






概述
为了提高处理器执行指令的并行度,处理器将计算机指令处理过程拆分为多个阶段,并通过多个硬件处理单元,将不同指令处理的前后阶段重叠并行执行,形成流水线(pipeline)
处理器的流水线结构是处理器微架构最基本的要素,对处理器微架构的其他方面有重要影响。典型的MIPS处理器5级流水线包括取指、译码、执行、访存和写回
首先,在取指阶段,指令被从内存中读出。然后,在译码阶段得到指令需要的操作数寄存器索引,并通过索引从通用寄存器中将操作数读出
如果此时输入操作数和处理器功能单元可用,接下来便可将不同类型的指令分发到不同功能单元执行
- 例如,如果是算法指令,则分发到算术逻辑单元(Arithmetic Logical Unit, ALU)
- 如果是访存指令,则分发到加载存储单元,将数据从内存中读出,或者将数据写入内存
- 在写回阶段,指令执行的结果被写回通用寄存器
- 如果是计算指令,该结果来自执行阶段的计算结果
- 如果是内存读指令,该结果来自访存阶段从内存中读取的数据
在处理器流水线上执行的代码序列隐含指令之间的依赖关系,这种依赖关系使得指令流中的指令可能无法在指定的时钟周期执行,引发流水线冲突
为了检测流水线冲突引入的流水线互锁机制,由导致流水线停顿
可见,这种指令间的依赖关系是指令高效执行的主要障碍。为减少冲突,对于无法用旁路解决的数据冲突,一种解决办法是通过处理器的分发逻辑,在运行时由处理器对指令动态重新排序。这意味着必须增加分发逻辑的重排序缓存,以便其能处理更多的指令,并将指令乱序地分发到处理器的功能单元,这称为乱序执行,简称OOO(Out-Of-Order)
这种方法会显著提高硬件复杂度,增加芯片面积和功耗。另一种消除数据冲突,提高指令级并行度(Instruction Level Parallelism , ILP) 的方法是通过在编译阶段,令编译器对指令重排序,并利用流水线停顿造成的空闲时钟周期执行其他指令
编译器重新排列后的指令流馈送到顺序多发射处理器执行。编译器对指令重排序的过程为静态指令调度或编译时指令调度,这是编译器后端优化中的一个重要阶段
指令调度可在基本块内或者跨基本块重拍指令,即将指令从其原先所在基本块(即源基本块)向另一个基本块(即目标基本块)移动
源基本块和目标基本块可以是同一个基本块,也可以是不同的基本块
如果指令能在其所在同一个基本块内移动,则称为局部调度。如果指令可在不同基本块移动,则称为全局调度
指令调度可以在寄存器分配之前和/或之后执行。寄存器分配前的指令的调度有更大的自由度,而寄存器分配后的指令调度优点在于,此时指令序列中已经包含寄存器溢出相关指令,编译器处理的指令序列相对更完整,因此可以充分利用处理器资源,得到更有效的指令调度结果
指令调度基本原理
假设有如下计算
e = (a + b) + c * d
根据AST 生成 汇编指令如下
load r1, a
load r2, b
add r3, r1, r2
load r4, c
load r5, d
mul r6, r4, r5
add r7, r3, r6
store e, r7
基于处理器资源特性模型,编译器可以建立对上述各条指令延迟的估计
假设load、store操作需要4个时钟周期,mul操作需要3个时钟周期,add操作需要1个时钟周期。注意,此处在估计内存操作指令延迟(如load、store)时,假设不会出现缓存未命中
一旦出现缓存未命中,内存操作指令的延迟将可能达到数百个时钟周期。另外,为了简化概念,此处还假设,如果指令间没有依赖关系,单发射处理器可以在每个时钟周期发射一条指令
显然,上述汇编指令序列不是最优的指令序列。因为指令 “add r3, r1, r2” 需要等待之前的两个load指令完成变量a和b的加载后才能开始计算,这中间的停顿时间完全可以用来执行其他没有依赖关系的指令,如后继的"load r4, c" 和 “load r5, d” 指令
经过如此改进的指令序列无疑可以提高指令级并行度,但是通过寄存器活跃性(liveness) 分析可知,改进后的指令序列在执行"load r5, d" 指令时需要的物理寄存器最大数量将达到4个,大于改进前指令序列的最大物理寄存器需求量(3个)
因此,指令调度提高指令并行度是以增加寄存器压力为代价的。编译器如何在二者之间保持平衡取决于后端硬件架构
具体到GPU 后端,因为有更多物理寄存器,GPU编译器可以承受更大的寄存器压力以换取更高的指令并行度,即更快的执行速度
编译器对指令重排序时,应保证不改变已存在数据依赖关系指令间的执行顺序。 为此,编译器首先需要建立指令序列对应的数据依赖图(Data Dependence Graph, DDG), 这是调度算法的重要工具
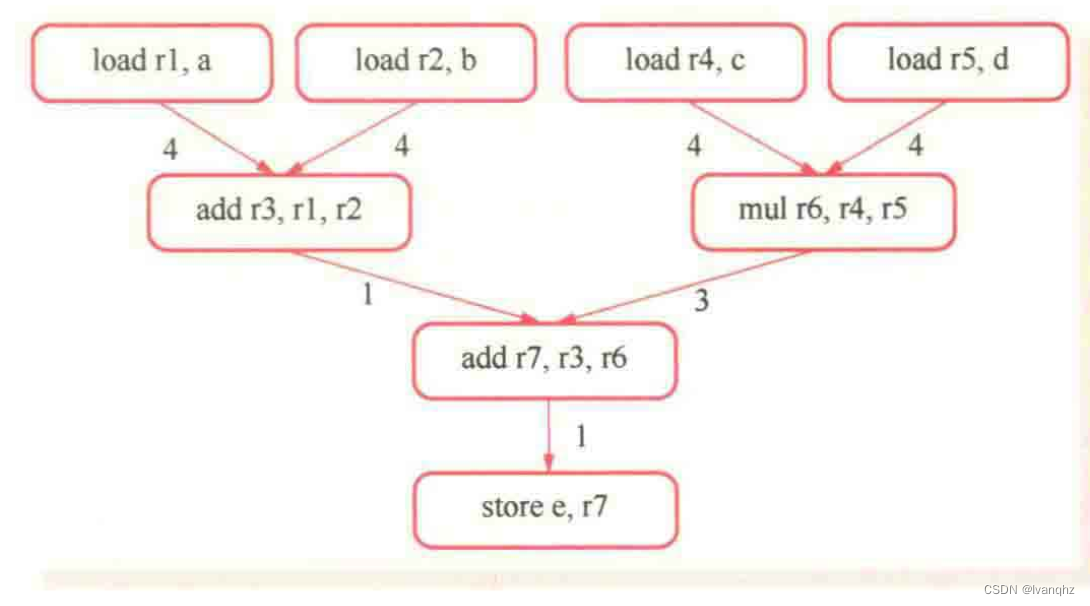
例如,数据依赖图图表示为G={N,E},其中的节点集合N表示基本块的所有指令,有向边集合E表示指令之间的数据依赖约束,E中的每条边有一个表示延时的权重。该例对应的数据依赖图如下图
数据依赖图的任何一种拓扑排序方法都可以形成有效的指令调度,最简单且常见的方法是列表调度(list scheduling)。其实现方法是跟踪记录依赖图的就绪列表,并将就绪列表中的一条指令添加到指令调度表
例如,在上述数据依赖图所示,所有load指令在初始状态下已经准备执行就绪,此时,所有load指令都在就绪列表中
调度算法以何种方式选择调度的指令尤其重要,最典型的是关键路径优先调度算法. 关键路径是数据依赖图中节点的最长的路径。如上图的数据依赖图,最长关键路径是8个时钟周期,包括从指令"load r5, d"(或“load r4 c”) 、“mul r6, r4, r5” 到 “store e, r7” 在内的4个节点
这条路径上的延迟总和最大,因此,选择这条路径上的第一个节点"load r5, d" (或 “load r4 c”) 作为调度的第一条指令。依次类推,可以得到指令调度结果如下:
load r5, d
load r4, c
load r2, b
load r1, a
mul r6, r4, r5
add r3, r1, r2
add r7, r3, r6
store e, r7
上述调度算法从就绪列表中选择指令的标准的最小化关键路径上的指令序列执行时间,减少流水线停顿的发生频率。在实际实现中,可以增加其他优先级策略,如寄存器压力
随着就绪列表中的指令不断被调度,数据依赖图中的其他节点相继被加入就绪列表,并重复上述过程,直到所有节点都被调度,数据依赖图为空,调度过程结束
上述调度算法只考虑一个基本块内的指令重排序,因而属于局部指令调度。全局指令调度可以在基本块间重排指令,需要考虑的情况更为复杂,因而考虑的情况更为复杂,因而大部分编译器只实现局部指令调度,如LLVM















 69
69

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









