






自然语言处理BERT模型
1.环境配置
首先安装pytorch环境,python3.8环境
conda activate torchCopy # 激活环境
conda install transformer # 安装transformer库
2.代码下载
下载预训练的中文数据集模型,选择如下6个文件下载https://hf-mirror.com/google-bert/bert-base-chinese/tree/main

项目结构:

训练好的模型:best.pt
2.1 数据集加载bert_get_data.py
# -*- coding: utf-8 -*-
import pandas as pd
from torch.utils.data import Dataset, DataLoader
from transformers import BertTokenizer
from torch import nn
from transformers import BertModel
bert_name = './bert-base-chinese'
tokenizer = BertTokenizer.from_pretrained(bert_name)
class MyDataset(Dataset):
def __init__(self, df):
# tokenizer分词后可以被自动汇聚
self.texts = [tokenizer(text,
padding='max_length', # 填充到最大长度
max_length=35, # 经过数据分析,最大长度为35
truncation=True,
return_tensors="pt")
for text in df['text']]
# Dataset会自动返回Tensor
self.labels = [label for label in df['label']]
def __getitem__(self, idx):
return self.texts[idx], self.labels[idx]
def __len__(self):
return len(self.labels)
class BertClassifier(nn.Module):
def __init__(self):
super(BertClassifier, self).__init__()
self.bert = BertModel.from_pretrained(bert_name)
self.dropout = nn.Dropout(0.5)
self.linear = nn.Linear(768, 10)
self.relu = nn.ReLU()
def forward(self, input_id, mask):
_, pooled_output = self.bert(input_ids=input_id, attention_mask=mask, return_dict=False)
dropout_output = self.dropout(pooled_output)
linear_output = self.linear(dropout_output)
final_layer = self.relu(linear_output)
return final_layer
def GenerateData(mode):
train_data_path = './THUCNews/data/train.txt'
dev_data_path = './THUCNews/data/dev.txt'
test_data_path = './THUCNews/data/test.txt'
train_df = pd.read_csv(train_data_path, sep='\t', header=None)
dev_df = pd.read_csv(dev_data_path, sep='\t', header=None)
test_df = pd.read_csv(test_data_path, sep='\t', header=None)
new_columns = ['text', 'label']
train_df = train_df.rename(columns=dict(zip(train_df.columns, new_columns)))
dev_df = dev_df.rename(columns=dict(zip(dev_df.columns, new_columns)))
test_df = test_df.rename(columns=dict(zip(test_df.columns, new_columns)))
train_dataset = MyDataset(train_df)
dev_dataset = MyDataset(dev_df)
test_dataset = MyDataset(test_df)
if mode == 'train':
return train_dataset
elif mode == 'val':
return dev_dataset
elif mode == 'test':
return test_dataset
2.2 训练部分bert_train.py
# -*- coding: utf-8 -*-
import torch
from torch import nn
from torch.optim import Adam
from tqdm import tqdm
import numpy as np
import random
import os
from torch.utils.data import Dataset, DataLoader
from .bert_get_data import BertClassifier, MyDataset, GenerateData
def setup_seed(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
random.seed(seed)
torch.backends.cudnn.deterministic = True
def save_model(save_name):
if not os.path.exists(save_path):
os.makedirs(save_path)
torch.save(model.state_dict(), os.path.join(save_path, save_name))
# 训练超参数
epoch = 5
batch_size = 64
lr = 1e-5
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
random_seed = 20240121
save_path = './bert_checkpoint'
setup_seed(random_seed)
# 定义模型
model = BertClassifier()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=lr)
model = model.to(device)
criterion = criterion.to(device)
# 构建数据集
train_dataset = GenerateData(mode='train')
dev_dataset = GenerateData(mode='val')
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
dev_loader = DataLoader(dev_dataset, batch_size=batch_size)
# 训练
best_dev_acc = 0
for epoch_num in range(epoch):
total_acc_train = 0
total_loss_train = 0
for inputs, labels in tqdm(train_loader):
input_ids = inputs['input_ids'].squeeze(1).to(device) # torch.Size([32, 35])
masks = inputs['attention_mask'].to(device) # torch.Size([32, 1, 35])
labels = labels.to(device)
output = model(input_ids, masks)
batch_loss = criterion(output, labels)
batch_loss.backward()
optimizer.step()
optimizer.zero_grad()
acc = (output.argmax(dim=1) == labels).sum().item()
total_acc_train += acc
total_loss_train += batch_loss.item()
# ----------- 验证模型 -----------
model.eval()
total_acc_val = 0
total_loss_val = 0
with torch.no_grad():
for inputs, labels in dev_loader:
input_ids = inputs['input_ids'].squeeze(1).to(device) # torch.Size([32, 35])
masks = inputs['attention_mask'].to(device) # torch.Size([32, 1, 35])
labels = labels.to(device)
output = model(input_ids, masks)
batch_loss = criterion(output, labels)
acc = (output.argmax(dim=1) == labels).sum().item()
total_acc_val += acc
total_loss_val += batch_loss.item()
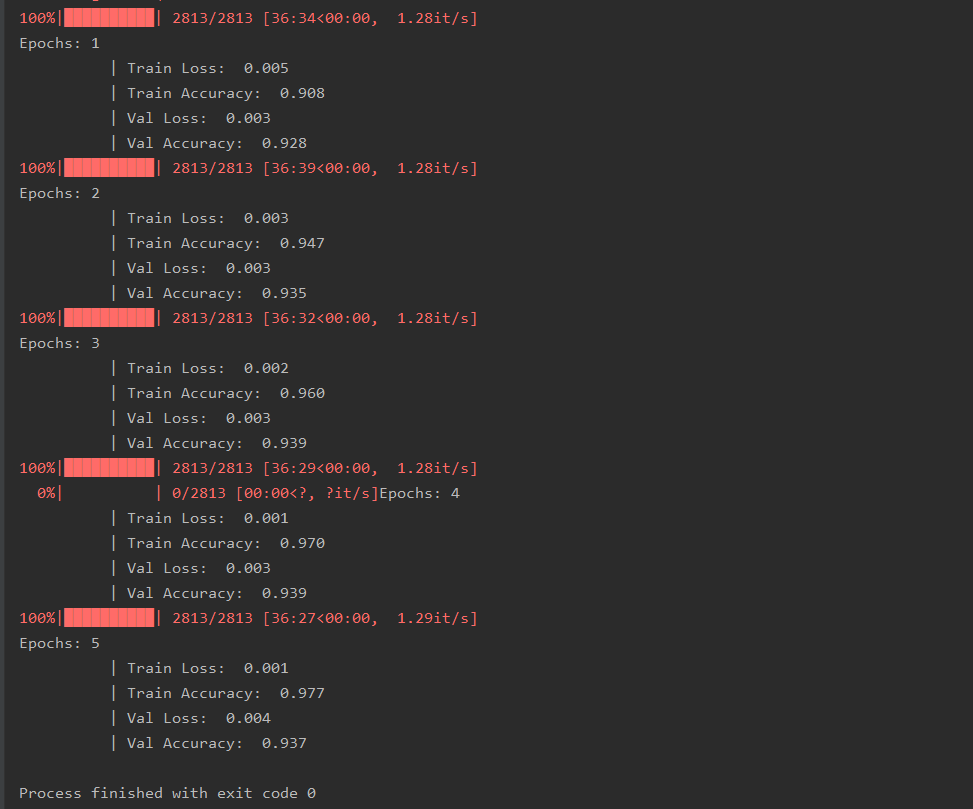
print(f'''Epochs: {epoch_num + 1}
| Train Loss: {total_loss_train / len(train_dataset): .3f}
| Train Accuracy: {total_acc_train / len(train_dataset): .3f}
| Val Loss: {total_loss_val / len(dev_dataset): .3f}
| Val Accuracy: {total_acc_val / len(dev_dataset): .3f}''')
# 保存最优的模型
if total_acc_val / len(dev_dataset) > best_dev_acc:
best_dev_acc = total_acc_val / len(dev_dataset)
save_model('best.pt')
model.train()
# 保存最后的模型
save_model('last.pt')
2.3 测试部分 bert_test.py
# -*- coding: utf-8 -*-
import os
import torch
from .bert_get_data import BertClassifier, GenerateData
from torch.utils.data import DataLoader
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
save_path = './bert_checkpoint'
model = BertClassifier()
model.load_state_dict(torch.load(os.path.join(save_path, 'best.pt')))
model = model.to(device)
model.eval()
def evaluate(model, dataset):
model.eval()
test_loader = DataLoader(dataset, batch_size=128)
total_acc_test = 0
with torch.no_grad():
for test_input, test_label in test_loader:
input_id = test_input['input_ids'].squeeze(1).to(device)
mask = test_input['attention_mask'].to(device)
test_label = test_label.to(device)
output = model(input_id, mask)
acc = (output.argmax(dim=1) == test_label).sum().item()
total_acc_test += acc
print(f'Test Accuracy: {total_acc_test / len(dataset): .3f}')
test_dataset = GenerateData(mode="test")
evaluate(model, test_dataset)
2.4 交互式推理 bert_util.py
# -*- coding: utf-8 -*-
import os
from transformers import BertTokenizer
import torch
from bert_get_data import BertClassifier
bert_name = './bert-base-chinese'
tokenizer = BertTokenizer.from_pretrained(bert_name)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
save_path = './bert_checkpoint'
model = BertClassifier()
model.load_state_dict(torch.load(os.path.join(save_path, 'best.pt')))
model = model.to(device)
model.eval()
real_labels = []
with open('./THUCNews/data/class.txt', 'r') as f:
for row in f.readlines():
real_labels.append(row.strip())
while True:
text = input('请输入新闻标题:')
bert_input = tokenizer(text, padding='max_length',
max_length = 35,
truncation=True,
return_tensors="pt")
input_ids = bert_input['input_ids'].to(device)
masks = bert_input['attention_mask'].unsqueeze(1).to(device)
output = model(input_ids, masks)
pred = output.argmax(dim=1)
print(real_labels[pred])
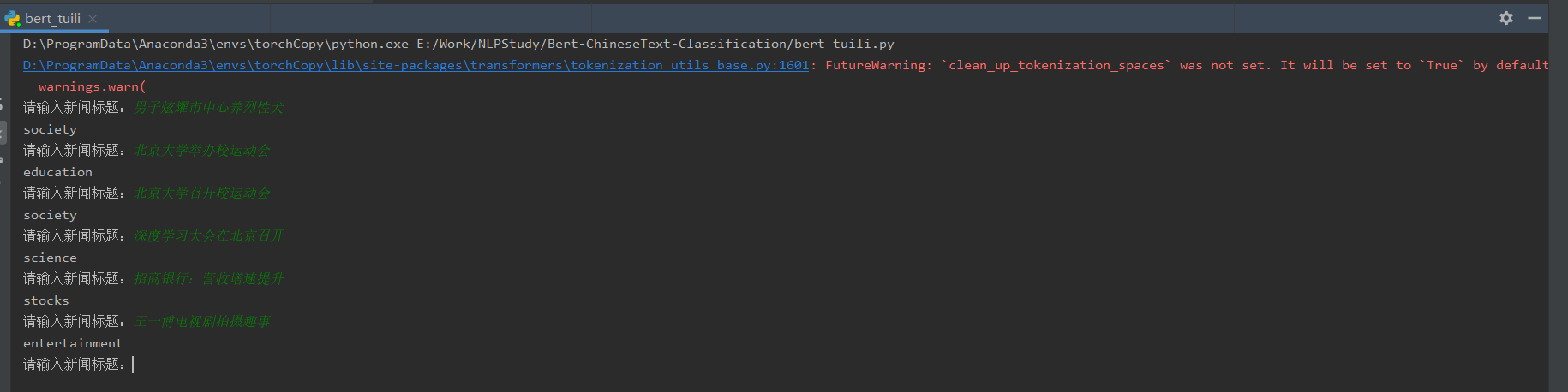
# 男子炫耀市中心养烈性犬?警方介入 society
# 北京大学举办校运动会 education
# 深度学习大会在北京召开 science
# 招商银行:营收增速提升 stocks
# 王一博电视剧拍摄趣事 entertainment
3. 运行结果
训练界面:
测试界面:

交互式推理:















 1090
1090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









