






一、RCNN
R-CNN:先要fine tuning一个预训练的网络,然后针对每个类别都训练一个SVM分类器,最后还要用regressors对bounding-box进行回归。
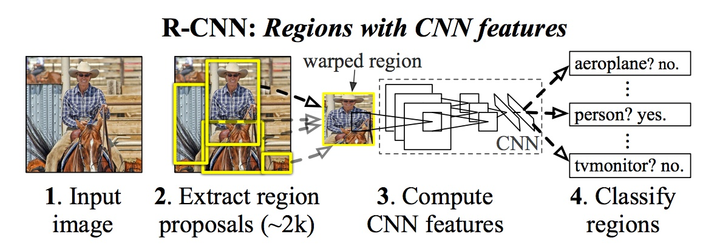
具体流程:
1、使用Selective Search得到若干候选区域;
2、 将每个候选区域缩放到一个固定的大小, 对每个候选区域分别用CNN进行特征提取;
3、使用SVM对输入进行分类;
4、对每个候选区域分别进行边框预测;
注:
slelective Search得到的候选区域并不一定和目标物体的真实边界相吻合,因此R-CNN提出对物体的边界框做进一步的调整:使用一个线性回归器来预测一个候选区域中物体的真实边界,该回归器的输入就是候选区域的特征,输出是边界框的坐标。
R-CNN存在以下几个问题:
1、训练分多步。 特征提取、图像分类、边框回归是三个独立的步骤,要分别进行训练,测试过程中的效率较低。
2、region proposal要单独用selective search的方式获得,步骤比较繁琐、耗时。
3、时间和内存消耗比较大。在训练SVM和回归的时候需要用网络提取的特征作为输入,特征保存在磁盘上再读入的时间消耗还是比较大的。对候选区域特征提取需要在单张图像上使用AlexNet 2000多次
4、推理耗时长。每张图片的每个region proposal都要做卷积,重复操作太多。
二、Fast-RCNN
先对输入图像使用一次CNN前向计算,得到整个图像的特征图,再在这个特征图中分别取提取各个候选区域的特征。
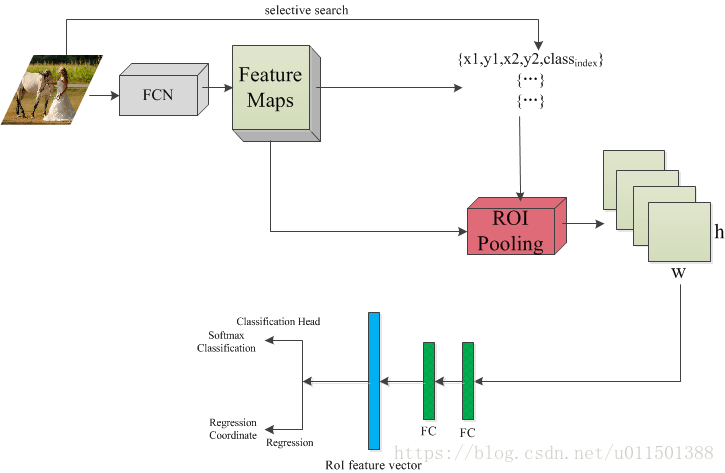
首先是读入一张图像,这里有两个分支,
1、一路送入卷积神经网络模型,输出 feature maps;
2、另一路通过selective search提取region proposals。提取的每个region proposal 都有一个对应的Ground-truth Bounding Box位置和Ground-truth class label。其中每个region proposals用四元数组进行定义,即(r, c, h, w),即窗口的左上行列坐标与高和宽。
3、将region proposals提出的原图像的坐标系映射到feature maps上,然后在相应位置做ROI Pooling,将计算结果通过两层4096的全连接层得到 ROI feature vector。
4、ROI feature vector分别经过一个分类器(21单元的全连接层)和一个回归器(84单元的全连接层),最后输出使用两个损失函数,分类的是softmaxWithLoss,输入是label和分类层输出的得分;回归使用的是SmoothL1Loss。
相比于R-CNN,减少了对SVM分类器的训练,也不需要额外的回归器,特征也不需要保存在磁盘上。
三、Faster-RCNN


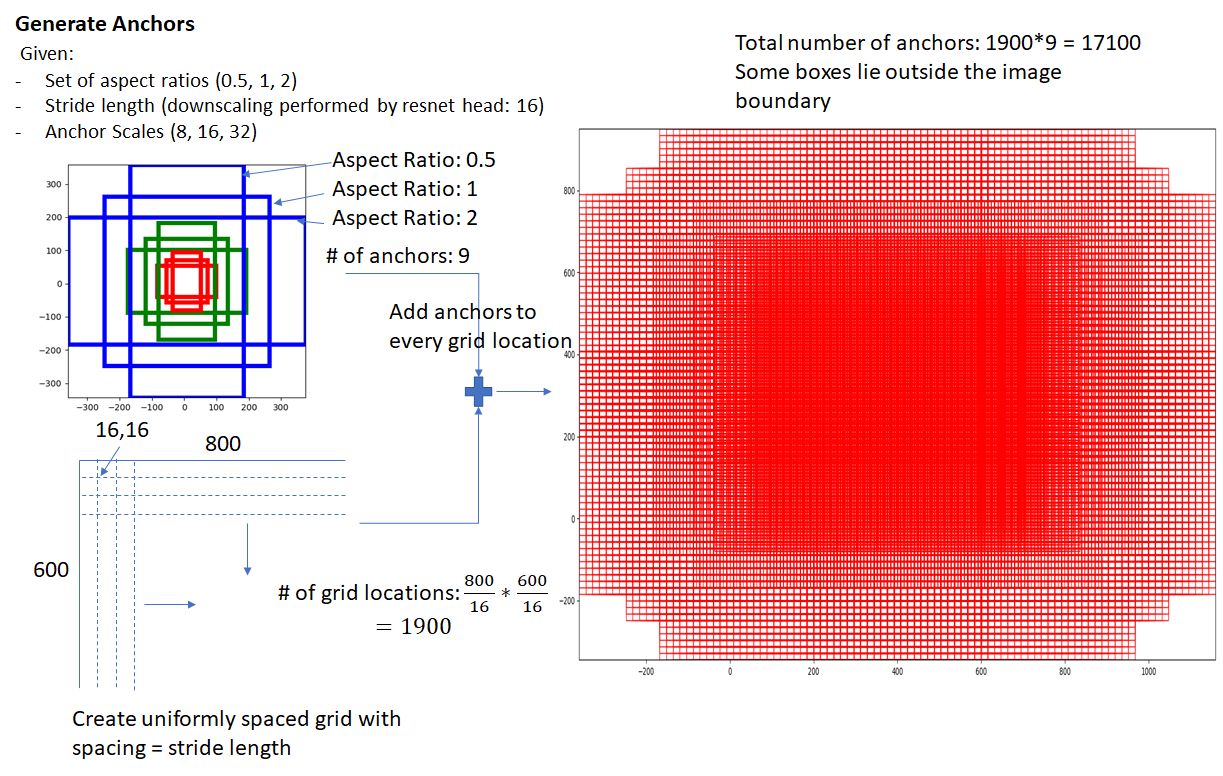
一、RPN部分
1、RPN Classification
RPN Classification的过程就是个二分类的过程。先要在feature map上均匀的划分出KxHxW个anchor区域,通过比较这些anchor和ground truth间的重叠情况来决定哪些anchor是前景,哪些是背景。
上半分支可以看到rpn_cls_score_reshape模块输出的结构是[1,9*H,W,2],就是9xHxW个anchor二分类为前景、背景的概率;anchor_target_layer模块输出的是每一个anchor标注的label,拿它和二分类概率一比较就能得出分类的loss。
RPN网络中利用anchors和softmax初步提取出positive anchors作为候选区域(另外也有实现用sigmoid代替softmax,输出[1, 1, 9xH, W]后接sigmoid进行positive/negative二分类,原理一样)。
2、RPN bounding box regression
RPN bounding box regression用于得出前景的大致位置,
前面的RPN classification给所有的anchor打上label后,我们需用一个表达式来建立anchor与ground truth的关系,假设anchor中心位置坐标是[Ax, Ay],长高为Aw和Ah,对应ground truth的4个值为[Gx,Gy,Gw,Gh],通过先平移后缩放的计算来模拟F变换

观察上面4个公式发现,需要学习的是这4个变换。注:当输入的anchor A与GT相差较小时,可以认为这种变换是一种线性变换, 那么就可以用线性回归来建模对窗口进行微调(注意,只有当anchors A和GT比较接近时,才能使用线性回归模型,否则就是复杂的非线性问题了)
线性回归就是给定输入的特征向量X, 学习一组参数W, 使得经过线性回归后的值跟真实值Y非常接近,

有了这4个偏移量(要注意这里是想对于proposal的,而不是相对于ground truth的)。完成训练后RPN就具备识别每一个anchor到与之对应的最优proposal偏移量的能力,换个角度看就是得到了所有proposal的位置和尺寸。
注:如果一个feature map中有多个ground truth,每个anchor只会选择和它重叠度最高的ground truth来计算偏移量。
3、RPN的loss计算

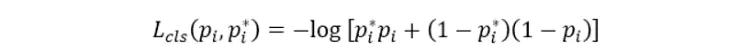
二、proposal layer 部分
得到proposal大致位置后下一步就是要做准确位置的回归了。Proposal Layer负责综合所有 变换量和positive anchors,计算出精准的proposal,送入后续RoI Pooling Layer。
在RPN的训练收敛后能得到anchor相对于proposal的偏移量,有了偏移量再根据公式1就能算出proposal的大致位置。在这个过程中HxWx9个anchor能算出HxWx9个proposal,大多数都是聚集在ground truth周围的候选框,这么多相近的proposal完全没必要反而增加了计算量,这时就要用一些方法来精选出最接近ground truth的proposal,三个步骤:
1、先选出前景概率最高的N个proposal;
2、做非极大值抑制(NMS)
3、NMS后再次选择前景概率最高的M个proposal;
经历这三个步骤后能够得到proposal的大致位置,但这还不够,为了得到更精确的坐标,你还要利用公式2再反推出这个大致的proposal和真实的ground truth间还有多少偏移量,对这个新的偏移量再来一次回归才是完成了精确的定位。















 7128
7128











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









