






1. JDK、JRE、JVM
JDK 包含了 JRE 和 JVM,JRE 包含了 JVM。
JDK(Java SE Development Kit):JDK 包括 JRE 和命令行开发工具,如编译器和调试器,程序开发者必须安装 JDK 来编译、调试程序。
JRE(Java SE Runtime Environment):JRE 提供了 Java 运行时环境以及 JVM运行需要的类库。如果只是运行 Java 程序,可以只安装 JRE,不用安装 JDK。
JVM(Java Virtual Machines):Java 虚拟机是 JRE 的一部分,它具有指令集并在运行时操作内存,是一种抽象计算机,不同的操作系统使用不同的 JVM,JVM 是 Java 实现跨平台的核心,负责解释 class 文件为平台无关的字节码。
2. BIO、NIO、AIO
BIO、NIO、AIO 有什么区别?
BIO:Block IO 同步阻塞式 IO,就是我们平常使用的传统 IO,它的特点是模式简单使用方便,并发处理能力低。
NIO:Non IO 同步非阻塞 IO,是传统 IO 的升级,客户端和服务器端通过 Channel(通道)通讯,实现了多路复用。
AIO:Asynchronous IO 是 NIO 的升级,也叫 NIO2,实现了异步非堵塞 IO ,异步 IO 的操作基于事件和回调机制
3. Java 容器都有哪些?
Java 容器分为 Collection 和 Map 两大类,其下又有很多子类,如下所示:
Collection包括:List、Set、Queue
Collection
- List
- Set
- Queue
Map
- HashMap:基于哈希表实现,无序,键值对存储,线程不安全,查找、添加和删除操作高效
- LinkedHashMap:保留插入顺序(或访问顺序),键值对存储,其他特性类似于HashMap
- TreeMap:基于红黑树实现,有序(键按自然排序或自定义比较器排序),键值对存储
- ConcurrentHashMap:线程安全的哈希表,适用于高并发环境,性能优于同步的HashMap
- HashTable:过时的线程安全哈希表,已被ConcurrentHashMap替代
4.Collection 和 Collections 有什么区别?
Collection 是一个集合接口,它提供了对集合对象进行基本操作的通用接口方法,所有集合都是它的子类,比如 List、Set 等。
Collections 是一个包装类,包含了很多静态方法,不能被实例化,就像一个工具类,比如提供的排序方法:Collections. sort(list)
5.HashMap 和 Hashtable 有什么区别?
存储:HashMap 运行 key 和 value 为 null,而 Hashtable 不允许。
线程安全:Hashtable 是线程安全的,而 HashMap 是非线程安全的。
推荐使用:在 Hashtable 的类注释可以看到,Hashtable 是保留类不建议使用,推荐在单线程环境下使用 HashMap 替代,如果需要多线程使用则用 ConcurrentHashMap 替代
6.ArrayList 和 Vector 的区别是什么?
线程安全:Vector 使用了 Synchronized 来实现线程同步,是线程安全的,而 ArrayList 是非线安全的。
性能:ArrayList 在性能方面要优于 Vector。
扩容:ArrayList 和 Vector 都会根据实际的需要动态的调整容量,只不过在 Vector 扩容每次会增加 1 倍,而 ArrayList 只会增加 50%
7. ConcurrentHashMap


ConcurrentHashMap的get操作为什么不需要加锁
get操作可以无锁是由于Node的元素val和指针next使用volatile修饰的,在多线程环境下线程A修改节点的val或者新增节点的时候对线程B可见的。
数组上的volatile的目的是:为了使得Node数组在扩容的时候对其他线程具有可见性而加的volatile
7.1重点方法
initTable


put

/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
//1. 计算key的hash值
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//2. 如果当前table还没有初始化先调用initTable方法将tab进行初始化
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//3. tab中索引为i的位置的元素为null,则直接使用CAS将值插入即可
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//4. 当前正在扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
//5. 当前为链表,在链表中插入新的键值对
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 6.当前为红黑树,将新的键值对插入到红黑树中
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// 7.插入完键值对后再根据实际大小看是否需要转换成红黑树
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//8.对当前容量大小进行检查,如果超过了临界值(实际大小*加载因子)就需要扩容
addCount(1L, binCount);
return null;
}
get
大致可以分为以下步骤:
- 根据 key 计算出 hash 值,判断数组是否为空;
- 如果是首节点,就直接返回;
- 如果是红黑树结构,就从红黑树里面查询;
- 如果是链表结构,循环遍历判断。
get 方法不需要加锁。因为 Node 的元素 value 和指针 next 是用 volatile 修饰的,在多线程环境下线程A修改节点的 value 或者新增节点的时候是对线程B可见的
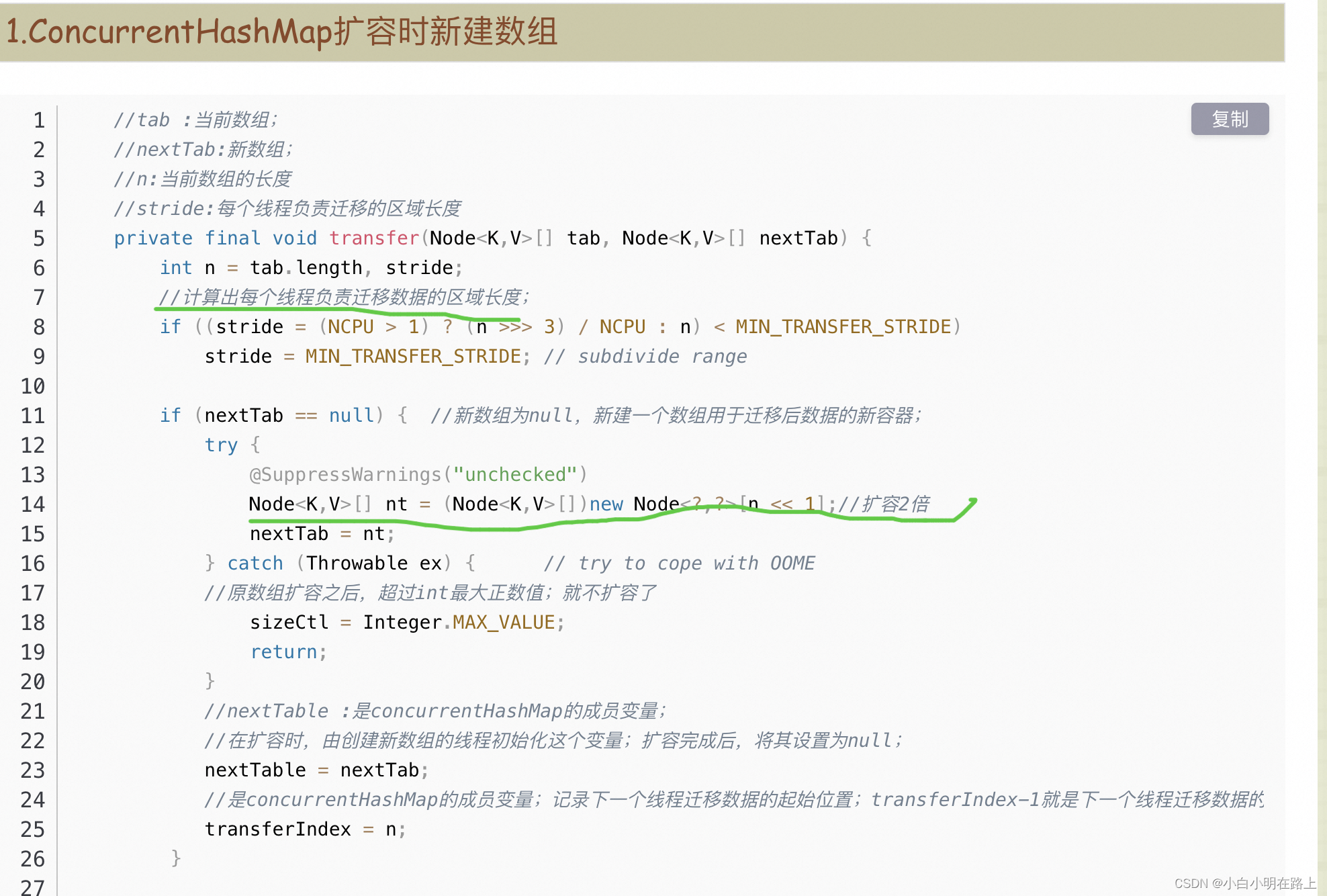
tryPreSize,transfer,helpTransfer扩容
ConcurrentHashMap(JDK1.8)的扩容方法transfer的源码分析_concurrenthashmapchm扩容流程,怎么解决并发-CSDN博客
扩容过程
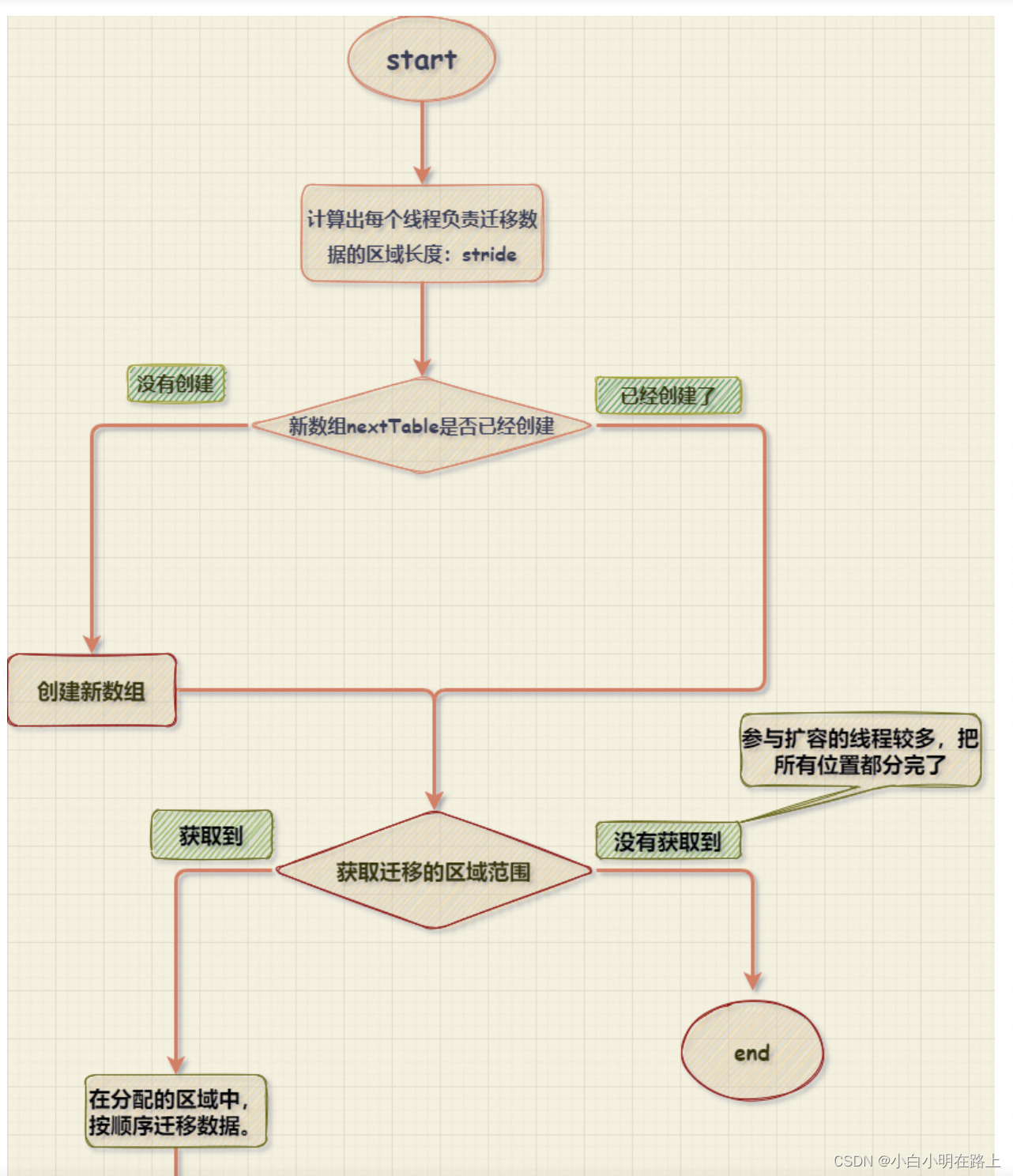
什么实时机扩容

第一步新建数组,并分配每个线程负责区域
第二步:数据迁移rehash
链表迁移(很恶心的流程,反常理,扩容后一个链表会拆成两个,第一遍遍历会找到最后一个连续的链表,然后再遍历一遍,用头插法把相应的节点插入到链表中。这样的好处是利用了原有对象,没有额外的空间产生)
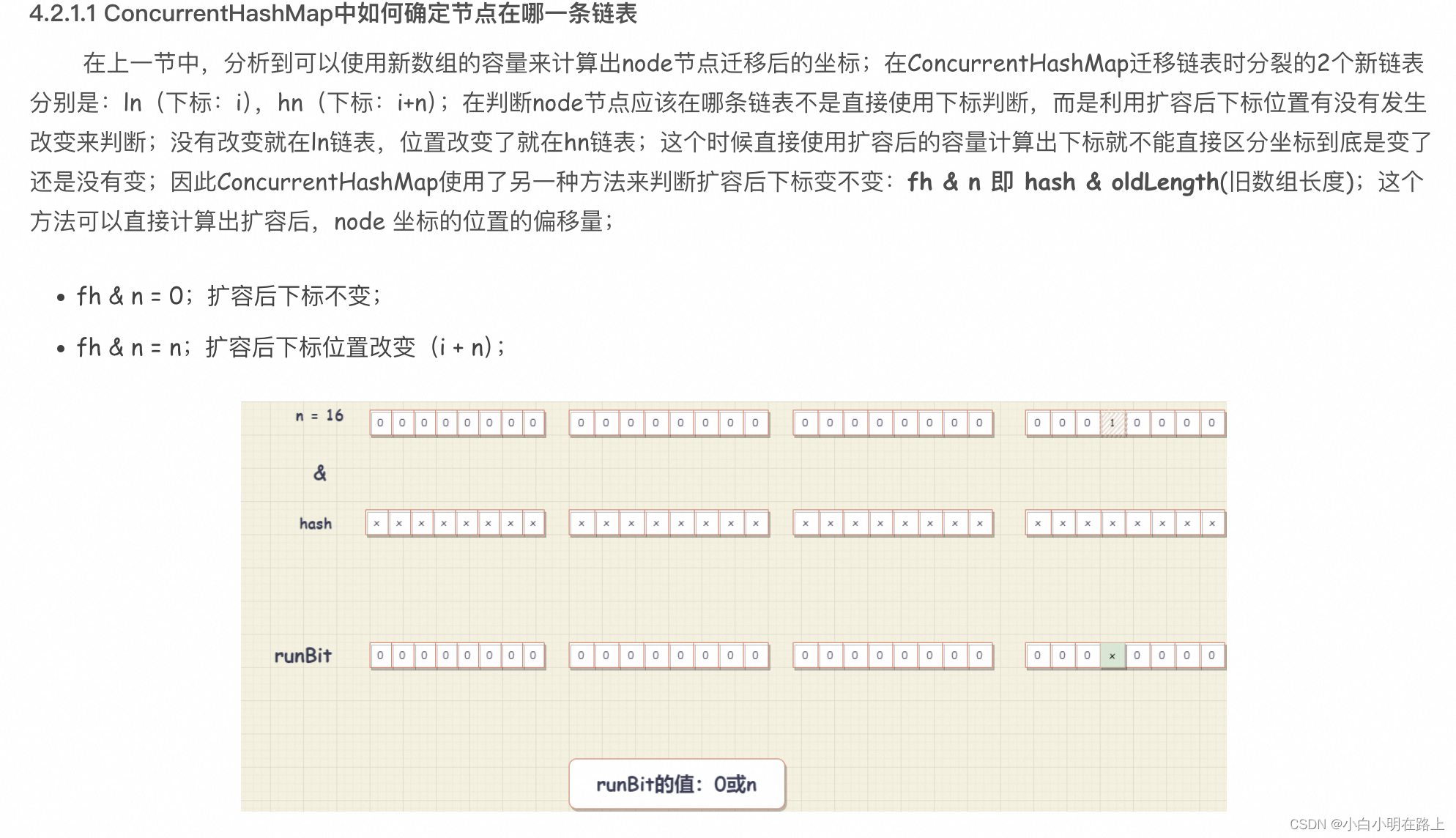

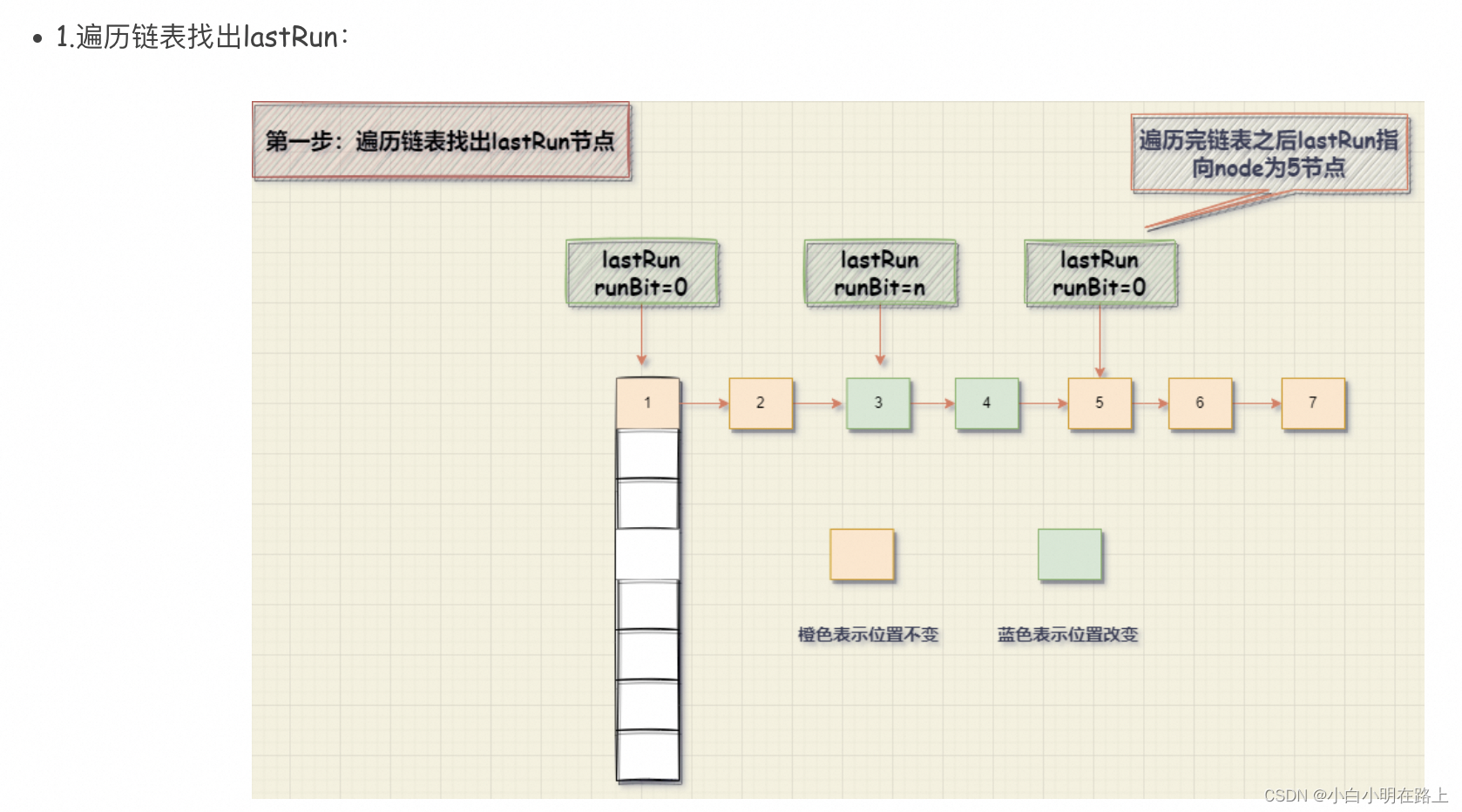
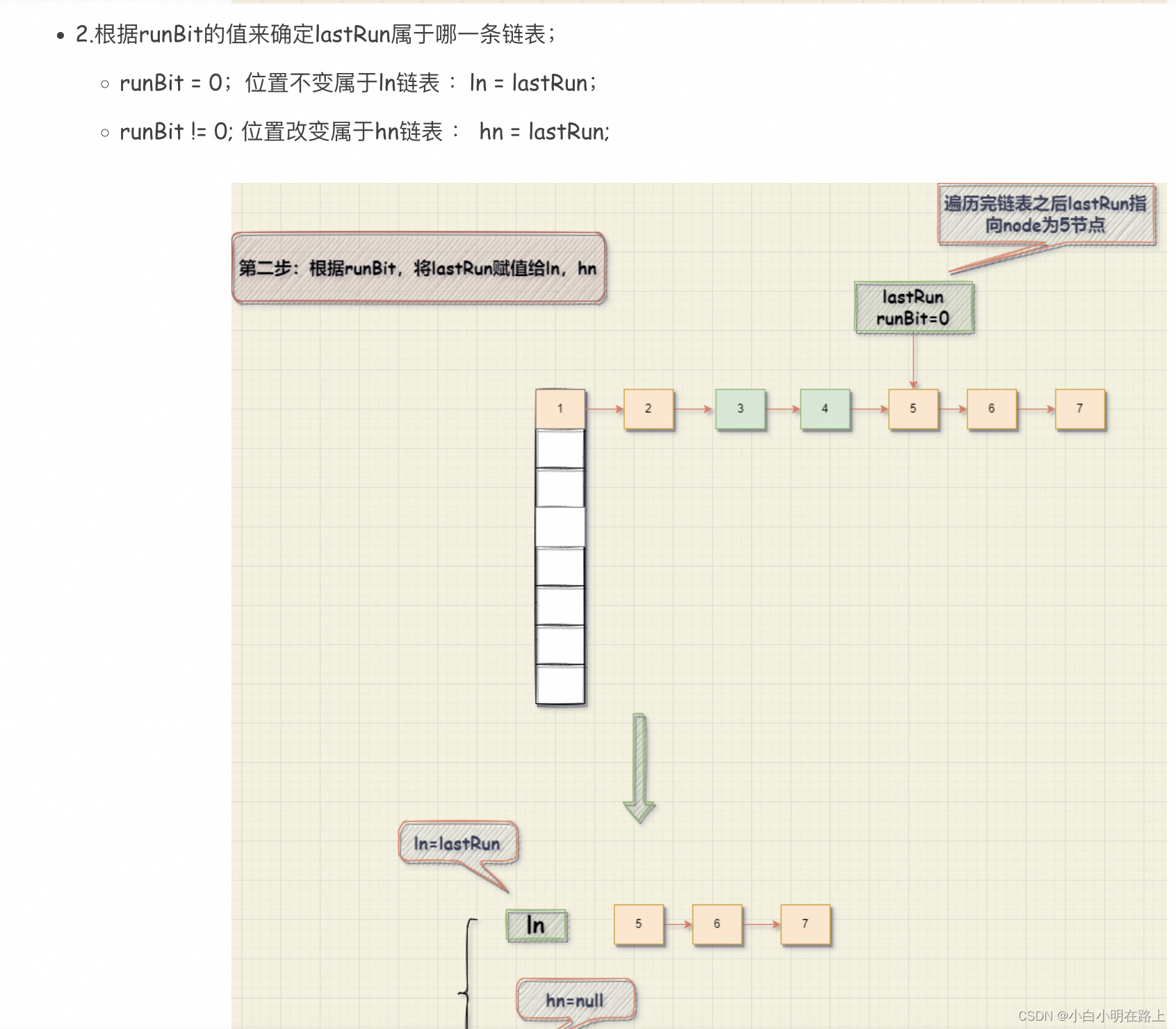
红黑树迁移
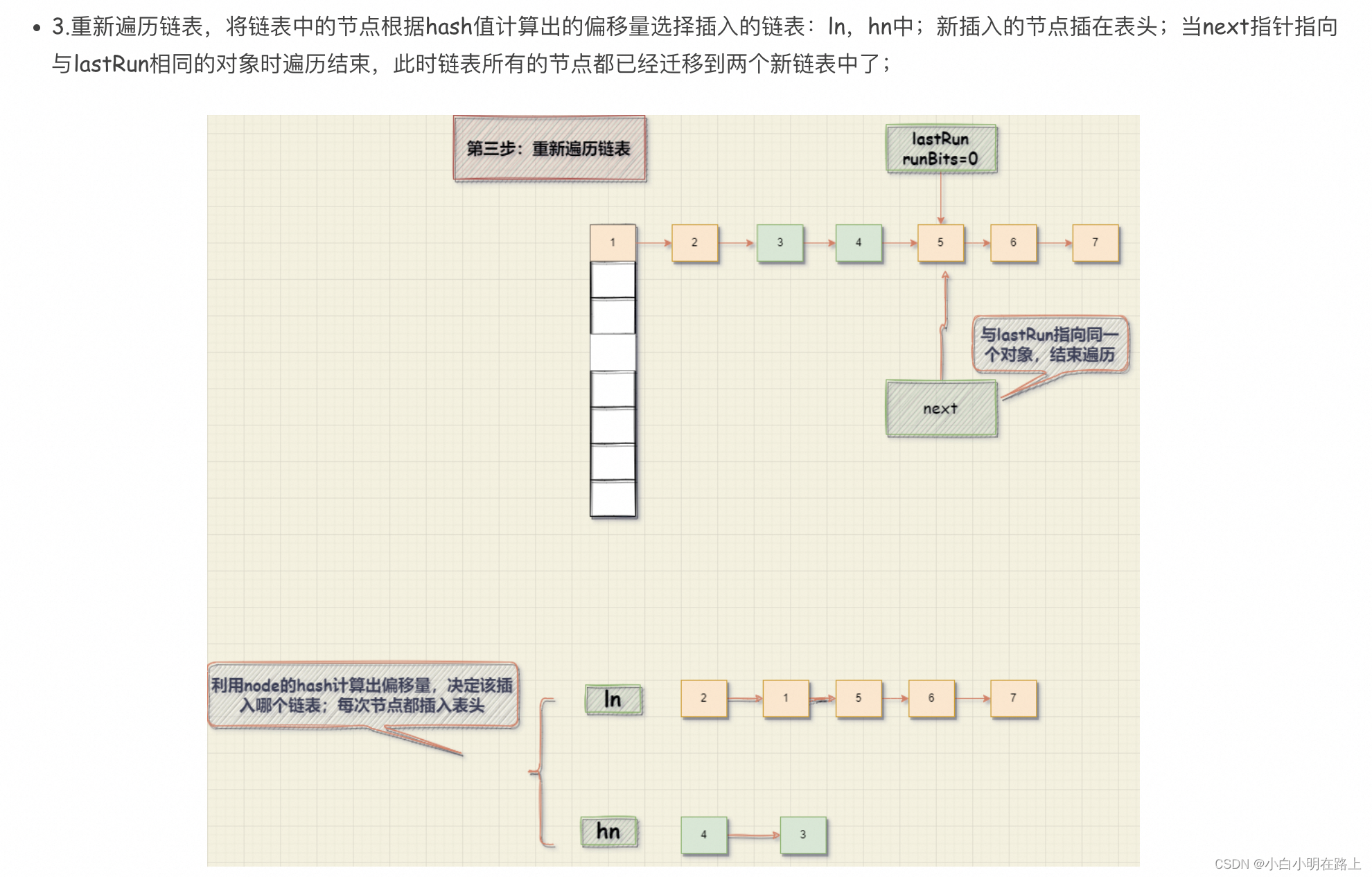
红黑树的迁移是直接循环遍历TreeNode链表,利用hash值计算偏移量来决定TreeNode应该放到哪个链表上;同时插入的位置是在表尾;因此可以看到源码中,一个链表由表头表尾共同维护;在遍历完整个TreeNode的节点之后,再判断TreeNode链表是否应该转换成红黑树,还是退化成Node链表
第三步:检查是否扩容完成
- 如果不是最后一个退出扩容的线程,就直接退出扩容;
- 如果是最后一个退出扩容的线程:i = n ,finishing = true 扫描全表,检查是否有没被迁移的数据,如果有就将其迁移到新数组检查完整个数组之后,将table更新为新数组:nextTab完成扩容然后退出
size
size 计算实际发生在 put,remove 改变集合元素的操作之中
没有竞争发生,向 baseCount 累加计数
有竞争发生(分而治之),新建 counterCells,向其中的一个 cell 累加计数
counterCells 初始有两个 cell
如果计数竞争比较激烈,会创建新的 cell 来累加计数,最后size会将所有cell相加
8.Iterator 和 ListIterator 有什么区别?
ListIterator有add()方法,可以向List中添加对象,而Iterator不能;
ListIterator有hasPrevious()和previous()方法,可以向前遍历,Iterator不能;
ListIterator可以定位当前的索引位置,nextIndex()和previousIndex()可以实现;
ListIterator可以实现对对象的修改,使用set()实现;而Iterator只能遍历,不能修改
8. Spring 创建 Bean 主要流程
1.2.1. 实例化 Bean
instanceWrapper = createBeanInstance(beanName, mbd, args); |
主要是通过反射调用默认构造函数创建 Bean 实例,此时 Bean 的属性都还是默认值 null。被注解 @Bean 标记的方法就是此阶段被调用的。
1.2.2. 填充 Bean 属性
populateBean(beanName, mbd, instanceWrapper); |
这一步主要是对 Bean 的依赖属性进行填充,对 @Value、@Autowired、@Resource 注解标注的属性注入对象引用。
1.2.3. 调用 Bean 初始化方法
exposedObject = initializeBean(beanName, exposedObject, mbd); |
调用配置指定中的 init 方法,例如,如果 xml 文件指定 Bean 的 init-method 方法或注解 @Bean(initMethod = "initMethod") 指定的方法。
9. Spring如何处理循环依赖
三级缓存
-
singletonObjects:一级缓存
主要存放的是已经完成实例化、属性填充和初始化所有步骤的单例 Bean 实例,这样的 Bean 能够直接提供给用户使用,我们称之为终态 Bean 或叫成熟 Bean。
-
earlySingletonObjects:二级缓存
主要存放的已经完成初始化,但属性还没自动赋值的 Bean,这些 Bean 还不能提供用户使用,只是用于提前暴露的 Bean 实例,我们把这样的 Bean 称之为临时 Bean 或早期的 Bean(半成品 Bean)。
-
singletonFactories:三级缓存
存放的是 ObjectFactory 的匿名内部类实例,调用 ObjectFactory.getObject() 最终会调用 getEarlyBeanReference 方法,该方法可以获取提前暴露的单例 Bean 引用。
一级缓存为单例池(singletonObjects),二级缓存为早期曝光对象 earlySingletonObjects,三级缓存为早期曝光对象工厂(singletonFactories)


https://www.cnblogs.com/larry1024/p/17775288.html#21-%E4%B8%89%E7%BA%A7%E7%BC%93%E5%AD%98
10.SpringBootApplication注解在内部是如何工作的
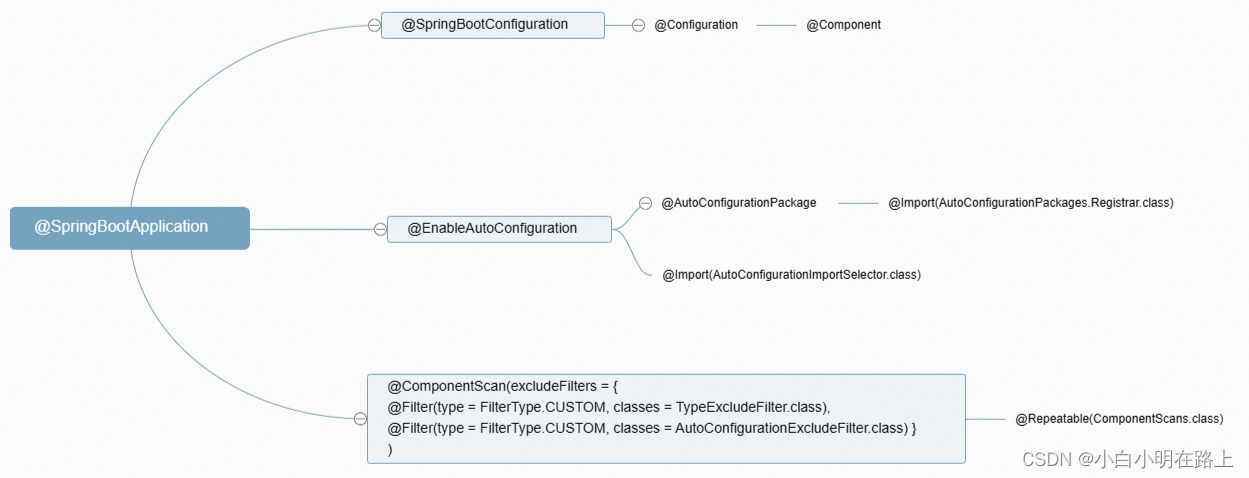
1. @SpringBootConfiguration
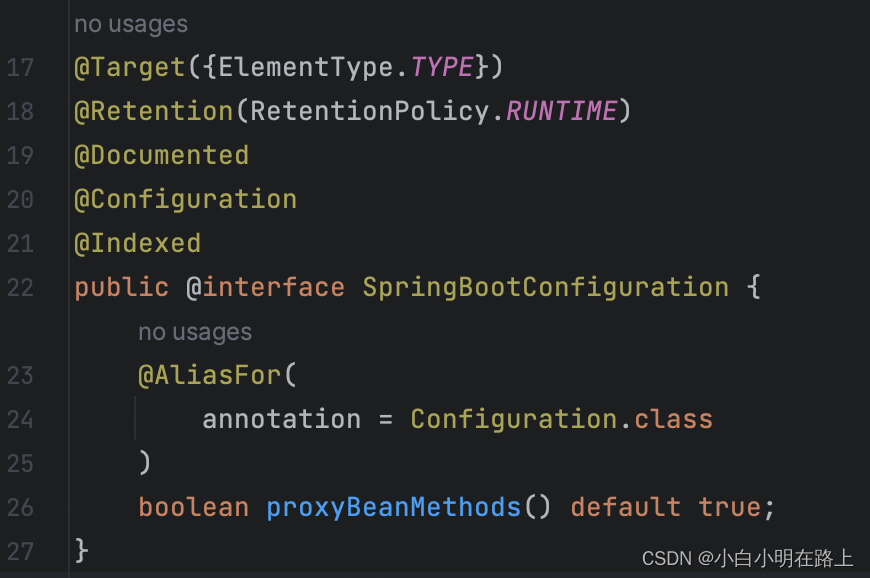
首先是@SpringBootConfiguration。这个注解往下点就能发现,除开元注解,它就是多了@Configuration。再往下也不过是@Component注解。
在@Configuration注解上,有注解@Component,这就代表容器也会创建配置类的对
boolean proxyBeanMethods() default true;默认值是true,说明这个类会被代理。(这里的代理是指用CGLIB代理)。看是直接从IOC容器中取得对象,还是不使用代理,每次都生成不一样的对象。
2. @EnableAutoConfiguration
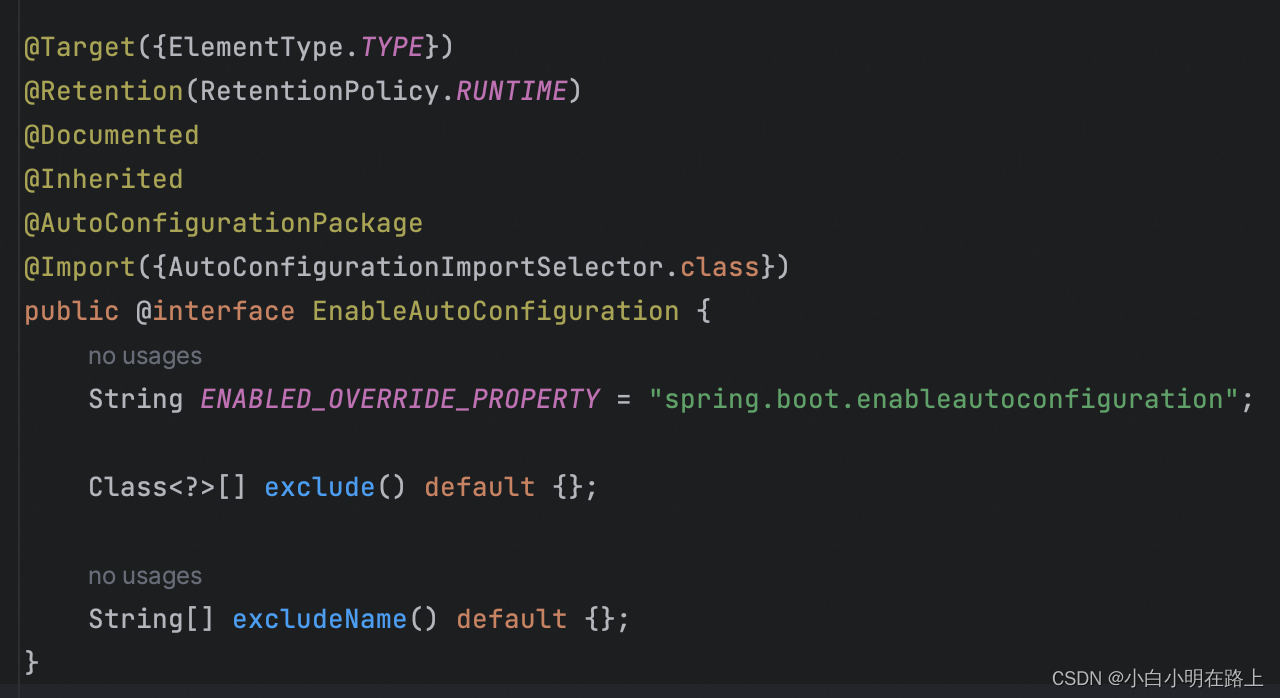
这个注解告诉SpringBoot开启自动配置功能,这样自动配置才能生效。借助@import注解,扫描并实例化满足条件的自动配置的bean,之后加载到IOC容器中(或者说借助@Import的支持,收集和注册特定场景相关的bean定义。)
帮助SpringBoot应用将所有符合条件的@Configuration配置都加载到当前SpringBoot,并创建对应配置类的Bean,并把该Bean实体交给IoC容器进行管理
@AutoConfigurationPackage自动配置包,这个注解的作用是将添加该注解的类所在的package,作为自动配置package进行管理
还有个注解@Import(AutoConfigurationImportSelector.class),这个注解最为重要是,使得SpringBoot应用将所有符合条件的@Configuration配置都加载到当前SpringBoot,创建并使用的IoC容器。
3. @ComponentScan
@ComponentScan是为了自动扫描并加载符合条件的组件(比如@Component和@Repository等)或者bean定义,最终将这些bean定义加载到IOC容器中去 。
11. java动态代理和cglib的区别
1.代理的对象不同
动态代理的实现方案有两种,JDK动态代理和CGLIB动态代理,区别在于JDK自带的动态代理,必须要有接口,而CGLIB动态代理有没有接口都可以
JDK动态代理:JDK原生的实现方式,需要被代理的目标类必须实现接口。因为这个技术要求代理对象和目标对象实现同样的接口(兄弟两个拜把子模式)。
cglib动态代理:通过继承被代理的目标类(认干爹模式)实现代理,所以不需要目标类实现接口。(CGLIB 通过动态生成一个需要被代理类的子类(即被代理类作为父类),该子类重写被代理类的所有不是 final 修饰的方法,并在子类中采用方法拦截的技术拦截父类所有的方法调用,进而织入横切逻辑。)
2.实现机制不同
JDK动态代理:使用java.lang.reflect.Proxy类和java.lang.reflect.InvocationHandler接口来创建代理对象,工作通过反射机制完成。
CGLIB动态代理:使用底层的字节码技术,通过Enhancer类和MethodInterceptor接口来创建代理对象,工作通过字节码增强技术完成
3. 性能差异
JDK动态代理:因为它基于反射机制,所以在调用代理方法时性能上不如CGLIB。
CGLIB动态代理:通常认为其性能要比JDK动态代理更好,因为它通过直接操作字节码生成新的类,避免了使用反射的开销。
4. 使用场景差异
JDK动态代理:适用于接口驱动的代理场景,在不涉及具体类,只关心接口定义时非常适用。
CGLIB动态代理:在需要代理没有实现接口的类,或者需要通过继承来提供增强功能的场景更适用。
5. 依赖差异
JDK动态代理:不需要添加任何额外依赖,因为它是基于JDK自带的API。
CGLIB动态代理:需要添加CGLIB库的依赖。
6. 可扩展性和复杂性
JDK动态代理:使用较为简单,只需要实现InvocationHandler接口。
CGLIB动态代理:提供了更多的控制,包括方法拦截、方法回调等,但相对来说使用起来更复杂。
7. 第三方框架支持
JDK动态代理和CGLIB动态代理都被广泛地应用在各种Java框架中,例如Spring。Spring可以根据情况选择使用JDK动态代理还是CGLIB动态代理。默认情况下,Spring会优先使用JDK动态代理,如果要代理的对象没有实现接口,则会使用CGLIB动态代理。
在实际使用中,选择哪种代理方式通常取决于具体的应用场景和需求。如果目标对象已经实现了接口,那么JDK动态代理是一个简单而有效的选择。如果目标对象没有实现接口或者有特定的继承结构要求,CGLIB可能是更好的选择
12. 反射机制
1. Java Reflection
(1)Reflection(反射)是被视为动态语言的关键,反射机制允许程序在执行期 借助于ReflectionAPI取得任何类的内部信息,并能直接操作任意对象的内 部属性及方法。
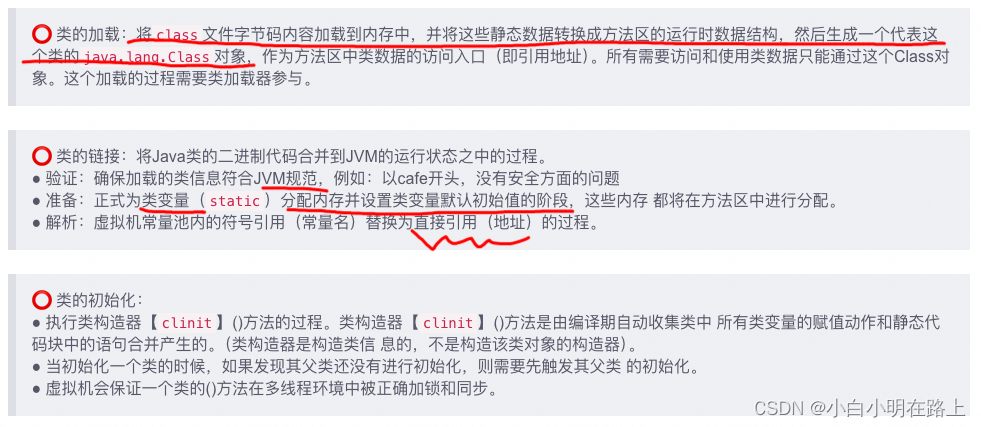
(2)加载完类之后,在堆内存的方法区中就产生了一个Class类型的对象(一个类只有一个Class对象),这个对象就包含了完整的类的结构信息。我们可以通过这个对象看到类的结构。这个对象就像一面镜子,透过这个镜子看到类的结构,所以,我们形象的称之为:反射。

2. 动态语言 vs 静态语言
(1)动态语言
是一类在运行时可以改变其结构的语言:例如新的函数、对象、甚至代码可以 被引进,已有的函数可以被删除或是其他结构上的变化。通俗点说就是在运行时代码可以根据某些条件改变自身结构。
主要动态语言:Object-C、C#、JavaScript、PHP、Python、Erlang。
(2)静态语言
与动态语言相对应的,运行时结构不可变的语言就是静态语言。如Java、C、C++。Java不是动态语言,但Java可以称之为“准动态语言”。即Java有一定的动态性,我们可以利用反射机制、字节码操作获得类似动态语言的特性。 Java的动态性让编程的时候更加灵活
3.Java反射机制研究及应用

类的加载过程

13.线程池
线程池(Thread Pool)是一种基于池化思想管理线程的工具,经常出现在多线程服务器中,如MySQL
线程过多会带来额外的开销,其中包括创建销毁线程的开销、调度线程的开销等等,同时也降低了计算机的整体性能。线程池维护多个线程,等待监督管理者分配可并发执行的任务。这种做法,一方面避免了处理任务时创建销毁线程开销的代价,另一方面避免了线程数量膨胀导致的过分调度问题,保证了对内核的充分利用。
核心参数
corePoolSize:线程池的核心线程数,线程池初始化创建的最小线程数量。
maximumPoolSize:最大线程数,当阻塞队列满了以后,还可以创建线程的最大数量。
keepAliveTime:空闲线程存活时间,核心线程之外创建的线程没有任务的时候不是立即销毁,超过等待时间之后才会被回收销毁。
unit:存活的时间单位,keepAliveTime的时间单位。
workQueue:阻塞队列,存放提交但未执行任务的队列。
threadFactory:创建线程的工厂类,用来创建线程执行器。
handler:饱和策略,当前线程超过线程池最大线程数后处理策略。
线程池执行流程

阻塞队列

拒绝策略

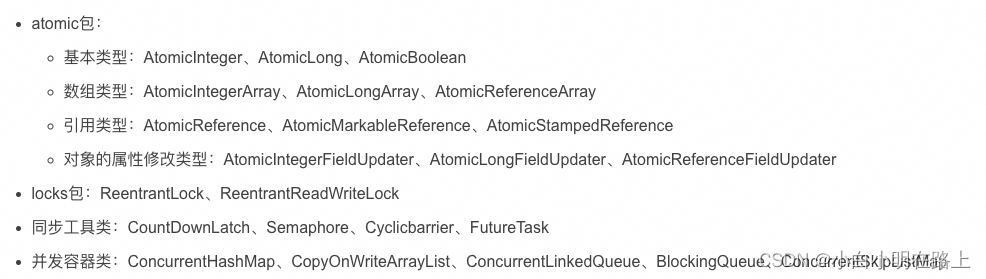
14.JUC
JUC是java.util.concurrent包的简称,在Java5.0添加,目的就是为了更好的支持高并发任务。让开发者进行多线程编程时减少竞争条件和死锁的问题! 我们在面试过程中也会经常问到这类问题
tools

Executor

Atomic















 27万+
27万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









