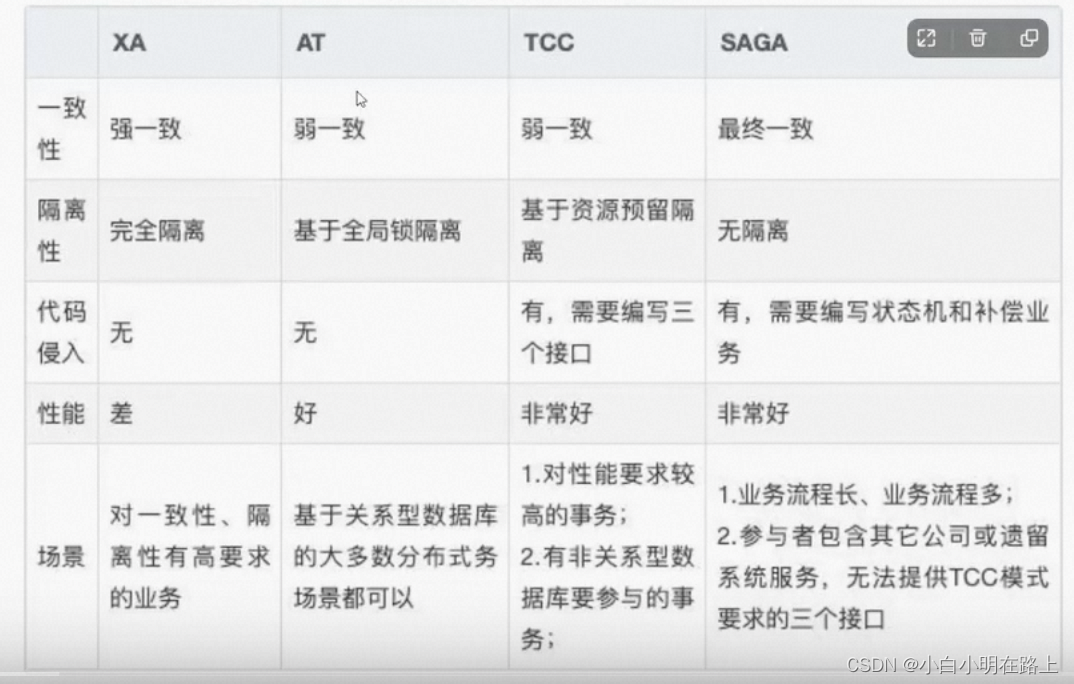
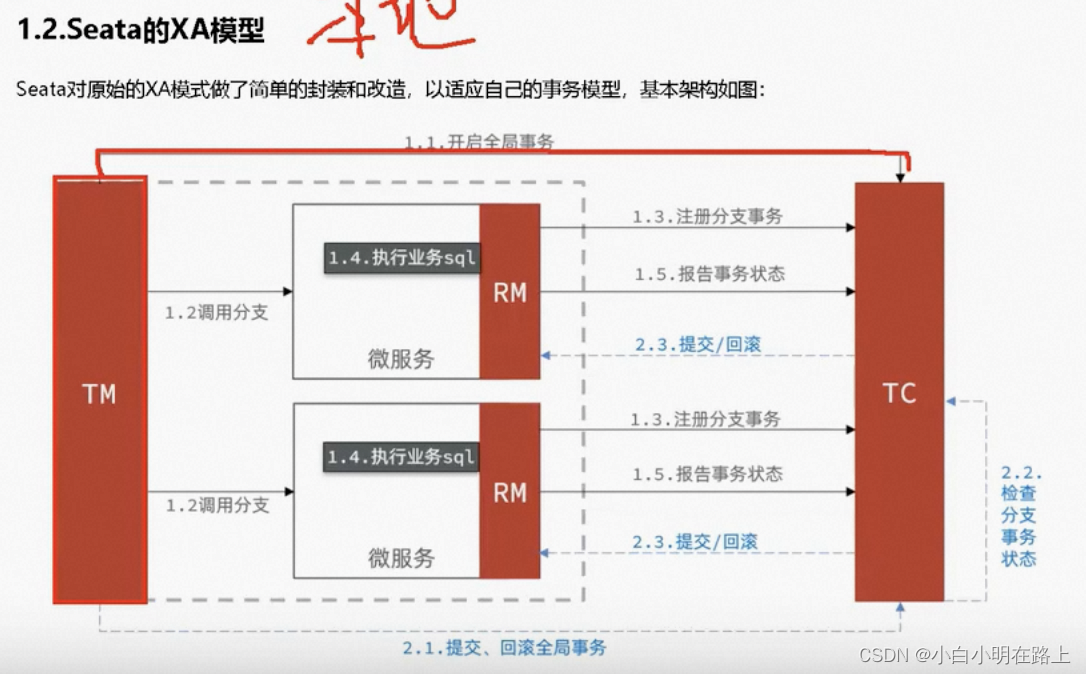
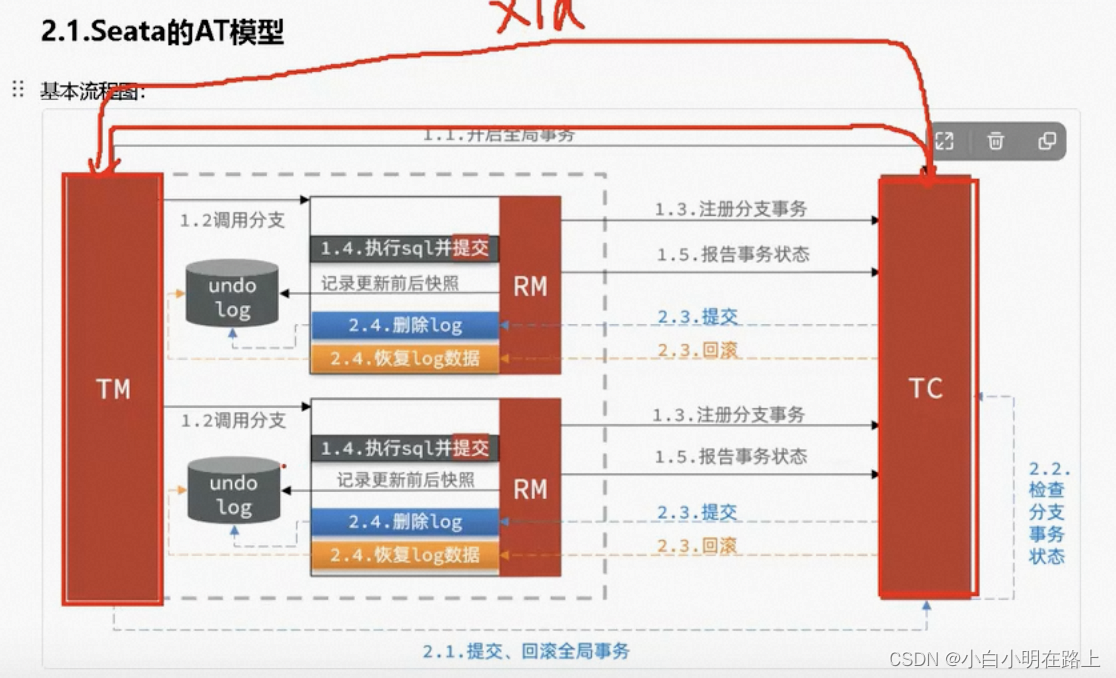
23. seata
TM、TC、RM

XA、AT模型
————jvm
24.类的生命周期
加载-》连接(验证、准备/初始赋值、解析/从字符引用解析成内存引用)-〉初始化new-》使用-〉卸载

25. 加载器
作用类的唯一性,只加载一次,保证安全性
java1.8
启动类加载器、扩展类加载器、应用程序加载器、自定义类加载器
双亲委派模式 从启动类开始加载,直到加载成功。
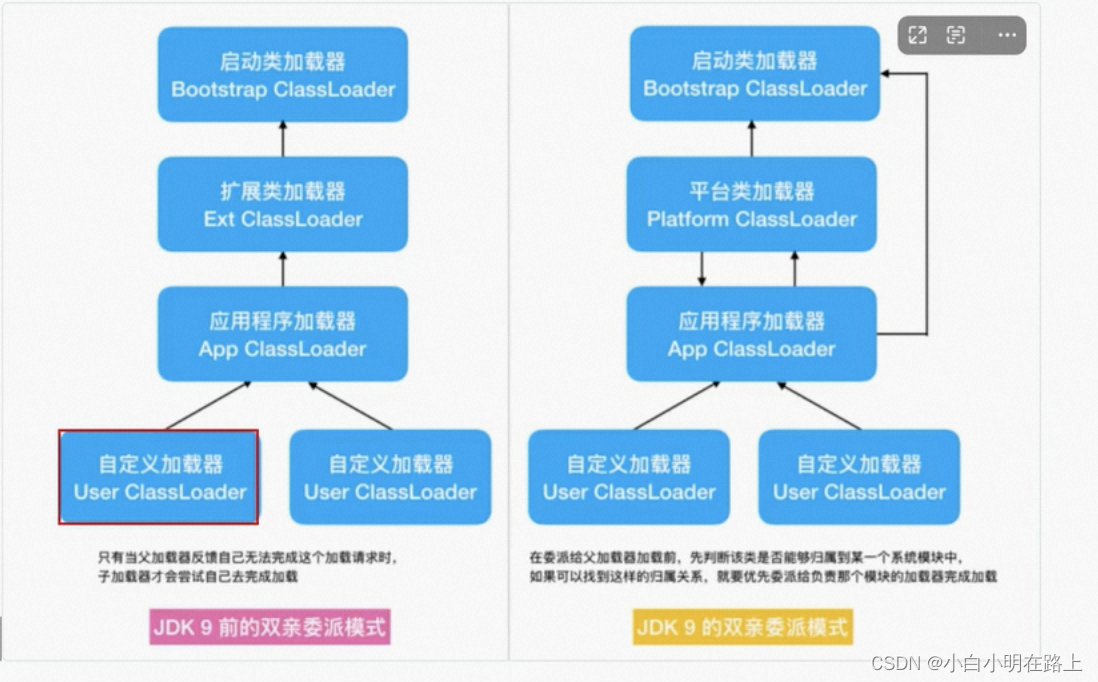
java1.9引入模块化,模块制定加载器,每个模块指定自己的类加载器,到平台加载器就不往上指派了
启动类加载器、平台类加载器、应用程序加载器、自定义类加载器
可以直接制定平台加载器,提升性能

26. jvm内存区域
元空间、堆 线程共享
1)类结构、常量、静态变量、字符串在元空间
2)new在堆中
栈、本地方法栈、程序计数器 线程私有
1)方法执行压栈、局部变量存在栈
27. 对象创建过程
new,首先去常量池去拿类元素信息,如果没拿到去加载;然后去堆分配内存,使用空闲列表:CMS java1.8 /空闲列表:G1 8以后/指针碰撞
;接着做初始化零值、对象头设置、init初始化对象init(字节码层面):init是对对象级别的变量或者非静态代码块进行初始化、clinit静态变量或静态代码块进行初始化
28. 对象内存分配方式
指针碰撞(分界指针)和空闲列表 cms空闲列表,g1指针碰撞
29. new时,堆会发生抢占吗?如何解决的
TLAB(Thread Local),每一个线程都会提供一个分配内存的缓冲区,默认为eden1%、TLAB分配失败,通过CAS分配
30. 对象内存布局
对象头、实例数据、对齐填充
对象头
1)markword(锁、分代年龄、hashcode) 32位:4+4+4,64位:8+8+4字节
2)klass pointer类型指针
3)数组长度
实例数据
对齐填充,8字节的倍数,为了返回效率
31. 内存泄漏哪些原因(没有正常释放且jvm不回收 )
- 静态集合类
- 单例
- 数据连接、IO、socket
- 变量不合理的作用域
- hash值变化,String被设置成了不可变类型
- ThreadLocal使用不当 value为强引用类型
32.如何判断对象存活
可达性分析:gc root根节点
1)虚拟机栈(栈帧中的本地变量表)各个线程被调用的方法中使用的参数、局部变量
2)方法区中类静态属性引用的对象,java引用类型静态变量
3)方法区常量引用的对象,String
4)所有被同步锁synchronized持有的对象
33. 垃圾收集算法
标记-清除
标记-复制
标记-整理
34. 三色标记
stw变为并发标记:为了减少stw。避免重复扫描对象,提升效率
三个颜色
白色:没有标记(垃圾)
灰色:被标记过。但对象的下属没有全标完(gc需要从此对象去寻找垃圾)
黑色:对象和下属全部标记(程序需要的对象)
存在问题:stw不会发生变动
三色标记是异步标记,对象间引用可能会发生变化,产生浮动垃圾(消失引用)和对象漏标(突然新增引用)
cms和g1都有处理
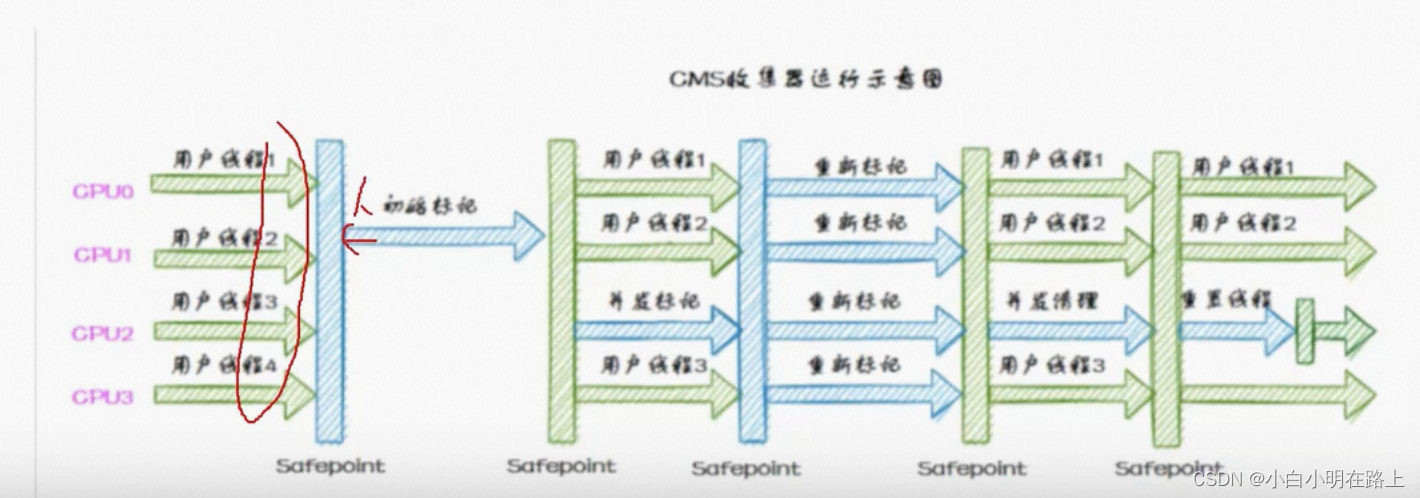
35. cms收集过程
初始标记stw单线程、并发标记(三色标记)、重新标记stw多线程、并发清除
36. g1回收器
region:可以精细的进行控制,可预测停顿时间,内存碎片控制、优先级处理
指针碰撞分配内存
为什么g1采用:更小内存成本低
初始标记、并发标记、最终标记、筛选回收
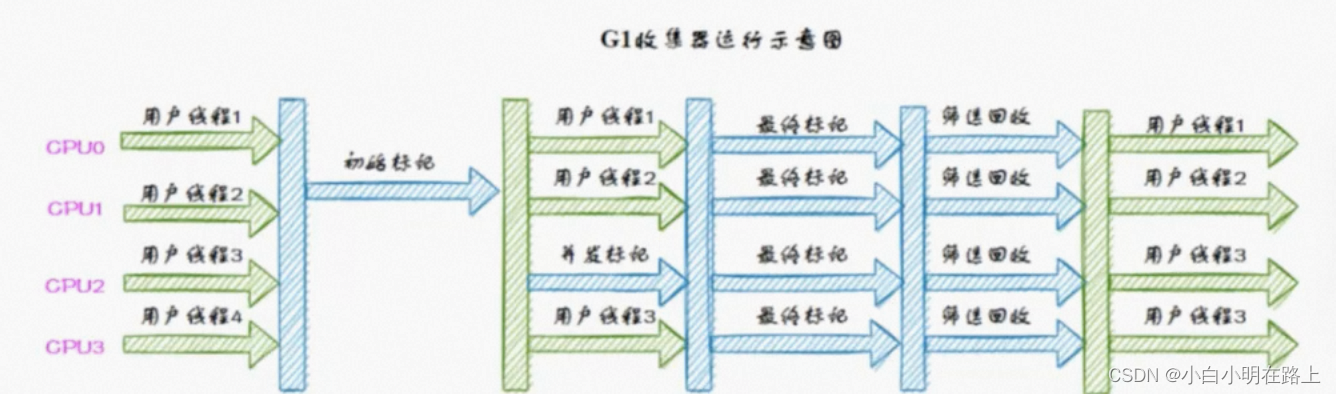
37. 为什么要引入g1
cms优点:并发收集、低停顿
缺点:内存碎片多、并发依赖cpu资源,可能抢占用户线程、产生的浮动垃圾必须依赖下次gc回收
1)大内存中g1更有优势
2)碎片少、可设定stw
38. 用了什么垃圾回收器?为什用它?

ParNew+cms标记清除 4-8g内存
适用:高并发 toC
parallel scavenge+ parallel old 标记整理
适用:toB 数据处理
标记清除 4g以下

(可选择,9默认)g1:标记复制:年轻代 标记整理:老年代
适用:大内存应用,可预测stw应用
8g以上
zgc:适用于需要极低停顿时间(毫秒级别)的大内存应用
内存密集型数据库,金融交易,云服务
几百g以上
39. 对象一定分配在堆上吗
逃逸分析:逃逸了放在堆中
对象大放在堆中
逃逸强度:不逃逸、方法逃逸、线程逃逸
对象栈分配的好处
栈上分配:随着栈帧出栈而销毁
同步消除:线程安全
标量替换:可以不用创建对象,用若干个成员变量替换,可以让对象成员变量在栈上分配和读写
40. jvm监控和故障处理工具
JConsole、visual vm
命令:jps 查看进程
jstat、jmap dump文件、jhat、jstack分析死锁线程
阿里阿尔萨斯
41. jvm常见参数
xmx最大堆 xms初始堆
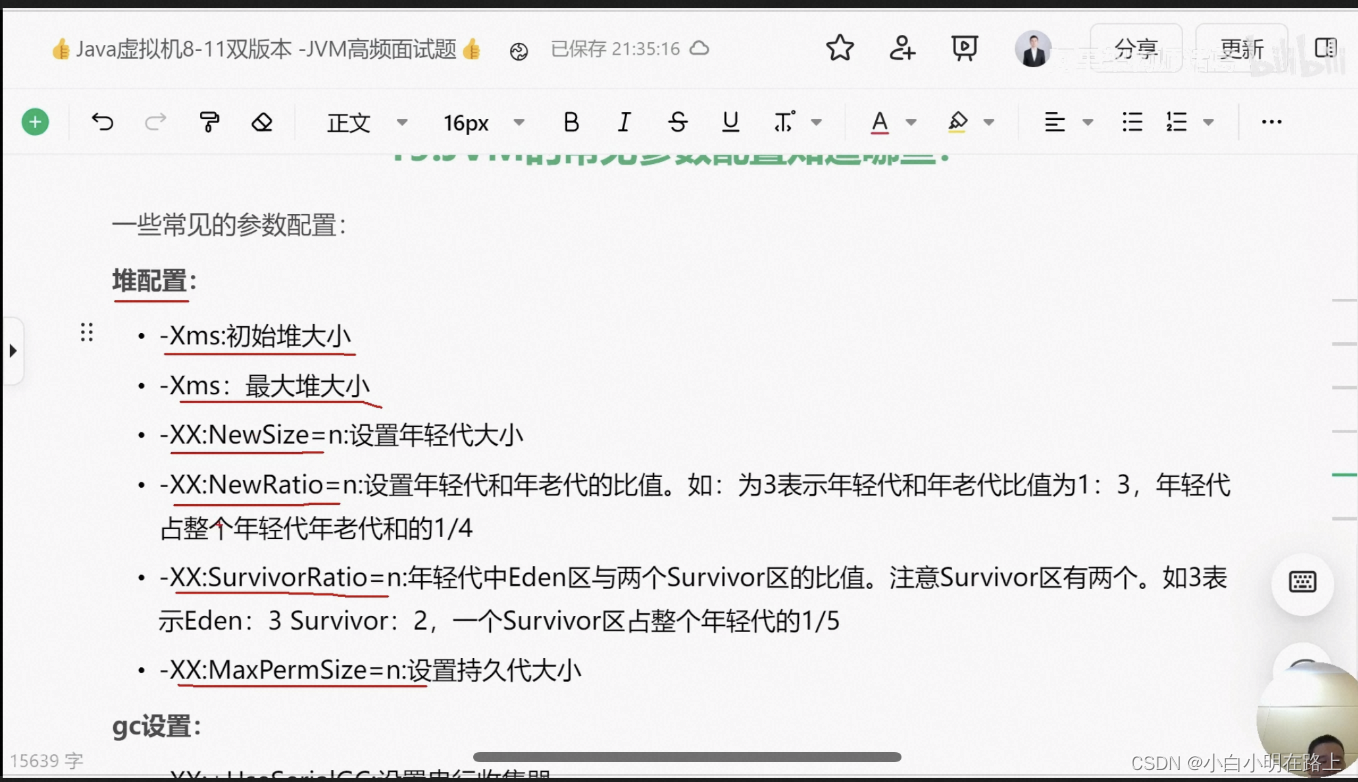
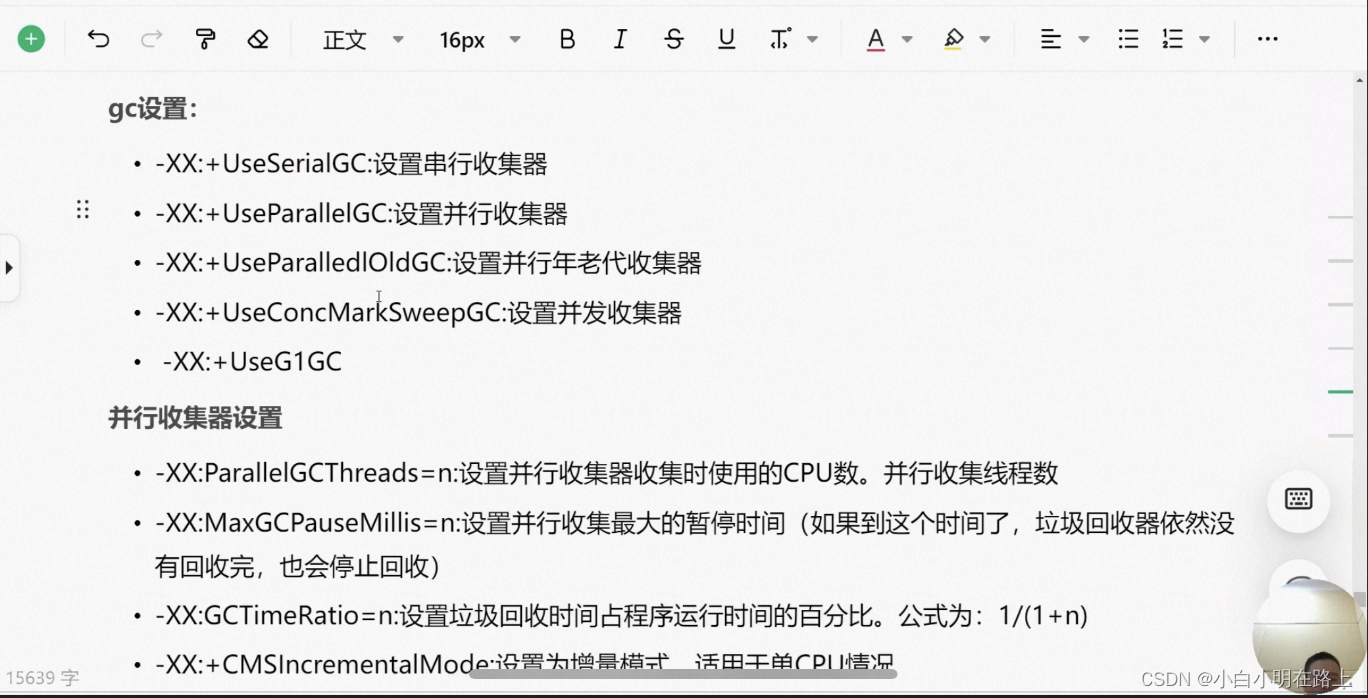
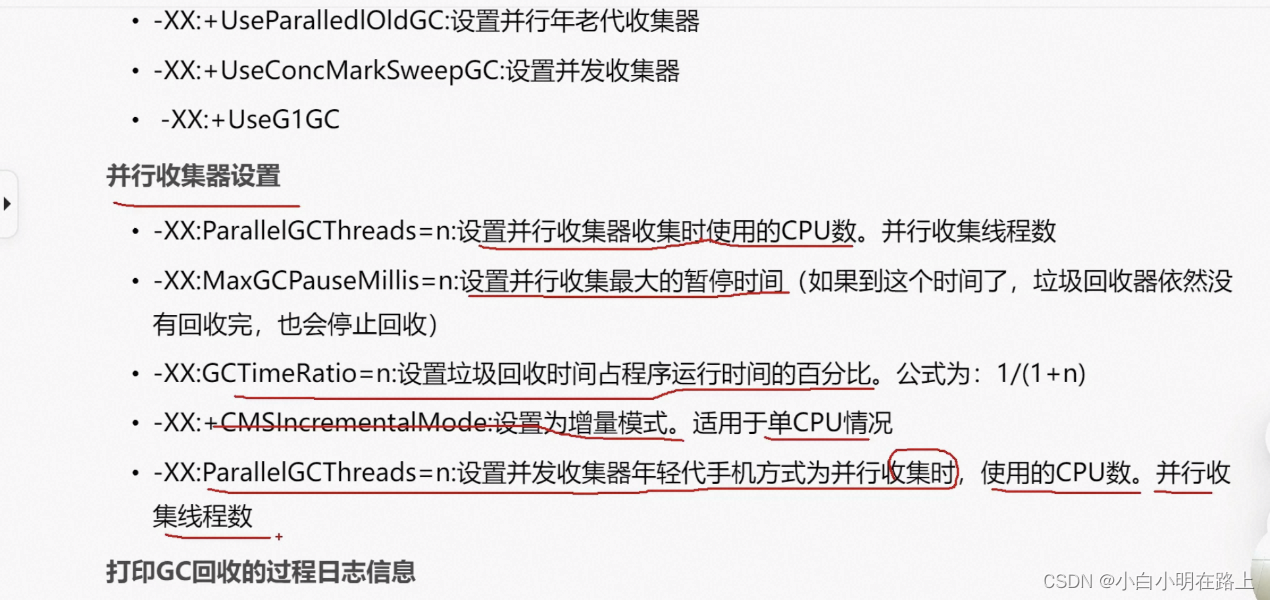

42. jvm调优
43. 线上服务cpu占用过高怎么排查
1.top 找到pid,2.找到线程转成16进制 3.jstack 进程id |grep 16进制线程id -A 20,查看哪里报错
44. 内存飙高问题怎么排查定位
1)创建大量对象 2)内存泄漏对象无法回收
看哪些对象占用内存多,看gc情况是否正常回收
用jmap查看对象占用情况
45. 频繁 minor gc
jstat -gc pid 1000
新生代空间小、eden很快被填满,导致频繁minor gc -xmn
如果full gc可以回收掉大部分,那说明年轻代内存小
46. 频繁full gc怎么办
大对象、内存泄漏、长生命周期对象、程序bug、jvm参数问题
47. 排查oom问题
- 一次性申请太多:更改申请对象的数量
- 内存资源耗尽未释放:找到未释放的对象进行释放
- 本身资源不够:jmap -heap查看堆信息
————-kafka—————
48. 消息丢失,与如何解决
发送端
acks=0,无需确认
acks=1,等待确认,如果消息发到从节点,同步失败,消息可能会丢
acks=-1,等待所有备份(主从)成功才回复
接收端,如果设置的是自动提交,消费过程中宕机,则消息丢失。设置为手动提交
49. 重复消费几种情况,如何解决
发送端:重试机制,网络抖动那,重复发送
接收端:手动提交,未处理完,服务挂了,重启重复消费
50. 消息积压如何解决
1)发送方发消息快,消费端慢。
修改消费端程序,让其将收到的消息快速转移到别的topic,然后启动多个消费者
2)数据格式变动或消费者程序bug,死信队列
—————-sql—————-
51. 创建索引注意点
1)频繁使用字段
2)利用率不高的不创建
3)最左前缀匹配原则
4)频繁更新不要创建
5)尽可能用联合索引代替多个单个索引
6)字段长用前缀索引
7)不建议用无序的值,频繁创建叶子结点,出现磁盘碎片化
52. 索引哪些情况会失效

53. 事务的四大特性与实现原理
ACID
- 原子性:整体执行,使用锁和mvcc实现
- 一致性:最终一致,undo log逻辑日志,回滚时做相反操作
- 隔离性:并发事物隔离,redo log重做日志,物理日志,每次提交需将所有日志写入redo log才算完成
- 持久性:持久存储,redo log
54. 事务的隔离级别
- 读未提交:读不加锁,不影响其他读和写;写加锁。影响其他的鞋,不影响读
- 读已提交&可重复读:利用了readview和mvcc,每个事物只能读取它看到的版本
读已提交:每次都会生成一个readview
可重复读:每次第一次生成一个readview
- 串行化:读和写都加锁
55.mysql主从复制
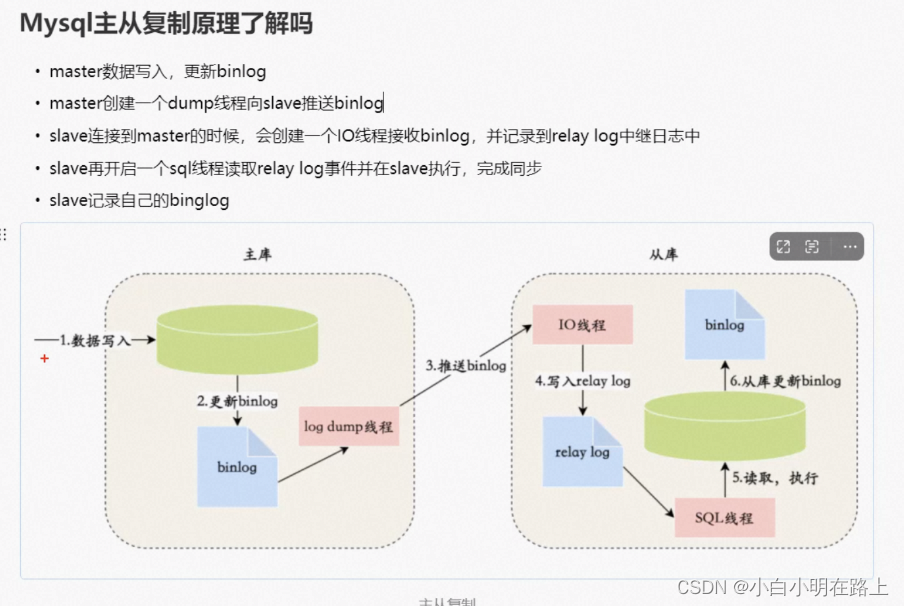
56. mysql主从同步延迟,如何处理
- 主从同步延迟的原因
主库有较大更新并发时,可能会导致延迟,因为从库只有里面读取binlog的线程只有一个,当某个sql执行时间较长时,会导致主库的大量sql积压,未同步到从库,导致主从不一致
- 解决方法
1)写操作后的读操作指定到主库上去,对业务逻辑有侵入
2)读从库失败后,再读一次主库,大大增加主库的压力
3)关键业务读读写都指向主库,其他读写分离
57. 水平分表有哪几种理由方式
就是数据应该分到哪一张表
1)范围路由,优点:容易扩充,缺点:数据分布不均
2)hash路由,优点:分布均匀,缺点:初始表数量,需评估;加表工作量大
3) 配置路由映射表
优点:设计简单,扩容简单;问题:每次都多一次查询,可能数据量大
58. 分库分表,不停机扩容
- 一阶段:数据双写,读老库
1)在线双写,读老库
2)跑数据迁移程序(中间件)
3)定时任务处理差异数据
- 二阶段:数据双写,读新库
- 三阶段:旧库下线
59. 分库分表带来的问题
- 事务问题
- 夸库join问题
- 夸节点的count、order by、group by以及聚合函数问题
- 数据迁移,容量规划,扩容问题
- 主键id问题
60. mysql数据库cpu飙升

—————线程————-
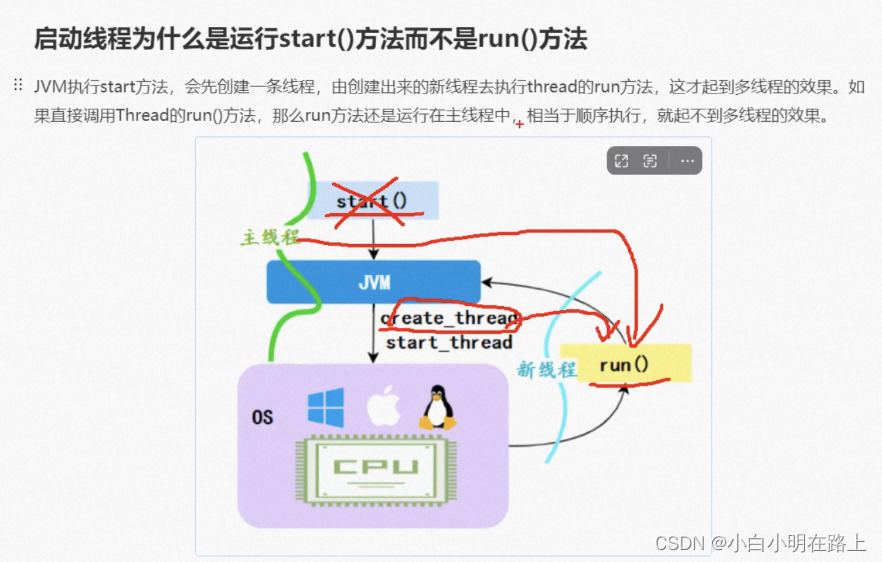
61. 启动线程为什么是start方法而不是run方法
62. 守护线程

63. 线程间有哪些通信方式
- volatile(共享内存)和synchronized(可见性、排他性
- 等待/通知机制
java内置的 wait和notify,一个对象修改了某值,另一个线程感知
- 管道输入/输出流
与普通的文件输入输出流不同,主要用于线程之间的数据传输,而传输的媒介是内存,使用不多
- 使用Thread.join
线程A等待Thread线程结束后运行,意味着Thread线程的修改可被线程A读取到
64. ThreadLocal使用场景

65. http与rpc的区别

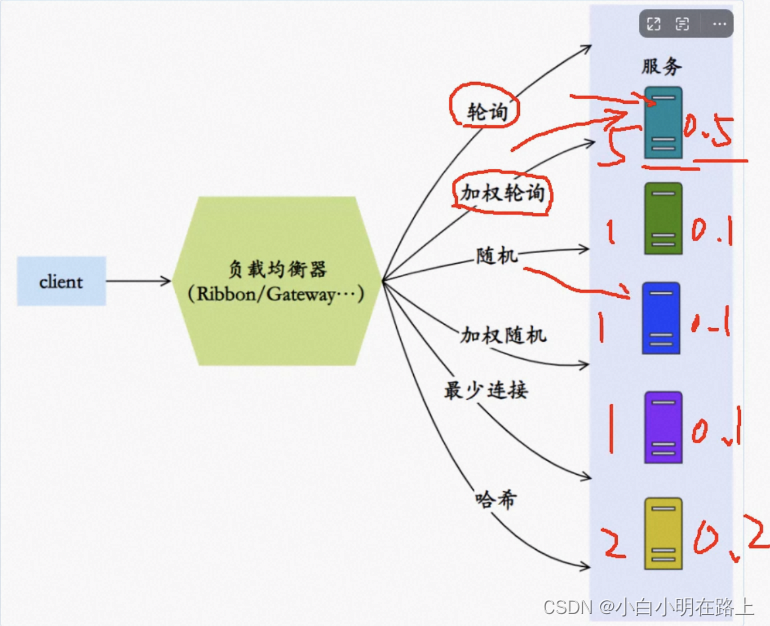
66. 负载均衡算法
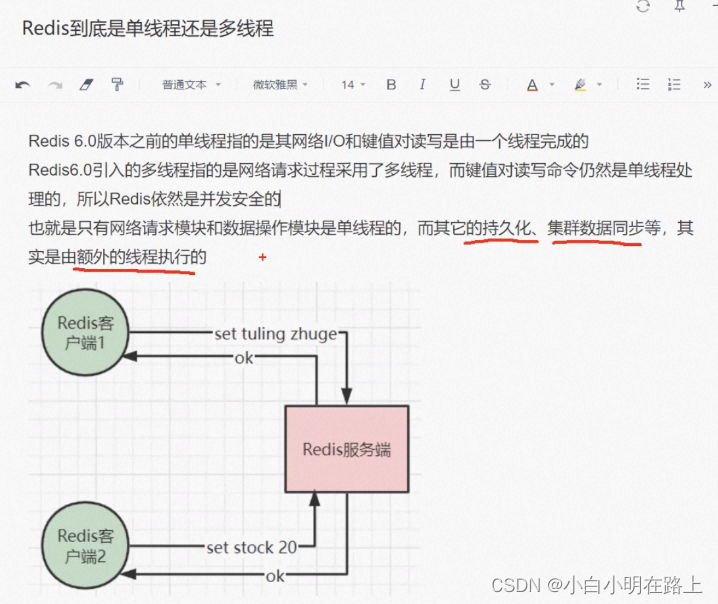
67. redis到底是单线程还是多线程
68. redis是单线程为什么还快
- 基于内存,一条命令可能几十纳秒
- 单线程,无额外线程切换开销
- IO多路复用机制提升redis的io利用率
- 高效的数据存储结构,全局hash表以及多种高效数据存储结构:跳表、压缩列表、链表
69. redis底层数据,如何用跳表来存储的
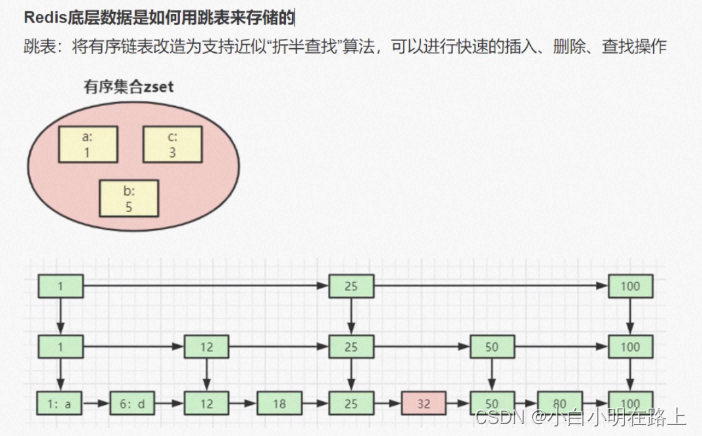
70. redis key过期了,为什么内存没有释放
- 没有设置过期时间
- 懒惰删除:下次查才触发删除
- 定时删除:每过一些时间才删除,默认为100ms
71. redis没有设置过期时间,为什么被主动删除了
内存淘汰策略:超过最大内存,就会做清理

72. redis淘汰key时,LRU和LFU的区别
- LRU 最近最少使用,淘汰很久没有被访问的数据,以最后一次访问时间作为参考
- LFU最不经常使用,淘汰最近一段时间,访问最少次数的数据
绝大多数情况使用LRU,如果存在大量的热点数据,则用LFU
73. 删除key的命令会阻塞redis吗
会的

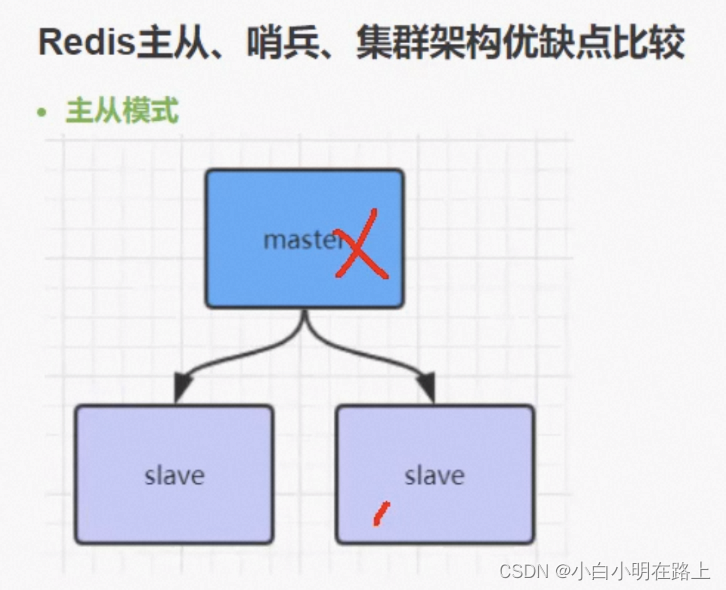
74. redis主从、哨兵、集群架构,优缺点
- 主从:从为主的备份,主挂了之后需要因为手动选取主节点
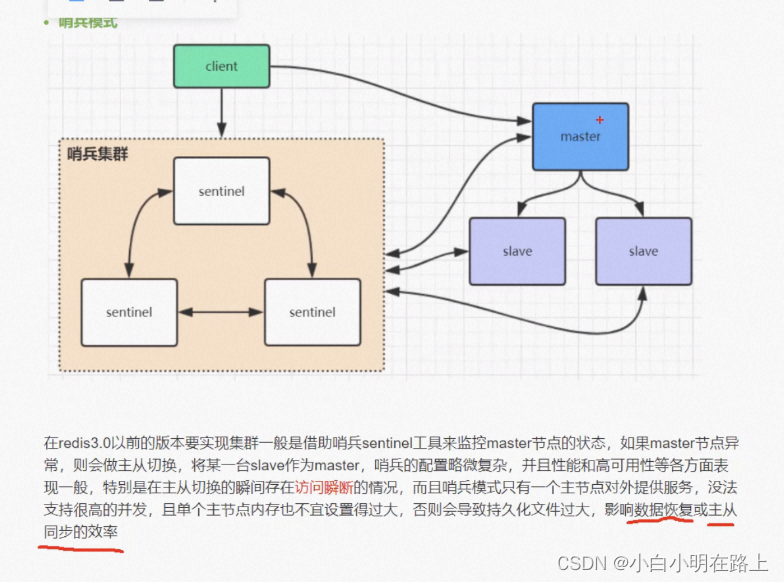
- 哨兵
由哨兵自动选举主节点
但主节点挂了后,重新选举时会产生闪断,且单节点只能支撑10个g左右的数据
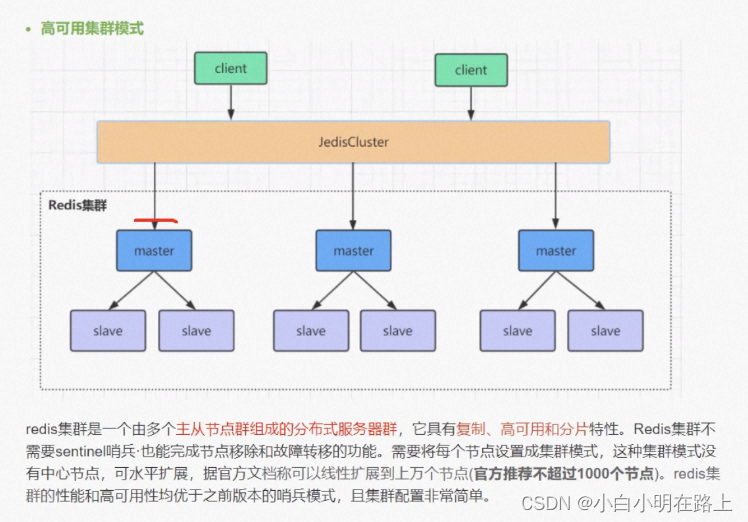
- 集群,可以成熟大数据量,服务器群不超过1000个,一个挂掉,其他的正常运行,影响部分数据,当挂掉的节点重新选举后,就可用了。复制、高可用、分片的特性
----------java-------------
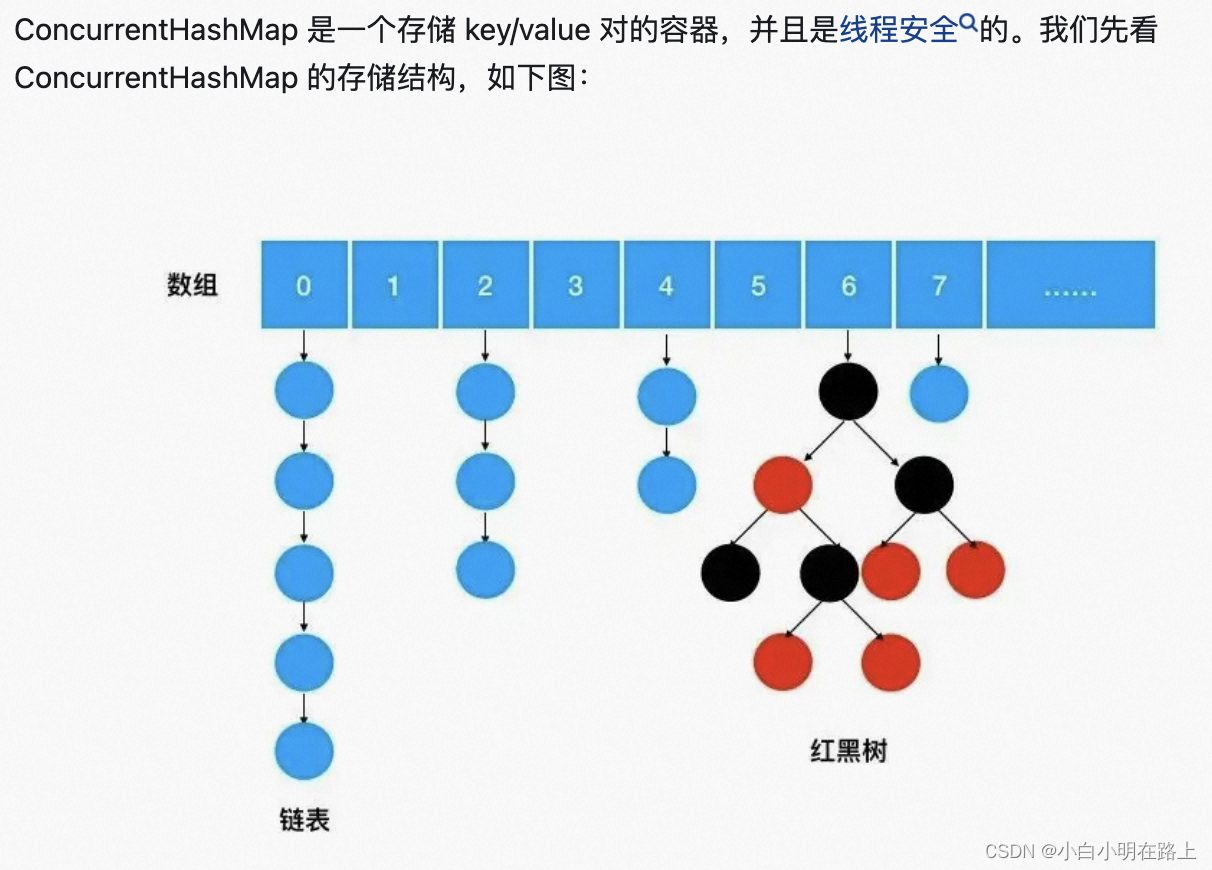
75. concurrentHashMap

spread 方法源码分析
哈希算法的逻辑,决定 ConcurrentHashMap 保存和读取速度。hash 算法是 hashmap 的核心算法,JDK 的实现十分巧妙,值得我们学习。
spreed 方法源代码如下:
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
} 传入的参数 h 为 key 对象的 hashCode,spreed 方法对 hashCode 进行了加工。重新计算出 hash。我们先暂不分析这一行代码的逻辑,先继续往下看如何使用此 hash 值。
hash 值是用来映射该 key 值在哈希表中的位置。取出哈希表中该 hash 值对应位置的代码如下。
tabAt(tab, i = (n - 1) & hash)我们先看这一行代码的逻辑,第一个参数为哈希表,第二个参数是哈希表中的数组下标。通过 (n - 1) & hash 计算下标。n 为数组长度,我们以默认大小 16 为例,那么 n-1 = 15,我们可以假设 hash 值为 100,那么 15 & 100 为多少呢?& 把它左右数值转化为二进制,按位进行与操作,只有两个值都为 1 才为 1,有一个为 0 则为 0。那么我们把 15 和 100 转化为二进制来计算,java 中 int 类型为 8 个字节,一共 32 个 bit 位。
n 的值 15 转为二进制:
0000 0000 0000 0000 0000 0000 0000 1111
hash 的值 100 转为二进制:
0000 0000 0000 0000 0000 0000 0110 0100。
计算结果:
0000 0000 0000 0000 0000 0000 0000 0100
对应的十进制值为 4
76.如何实现一个ioc容器

77.什么是字节码,字节码的好处是什么?

78. 如何实现订单15分钟未支付自动取消?
方案一:数据库定时任务轮询
方案二:jdk延迟队列
方案三:时间轮算法
方案四:redis缓存
1. 定时轮询有序集合zset,使用score存储时间戳
2.key过期事件监听
3.redis 6 客户端缓存监听方案
方案五:消息队列 延迟消息
79.MCVV底层实现原理
db事务隔离级别
1. 读未提交,产生脏读:读到未提交的数据
2. 读已提交,产生不可重复读:一个事务两次读取,取到的值不一样
3.可重复读,产生幻读。在统计数据时,会产生不同的结果。是由于可重复读,只能保证行数据一致,但不保证表所有数据一致
4.序列化
MVCC(多版本并发器)
MVCC主要有三个东西
1. 三个隐藏列,主要是有个记录事务id和上一个版本数据的地址
2. 各版本的数据存在undolog中,已链表的形式存储,每次数据变更都会在undolog中生成一条新纪录
3. readview记录事务的id,有当前事务,未提交事务,未开始事务。通过三个id可以去undolog中找到对应数据
读未提交,无需mvcc
读已提交:每次查询都会创建readview读取数据
可重复读:每次查询都会第一次创建readview
串行化:表锁















 9008
9008











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









