







 本文介绍了如何利用Python的BeautifulSoup库解析网页,抓取猫眼电影排行榜上的电影信息,包括电影排名、名称、主演、上映时间和评分。通过设置headers模拟浏览器请求,获取网页数据,然后解析特定的HTML标签,提取所需字段。
本文介绍了如何利用Python的BeautifulSoup库解析网页,抓取猫眼电影排行榜上的电影信息,包括电影排名、名称、主演、上映时间和评分。通过设置headers模拟浏览器请求,获取网页数据,然后解析特定的HTML标签,提取所需字段。
关于基本Beautiful Soup 的基本使用方法在前面都已经有介绍过了,Beautiful Soup 的点比较多,在项目中是如何使用Beautiful Soup 对抓取到的网页进行分析,并提取关键的字段,这篇文章的目的就在此。
分析页面
经常看电影的同学都会关注电影的排行榜,在对电影的分析前,先得得到电影的数据。有很多的网站提供了对电影的排名,猫眼也有提供如下的数据:
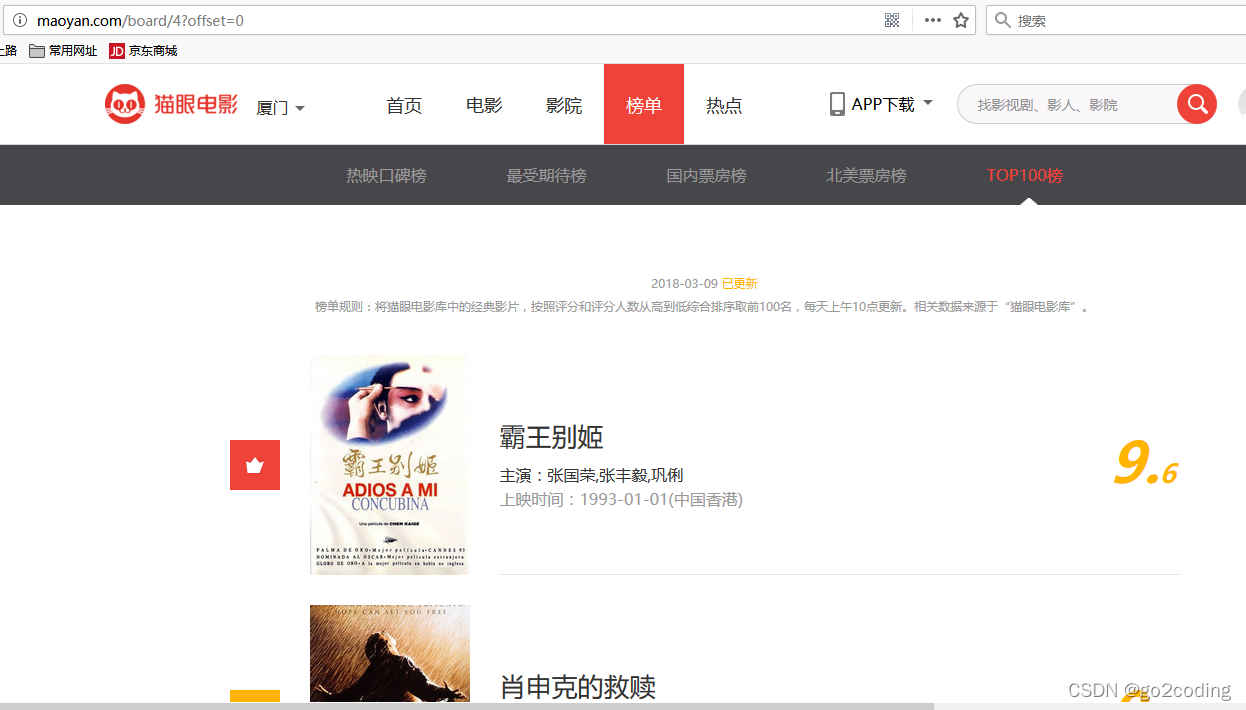
先使用 requests 获取网页数据:
url = "http://maoyan.com/board/4?offset=0"
headers = {}
headers['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0'
headers['Accept-Encoding'] = 'gzip, deflate'
headers['Content-Type'] = 'text/html; charset=utf-8'
maoyan_response = requests.get(url,headers=headers)
关于headers是如何选取的,简单的方式是使用浏览器的调试,打开浏览器的web开发工具选择网络,重新刷下网站,找到http://maoyan.com/board/4?offset=0 的地址,查看网站的请求头。
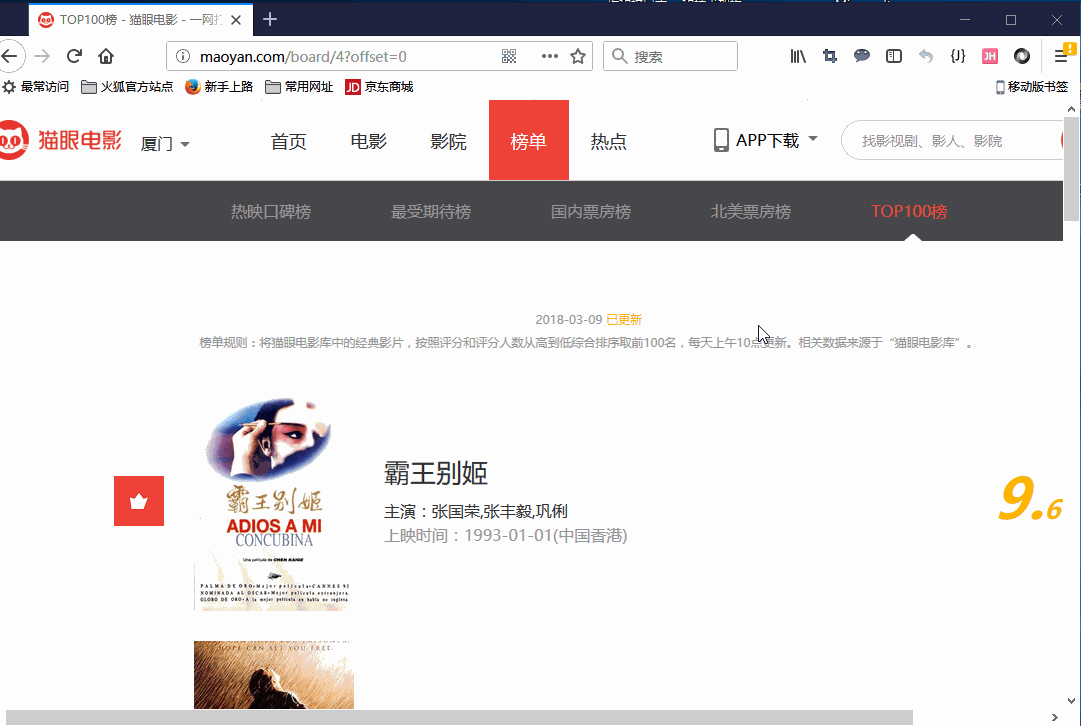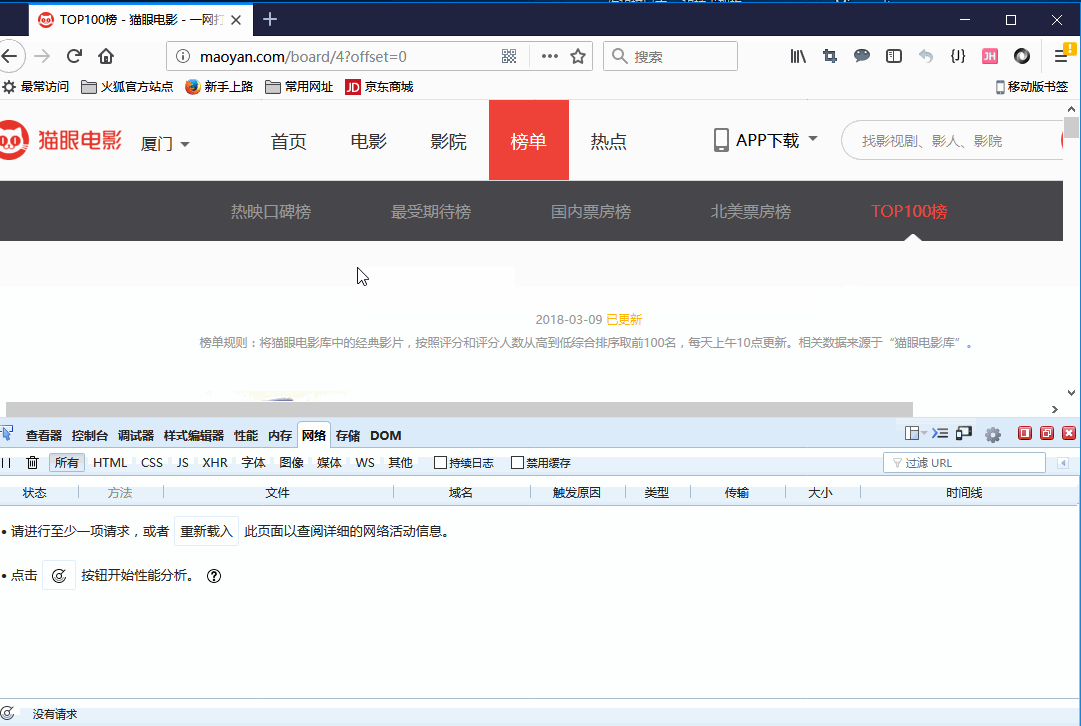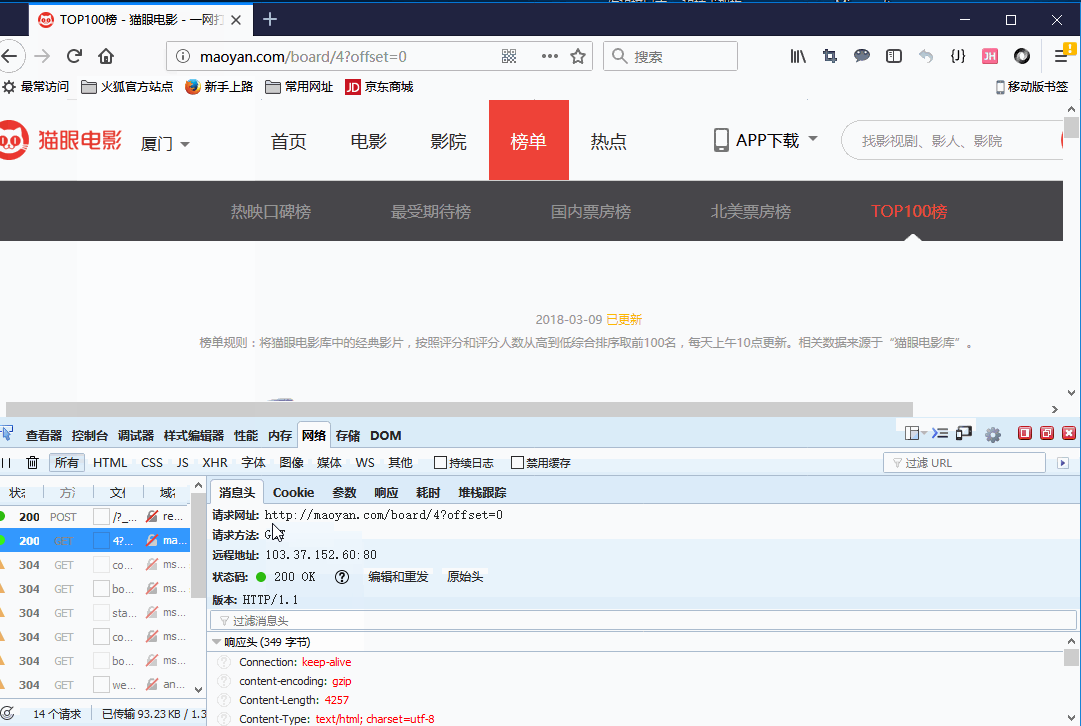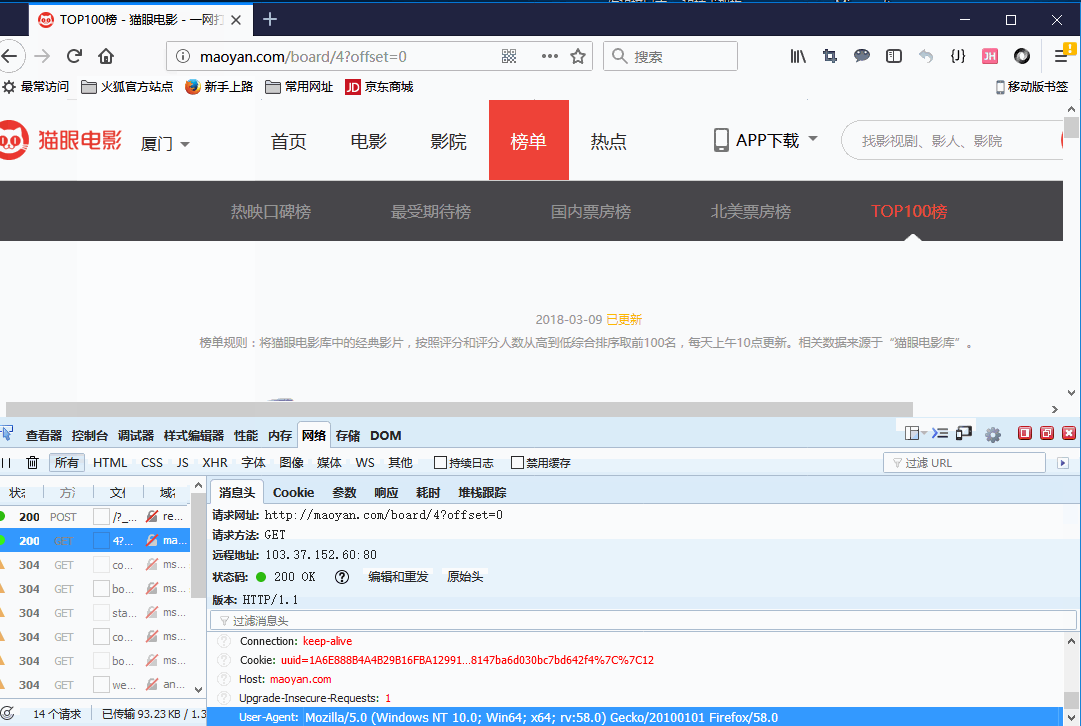
假设我的项目中需要获取到电影的排名,电影的名字,电影的主演,电影的上映时间,电影的评分。

使用浏览器自带的工具对网页进行分析,从页面来开,每一页中有10部电影,通常我们需要找到这10部电影的一个中标签,这个标签中包含着这10电影的代码。
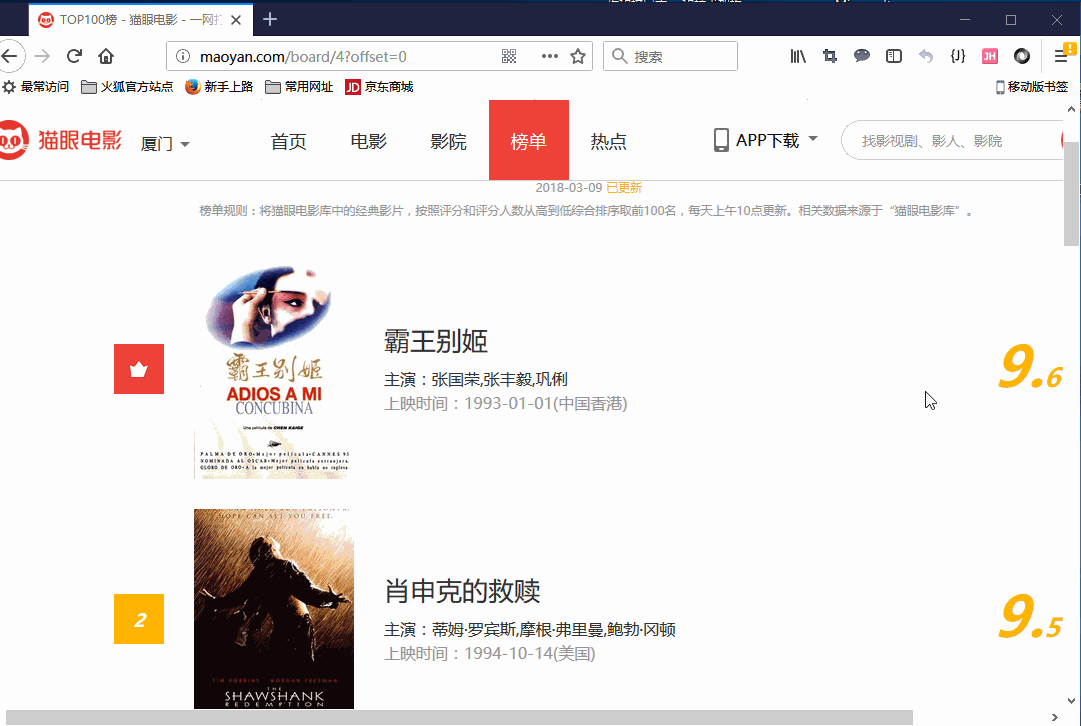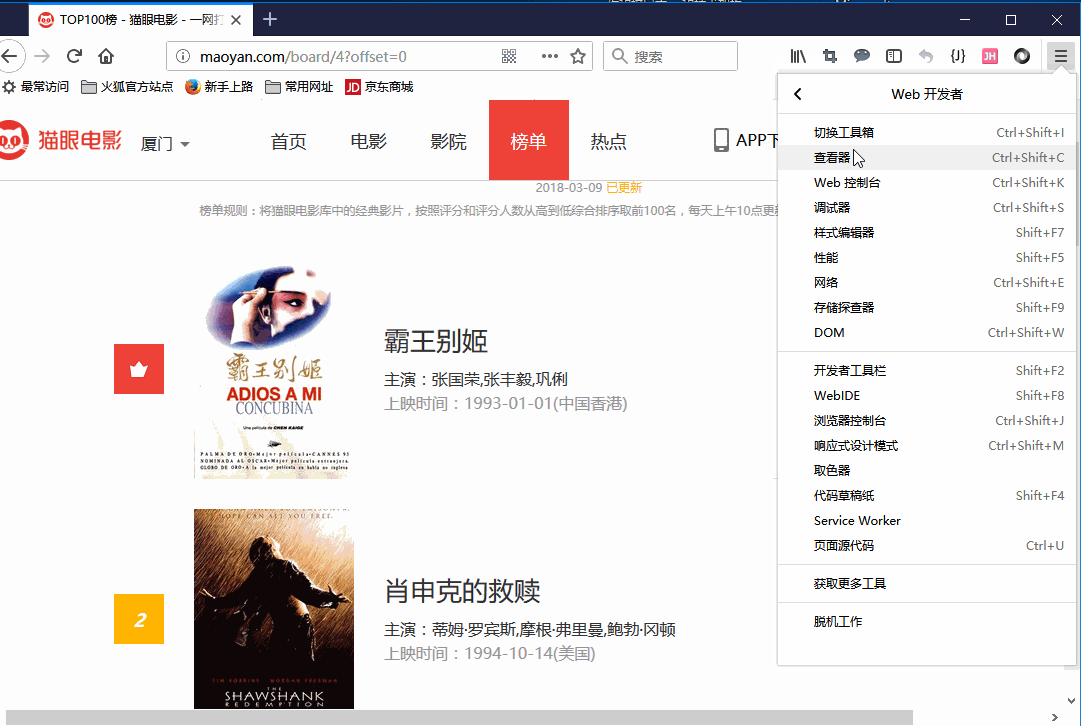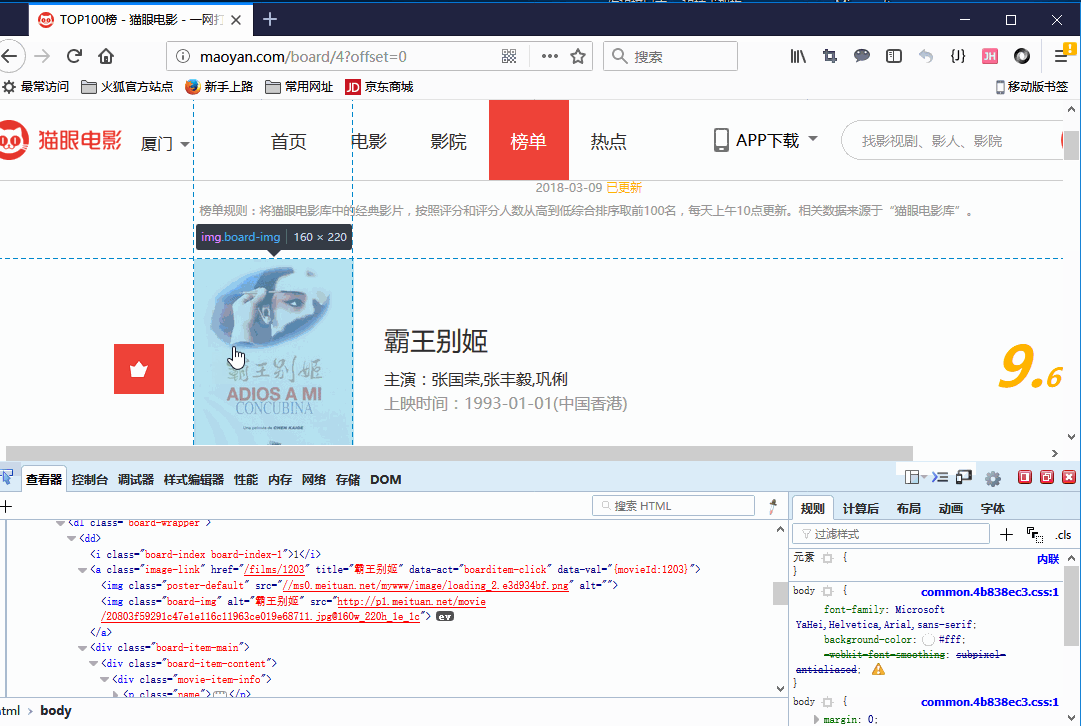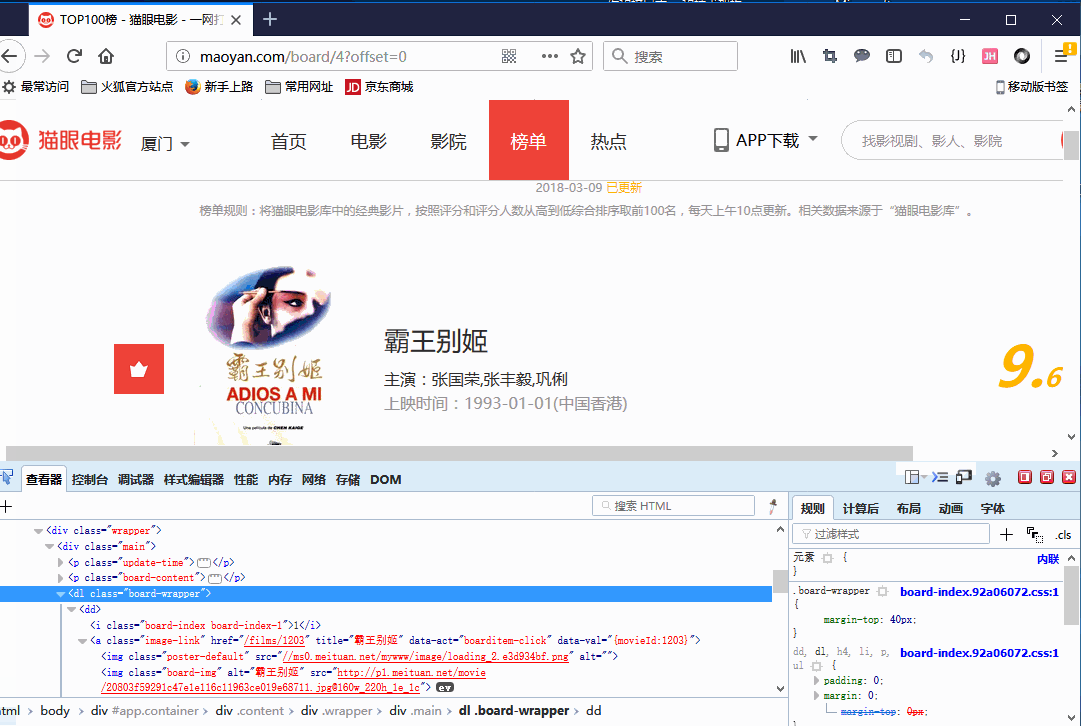
好,我们找到了<dl class="board-wrapper">
使用Beautiful Soup 进行抓取,
pinyin_soup = BeautifulSoup(maoyan_response.text, "lxml")
board_wrapper_tag = pinyin_soup.find('dl',{'class':'board-wrapper'})
dl中包含了10个的dd,每个dd里面包含着每一部电影的各种信息,解析dd就能解析出我们需要的属性。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QOx3Dujc-1649318200034)(/images/kuxue/blog/movie_tags.png)]
board_dd_tags = board_wrapper_tag.select('dd')
for board_dd_tag in board_dd_tags:
print board_dd_tag.find('i',{'class':re.compile('board-index*')}).text.strip()
print board_dd_tag.find('p', {'class': 'name'}).find('a').text.strip()
print board_dd_tag.find('p', {'class': 'star'}).text.strip()
print board_dd_tag.find('p', {'class': 'releasetime'}).text.strip()
print board_dd_tag.find('p', {'class': 'score'}).text.strip()
通过dd里的属性,解析出电影的排名,电影的名字,电影的主演,电影的上映时间,电影的评分。
完整的参考代码如下
#!/usr/bin/python
#coding=utf-8
import requests
from bs4 import BeautifulSoup
import re
for i in range(0,10):
url = "http://maoyan.com/board/4?offset=%d"%(i*10)
headers = {}
headers['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0'
headers['Accept-Encoding'] = 'gzip, deflate'
headers['Content-Type'] = 'text/html; charset=utf-8'
maoyan_response = requests.get(url,headers=headers)
if maoyan_response.status_code == 200:
pinyin_soup = BeautifulSoup(maoyan_response.text, "lxml")
board_wrapper_tag = pinyin_soup.find('dl',{'class':'board-wrapper'})
if board_wrapper_tag is not None:
board_dd_tags = board_wrapper_tag.select('dd')
for board_dd_tag in board_dd_tags:
print board_dd_tag.find('i',{'class':re.compile('board-index*')}).text.strip()
print board_dd_tag.find('p', {'class': 'name'}).find('a').text.strip()
print board_dd_tag.find('p', {'class': 'star'}).text.strip()
print board_dd_tag.find('p', {'class': 'releasetime'}).text.strip()
print board_dd_tag.find('p', {'class': 'score'}).text.strip()
print
输出结果为:
1
霸王别姬
主演:张国荣,张丰毅,巩俐
上映时间:1993-01-01(中国香港)
9.6
2
肖申克的救赎
主演:蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿
上映时间:1994-10-14(美国)
9.5
…
我们默认了总的页数为10页,每一页是通过offset=进行跳转,BeautifulSoup 中在查找属性是用的比较多的是find和find_all,select 也和find_all有同样的用法,但是在查找的时候find和find_all配合起来,方便很多。


















 1819
1819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











