







之前就一直想学习asyncio,然后就去网上查,发现讲的花里胡哨而且异常难懂,就放弃了一段时间,今天来重新学习一下,发现了一个大佬的文章,根据例子来理解就容易多了,文章最后放上大佬的连接。
传统的单线程下载处理网页可能就像下图(来源)左边蓝色那样, 计算机执行一些代码, 然后等待下载网页, 下好以后, 再执行一些代码… 或者在等待的时候, 用另外一个线程执行其他的代码, 这是多线程的手段. 那么 asyncio 就像右边, 只使用一个线程, 但是将这些等待时间统统掐掉, 下载应该都调到了后台, 这个时间里, 执行其他异步的功能, 下载好了之后, 再调回来接着往下执行.
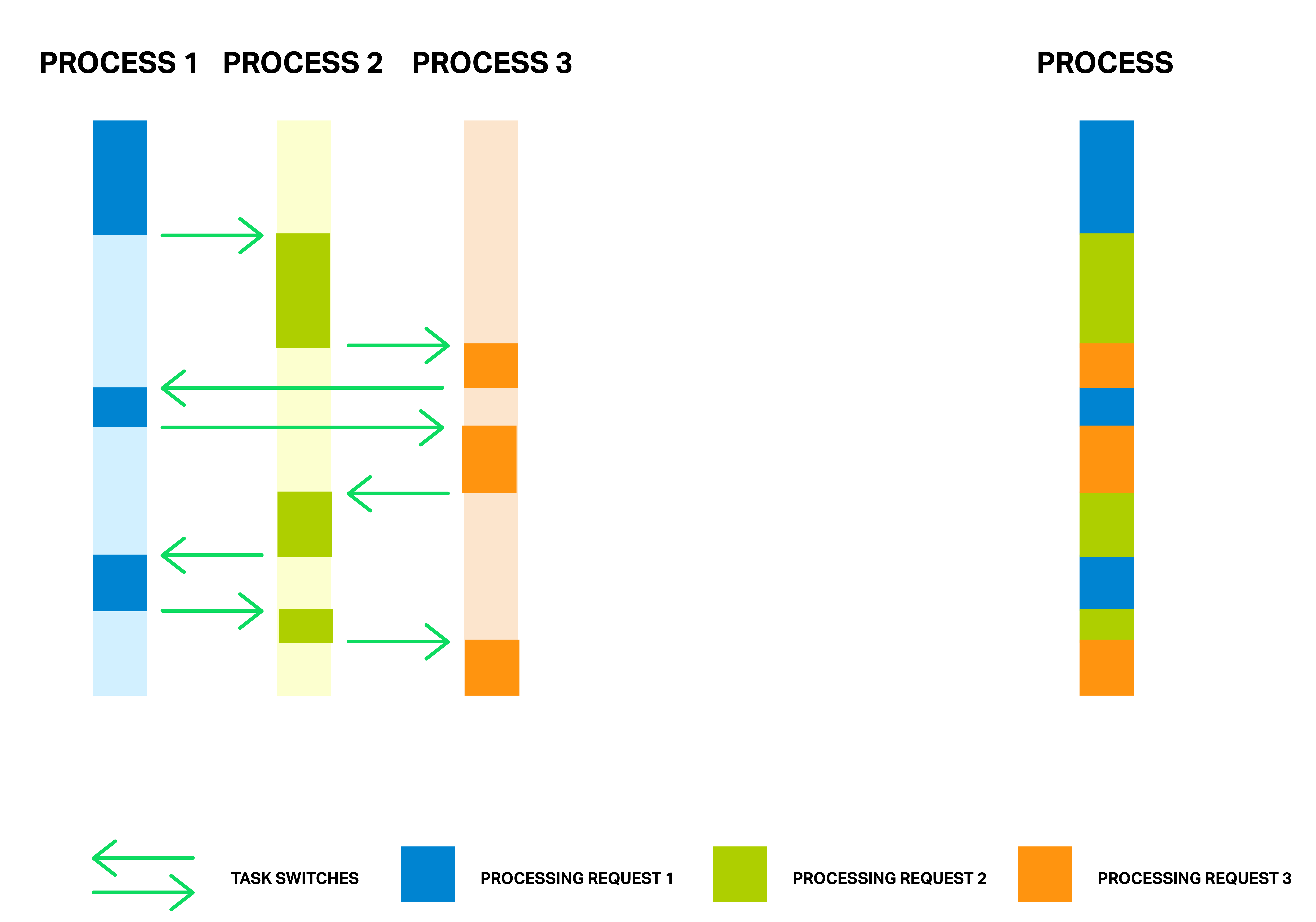
如果换一张 Python 自家解释 asyncio 的图(来源), 虽然稍微复杂一点, 但是就是和上图想要表达的是一个意思.

Asyncio 库 ¶
Asyncio 库是 Python 的原装库, 但是是在 Python 3 的时候提出来的, Python 2 和 Python 3.3- 是没有的. 而且 Python 3.5 之后, 和 Python 3.4 前在语法上还是有些不同, 比如 “await” 和 “yield” 的使用, 下面的教程都是基于 Python 3.5+, 使用 Python3.4 的可能会执行有点问题. 调整一下就好.
在 3.5+ 版本中, asyncio 有两样语法非常重要, async, await. 弄懂了它们是如何协同工作的, 我们就完全能发挥出这个库的功能了. 剧透一下, 等会使用单线程爬网页的 asyncio 和之前多进程写的爬网页效果差不多, 而且当并行的进程数少的时候, asyncio 效果还会比多进程快.
基本用
对比:
(1) 普通操作
import time
def job(t):
print("开始工作",t)
time.sleep(t)
print("任务",t,'花费',t,'s')
def main():
[job(t) for t in range(1,3)]
t1 = time.time()
main()
print("没有异步加载花费的时间:",time.time()-t1)这个花费时间就是3秒了
(2)使用异步
import asyncio
import time
async def job(t):
print("开始工作",t)
await asyncio.sleep(t)
print("任务",t,'花费',t,'s')
async def main(loop):
tasks = [loop.create_task(job(t)) for t in range(1,3)]
await asyncio.wait(tasks)
t1=time.time()
loop = asyncio.get_event_loop()
loop.run_until_complete(main(loop))
loop.close()
print("异步总共花费",time.time()-t1)
花费的时间只有2s,只是因为异步操作的时候在任务一执行等待时间的的时候直接进行第二个任务了,所有总共花费了2s,也就是任务执行时间最长的时间
实际操作爬虫:
在爬虫的过程中使用的是aiohttp的异步请求包,
import asyncio
import aiohttp
import time
async def get_html(sess,url):
html = await sess.get(url)
r = await html.text()
return r
async def main(loop):
num = 1
async with aiohttp.ClientSession() as sess:
tasks=[]
for i in range(1,3):
url = 'http://lab.scrapyd.cn/page/{url}/'
url = url.format(url=str(i))
tasks.append(loop.create_task(get_html(sess,url)))
finished,unfinised = await asyncio.wait(tasks)
num=0
for i in finished:
with open(str(num)+".txt",'w') as f:
f.write(i.result())
num+=1
if __name__ == '__main__':
t1 = time.time()
loop = asyncio.get_event_loop()
loop.run_until_complete(main(loop))
print("花费时间",time.time()-t1)
本篇博客是基于莫烦大佬的文章 https://morvanzhou.github.io/tutorials/data-manipulation/scraping/4-02-asyncio/















 599
599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









