






Mysql主从复制及读写分离
主从复制
什么是主从复制
主从复制,是用来建立一个和主数据库完全一样的数据库环境,称为从数据库;主数据库一般是准实时的业务数据库。
主从复制的作用
1、做数据的热备,作为后备数据库,主数据库服务器故障后,可切换到从数据库继续工作,避免数据丢失。
2、架构的扩展。业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个机器的I/O性能。
3、读写分离,使数据库能支撑更大的并发。在报表中尤其重要。由于部分报表sql语句非常的慢,导致锁表,影响前台服务。如果前台使用master,报表使用slave,那么报表sql将不会造成前台锁,保证了前台速度。
主从复制原理
1.数据库有个bin-log二进制文件,记录了所有sql语句。
2.我们的目标就是把主数据库的bin-log文件的sql语句复制过来。
3.让其在从数据的relay-log重做日志文件中再执行一次这些sql语句即可。
4.下面的主从配置就是围绕这个原理配置
5.具体需要三个线程来操作:
- 1.binlog输出线程:每当有从库连接到主库的时候,主库都会创建一个线程然后发送binlog内容到从库。对于每一个即将发送给从库的sql事件,binlog输出线程会将其锁住。一旦该事件被线程读取完之后,该锁会被释放,即使在该事件完全发送到从库的时候,该锁也会被释放。在从库里,当复制开始的时候,从库就会创建两个线程进行处理:
- 2.从库I/O线程:当START SLAVE语句在从库开始执行之后,从库创建一个I/O线程,该线程连接到主库并请求主库发送binlog里面的更新记录到从库上。从库I/O线程读取主库的binlog输出线程发送的更新并拷贝这些更新到本地文件,其中包括relay log文件。
- 3.从库的SQL线程:从库创建一个SQL线程,这个线程读取从库I/O线程写到relay log的更新事件并执行。
可以知道,对于每一个主从复制的连接,都有三个线程。拥有多个从库的主库为每一个连接到主库的从库创建一个binlog输出线程,每一个从库都有它自己的I/O线程和SQL线程。
从库通过创建两个独立的线程,使得在进行复制时,从库的读和写进行了分离。因此,即使负责执行的线程运行较慢,负责读取更新语句的线程并不会因此变得缓慢。比如说,如果从库有一段时间没运行了,当它在此启动的时候,尽管它的SQL线程执行比较慢,它的I/O线程可以快速地从主库里读取所有的binlog内容。这样一来,即使从库在SQL线程执行完所有读取到的语句前停止运行了,I/O线程也至少完全读取了所有的内容,并将其安全地备份在从库本地的relay log,随时准备在从库下一次启动的时候执行语句。【从库生成两个线程,一个I/O线程,一个SQL线程;i/o线程去请求主库 的binlog,并将得到的binlog日志写到relay log(中继日志) 文件中;主库会生成一个 log dump 线程,用来给从库 i/o线程传binlog;SQL 线程,会读取relay log文件中的日志,并解析成具体操作,来实现主从的操作一致,而最终数据一致;】
可以知道,对于每一个主从复制的连接,都有三个线程。拥有多个从库的主库为每一个连接到主库的从库创建一个binlog输出线程,每一个从库都有它自己的I/O线程和SQL线程。
主从复制如图:

原理图2

步骤一:主库db的更新事件(update、insert、delete)被写到binlog
步骤二:从库发起连接,连接到主库
步骤三:此时主库创建一个binlog dump thread线程,把binlog的内容发送到从库
步骤四:从库启动之后,创建一个I/O线程,读取主库传过来的binlog内容并写入到relay log.
步骤五:还会创建一个SQL线程,从relay log里面读取内容,从Exec_Master_Log_Pos位置开始执行读取到的更新事件,将更新内容写入到slave的db.
主从复制搭建步骤 :
1.linux安装mysql,使用yum指令安装:yum install mysql-server 准备两台机器分别安装mysql数据库
2.安装完成启动mysql服务:service mysqld start
3.指定mysql数据库密码:/usr/bin/mysqladmin -u root password 'root'
4.测试:mysql -uroot -proot
5.默认装完mysql不允许远程访问[使用root开启远程访问]步骤如下:
-
select user,host,password from user;
-
删除没有密码的用户:delete from user where password=’’;

-
修改端口:允许所有端口进行访问:update user set host='%';

-
提交commit;
-
刷新mysql权限:flush privileges;

-
navicat连接成功:
6.两台搭建成功之后测试两台机器能否相互连接:[标识连接成功]
[一台机器连接另一台mysql] mysql -u root -p -h 192.168.87.130 -P 3306
[另一台机器连接本机的mysql] mysql -u root -p -h 192.168.87.129 -P 3306
7.开始搭建[开始位置]修改mysql的配置文件:vim /etc/my.cnf [下面是添加配置文件的内容]
server-id=1 [多台机器的id名字不能相同]
log-bin=mysql-bin
log-slave-updates
slave-skip-errors=all

8.修改完成重新启动mysql服务指令:service mysqld restart
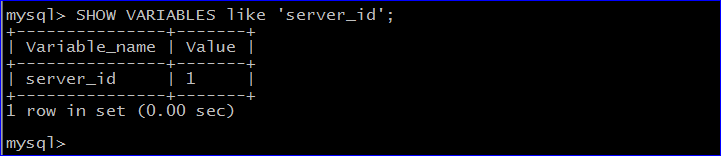
9.登陆mysql:mysql -uroot -proot 检测配置是否生效:SHOW VARIABLES like 'server_id';[结束位置]
10.以上的步骤在另一台机器[mysql从库]做相同的配置.[开始位置]--[结束位置]
11.查看主节点[主库]的状态信息,文件名称:show master status;
12.在从机上执行指令stop slave; 将如下配置修改后在从机的mysql客户端执行
将如下配置修改后在从机的mysql客户端执行
change master to
master_host='192.168.64.132',
master_user='root',
master_password='root',
master_log_file='mysql-bin.000001',
master_log_pos=106;
13.在从节点[从库]开启复制功能指令:start slave;
14.在从机上查看从节点[从库]状态:show slave status\G; 表示搭建成功
15.测试连接两台服务器: [搭建成功]
-
在主库中创建数据库ems,刷新从库出现ems数据库

-
在主库中的表添加数据,从库刷新会同步主库的数据

搭建主从复制问题解决方案参考:
https://blog.csdn.net/anljf/article/details/6822980读写分离
使用场景
类似淘宝网这样的网站,海量数据的存储和访问成为了系统设计的瓶颈问题,日益增长的业务数据,无疑对数据库造成了相当大的负载,同时对于系统的稳定性和扩展性提出很高的要求。随着时间和业务的发展,数据库中的表会越来越多,表中的数据量也会越来越大,相应地,数据操作的开销也会越来越大;另外,无论怎样升级硬件资源,单台服务器的资源(CPU、磁盘、内存、网络IO、事务数、连接数)总是有限的,最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈。分表、分库和读写分离可以有效地减小单台数据库的压力。
读写分离架构图

读写分离就是:一主多从,读写分离,主动同步,是一种常见的数据库架构,一般来说:
- 主库:提供数据库写服务;
- 从库:提供数据库读服务;
- 主从之间:通过某种机制同步数据,比如MySOL的binlog
一个主从同步的集群通常称为一个“分组”,这也是分组这个概念的含义。
为什么要读写分离
- 因为数据库的“写”(写10000条数据到oracle可能要3分钟)操作是比较耗时的。
- 但是数据库的“读”(从oracle读10000条数据可能只要5秒钟)。
- 所以读写分离,解决的是,数据库的写入,影响了查询的效率。
什么时候要读写分离
数据库不一定要读写分离,如果程序使用数据库较多时,而更新少,查询多的情况下会考虑使用,利用数据库 主从同步 。可以减少数据库压力,提高性能。当然,数据库也有其它优化方案。memcache 或是 表折分,或是搜索引擎。都是解决方法。
读写分离实现
第一种:
代码已上传github : git@github.com:13849141963/mysql-maste-slave.git1.首先我们需要配置多个数据源,我是用xml进行配置的其他方法大同小异,就是多建立了几个数据源组件对象。[一主一从]
jdbc.properties
mysql.driverClassName.write = com.mysql.jdbc.Driver
mysql.url.write = jdbc:mysql://192.168.64.132:3306/slave?characterEncoding=utf8
mysql.username.write = root
mysql.password.write = root
mysql.driverClassName.read = com.mysql.jdbc.Driver
mysql.url.read = jdbc:mysql://192.168.64.135:3306/slave?characterEncoding=utf8
mysql.username.read = root
mysql.password.read = rootapplicationContext.xml
<context:property-placeholder location="classpath:jdbc.properties"/>
<!--创建写数据源-->
<bean id="writeDataSource" class="com.alibaba.druid.pool.DruidDataSource">
<property name="driverClassName" value="${mysql.driverClassName.write}"/>
<property name="url" value="${mysql.url.write}"/>
<property name="username" value="${mysql.username.write}"/>
<property name="password" value="${mysql.password.write}"/>
<!--初始化连接大小-->
<property name="initialSize" value="0"/>
<!--连接池的最大使用连接数量-->
<property name="maxActive" value="20"/>
<!--连接池的最小空闲-->
<property name="minIdle" value="0"/>
<!--获取连接最大等待时间-->
<property name="maxWait" value="60000"/>
<property name="validationQuery"><value>SELECT 1</value></property>
<property name="testOnBorrow" value="false" />
<property name="testOnReturn" value="false" />
<property name="testWhileIdle" value="true" />
<!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="60000" />
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 -->
<property name="minEvictableIdleTimeMillis" value="25200000" />
<!-- 打开removeAbandoned功能 -->
<property name="removeAbandoned" value="true" />
<!-- 1800秒,也就是30分钟 -->
<property name="removeAbandonedTimeout" value="1800" />
<!-- 关闭abanded连接时输出错误日志 -->
<property name="logAbandoned" value="true" />
<!-- 监控数据库 -->
<!-- <property name="filters" value="stat" /> -->
<property name="filters" value="mergeStat" />
</bean>
<!--创建读数据源-->
<bean id="readDataSource" class="com.alibaba.druid.pool.DruidDataSource">
<property name="driverClassName" value="${mysql.driverClassName.read}"/>
<property name="url" value="${mysql.url.read}"/>
<property name="username" value="${mysql.username.read}"/>
<property name="password" value="${mysql.password.read}"/>
<!--初始化连接大小-->
<property name="initialSize" value="0"/>
<!--连接池的最大使用连接数量-->
<property name="maxActive" value="20"/>
<!--连接池的最小空闲-->
<property name="minIdle" value="0"/>
<!--获取连接最大等待时间-->
<property name="maxWait" value="60000"/>
<property name="validationQuery"><value>SELECT 1</value></property>
<property name="testOnBorrow" value="false" />
<property name="testOnReturn" value="false" />
<property name="testWhileIdle" value="true" />
<!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="60000" />
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 -->
<property name="minEvictableIdleTimeMillis" value="25200000" />
<!-- 打开removeAbandoned功能 -->
<property name="removeAbandoned" value="true" />
<!-- 1800秒,也就是30分钟 -->
<property name="removeAbandonedTimeout" value="1800" />
<!-- 关闭abanded连接时输出错误日志 -->
<property name="logAbandoned" value="true" />
<!-- 监控数据库 -->
<!-- <property name="filters" value="stat" /> -->
<property name="filters" value="mergeStat" />
</bean>2.使用AbstractRoutingDataSource 的实现类,进行灵活的切换,可以通过AOP或者手动编程设置当前的DataSource,不用修改我们编写的对于继承AbstractRoutingDataSource 的实现类的修改,这样的编写方式比较好,至于其中的实现原理,让我细细到来。我们想看看如何去应用,实现原理慢慢的说!
private Map<Object, Object> targetDataSources;
private Object defaultTargetDataSource;
private Map<Object, DataSource> resolvedDataSources;
targetDataSources中保存了key和数据库连接的映射关系,defaultTargetDataSource表示默认的链接,resolvedDataSources这个数据结构是通过targetDataSources构建而来,存储的结构也是数据库标识和数据源的映射关系。
下面需要继承AbstractRoutingDataSource类,实现我们自己的数据库选择逻辑DynamicDataSource 类,先上代码:
/****
* 产生动态数据源 AbstractRoutingDataSource是spring提供对数据源进行选择的类
*/
public class DynamicDataSource extends AbstractRoutingDataSource {
/***
* 根据返回的key决定使用哪个数据源
* @return
*/
@Override
protected Object determineCurrentLookupKey() {
return ContextDBHolder.getDataSource();
}
}
3.创建ContextDBHolder类去设置数据源,使用ThreadLocal进行对数据源进行绑定。
public class ContextDBHolder {
//使用ThreadLocal进行绑定数据源key,同一个线程使用同一个数据源key
private static final ThreadLocal<String> t = new ThreadLocal<String>();
/****
* 设置数据源
* @param key
*/
public static void setDataSource(String key){
t.set(key);
}
/*****
* 返回数据源
*/
public static String getDataSource(){
return t.get();
}
/*****
* 释放数据源
*/
public static void closeDataSource(){
t.remove();
}
}4.创建注解 作用在方法上判断是读还是写操作
/****
* 自定义注解类型:
* @Retention :元注解-->修饰注解的注解
* RetentionPolicy:SOURCE 源码有效 编译之后不会再.class文件中
* CLASS 编译有效 编译之后会留在.class文件中 运行时不生效
* RUNTIME 运行时有效
* @Target :作用修饰自定义注解类可以加在什么位置
* ElementType:METHOD 使用在方法上
* TYPE 使用在类上
*
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface Read {
}
5.通过aop切面进行动态选择数据源
/****
* 作用:根据目标类中调用的方法往DynamicDataSource中的determineCurrentLookupKey方法动态设置返回值
* 目标类: save update delete 相关方法使用write
* query select 相关方法使用read
*/
@Component("chooseDBAdvice")
public class ChooseDBAdvice implements MethodInterceptor {
@Override
public Object invoke(MethodInvocation invocation) throws Throwable {
//获取方法对象
Method method = invocation.getMethod();
//判断当前方上是否存在read注解
boolean annotationPresent = method.isAnnotationPresent(Read.class);
if(annotationPresent){
//设置读数据源
ContextDBHolder.setDataSource("read");
System.out.println("设置读数据源~~~~~~");
}else{
//设置写数据源
ContextDBHolder.setDataSource("write");
System.out.println("设置写数据源~~~~~~");
}
//执行目标方法
Object proceed = invocation.proceed();
//释放数据源
ContextDBHolder.closeDataSource();
return proceed;
}
} <context:component-scan base-package="com.zy.cn"/>
<!--具体实现该接口的 bean-->
<context:property-placeholder location="classpath:jdbc.properties"/>
<!--创建写数据源-->
<bean id="writeDataSource" class="com.alibaba.druid.pool.DruidDataSource">
<property name="driverClassName" value="${mysql.driverClassName.write}"/>
<property name="url" value="${mysql.url.write}"/>
<property name="username" value="${mysql.username.write}"/>
<property name="password" value="${mysql.password.write}"/>
<!--初始化连接大小-->
<property name="initialSize" value="0"/>
<!--连接池的最大使用连接数量-->
<property name="maxActive" value="20"/>
<!--连接池的最小空闲-->
<property name="minIdle" value="0"/>
<!--获取连接最大等待时间-->
<property name="maxWait" value="60000"/>
<property name="validationQuery"><value>SELECT 1</value></property>
<property name="testOnBorrow" value="false" />
<property name="testOnReturn" value="false" />
<property name="testWhileIdle" value="true" />
<!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="60000" />
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 -->
<property name="minEvictableIdleTimeMillis" value="25200000" />
<!-- 打开removeAbandoned功能 -->
<property name="removeAbandoned" value="true" />
<!-- 1800秒,也就是30分钟 -->
<property name="removeAbandonedTimeout" value="1800" />
<!-- 关闭abanded连接时输出错误日志 -->
<property name="logAbandoned" value="true" />
<!-- 监控数据库 -->
<!-- <property name="filters" value="stat" /> -->
<property name="filters" value="mergeStat" />
</bean>
<!--创建读数据源-->
<bean id="readDataSource" class="com.alibaba.druid.pool.DruidDataSource">
<property name="driverClassName" value="${mysql.driverClassName.read}"/>
<property name="url" value="${mysql.url.read}"/>
<property name="username" value="${mysql.username.read}"/>
<property name="password" value="${mysql.password.read}"/>
<!--初始化连接大小-->
<property name="initialSize" value="0"/>
<!--连接池的最大使用连接数量-->
<property name="maxActive" value="20"/>
<!--连接池的最小空闲-->
<property name="minIdle" value="0"/>
<!--获取连接最大等待时间-->
<property name="maxWait" value="60000"/>
<property name="validationQuery"><value>SELECT 1</value></property>
<property name="testOnBorrow" value="false" />
<property name="testOnReturn" value="false" />
<property name="testWhileIdle" value="true" />
<!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="60000" />
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 -->
<property name="minEvictableIdleTimeMillis" value="25200000" />
<!-- 打开removeAbandoned功能 -->
<property name="removeAbandoned" value="true" />
<!-- 1800秒,也就是30分钟 -->
<property name="removeAbandonedTimeout" value="1800" />
<!-- 关闭abanded连接时输出错误日志 -->
<property name="logAbandoned" value="true" />
<!-- 监控数据库 -->
<!-- <property name="filters" value="stat" /> -->
<property name="filters" value="mergeStat" />
</bean>
<!--管理动态数据源-->
<bean id="dynamicDataSource" class="com.zy.cn.config.DynamicDataSource">
<property name="targetDataSources">
<map>
<entry key="write" value-ref="writeDataSource"/>
<entry key="read" value-ref="readDataSource"/>
</map>
</property>
<!--<property name="defaultTargetDataSource" value="writeDataSource"/>-->
</bean>
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dynamicDataSource"/>
<property name="mapperLocations" value="com/zy/cn/mapper/*.xml"/>
<property name="typeAliasesPackage" value="com.zy.cn.entity"/>
</bean>
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="com.zy.cn.dao"></property>
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"/>
</bean>
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dynamicDataSource"/>
</bean>
<tx:annotation-driven transaction-manager="transactionManager" order="2"/>
<!-- 配置druid监控spring jdbc -->
<bean id="druid-stat-interceptor"
class="com.alibaba.druid.support.spring.stat.DruidStatInterceptor">
</bean>
<bean id="druid-stat-pointcut" class="org.springframework.aop.support.JdkRegexpMethodPointcut"
scope="prototype">
<property name="patterns">
<list>
<value>com.zy.cn.dao</value>
</list>
</property>
</bean>
<aop:config>
<aop:advisor advice-ref="druid-stat-interceptor"
pointcut-ref="druid-stat-pointcut" order="3"/>
</aop:config>
<!--配置数据源切面-->
<aop:config proxy-target-class="true">
<aop:pointcut id="pc" expression="execution(* com.zy.cn.service.*.*(..))"></aop:pointcut>
<aop:advisor advice-ref="chooseDBAdvice" pointcut-ref="pc" order="1"></aop:advisor>
</aop:config>6.测试增加,修改,查询可以看出动态切换数据源,说明读写分离搭建成功。
第二种:
Mycat 是一个强大的数据库中间件,不仅仅可以用作读写分离、以及分表分库、容灾备份,而且可以用于多
租户应用开发、云平台基础设施、让你的架构具备很强的适应性和灵活性,借助于即将发布的 Mycat 智能优化模
块,系统的数据访问瓶颈和热点一目了然,根据这些统计分析数据,你可以自动或手工调整后端存储,将不同的
表映射到不同存储引擎上,而整个应用的代码一行也不用改变.
架构图如下:

搭建步骤 【在这里我们只做读写分离】:和上面两台机器一样
1.linux环境下安装mycat数据库中间件 下载地址:http://dl.mycat.io/ 加压:tar -zxvf Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz
2.安装jdk,版本需在1.7以及以上配置环境变量
3.修改mycat 中的conf文件夹下的server.xml,schema.xml文件 【标签属性请参看mycat官方文档】
server.xml
mycat登录的用户名
<user name="root">mycat登录的密码
<property name="password">123456</property>
别名[随便]
<property name="schemas">TESTDB</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
<user name="user">
<property name="password">user</property>
<property name="schemas">TESTDB</property>
该用户只能进行读操作
<property name="readOnly">true</property>
</user>schema.xml
<mycat:schema xmlns:mycat="http://io.mycat/">
对应server.xml中schema标签的值
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
<table name="user" dataNode="dn1"/>
</schema>
<!-- 定义MyCat的数据节点 db1为需要操作的数据库-->
<dataNode name="dn1" dataHost="localhost" database="db1" />
<dataHost name="localhost" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!--配置后台数据库的IP地址和端口号,还有账号密码 -->
<!-- master负责写 -->
<writeHost host="hostM1" url="192.168.64.137:3306" user="root"
password="root">
<!--slave负责读-->
<readHost host="hostS2" url="192.168.64.136:3306" user="root" password="root" />
</writeHost>
</dataHost>
</mycat:schema>4.启动mycat中间件 bin目录下启动
./mycat start5.查看日志文件 log目录下
tail -f -n 100 wrapper.log6.连接mycat 用户名密码均为mycat中server.xml中进行配置的
mysql -uroot -p123456 -h192.168.64.138 -P8066 -DTESTDB7.测试: 在user表中name字段用主机IP,通过日志查询发现只会出现从机上的数据IP端口为从机的端口,添加也是一样的,
select * from user;















 147
147











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









