









 本文探讨了CPU缓存行的重要性,如何利用64字节的大小提高效率,以及MESI一致性协议在多核处理中的作用。通过示例代码说明了缓存行在程序性能优化中的应用。
本文探讨了CPU缓存行的重要性,如何利用64字节的大小提高效率,以及MESI一致性协议在多核处理中的作用。通过示例代码说明了缓存行在程序性能优化中的应用。
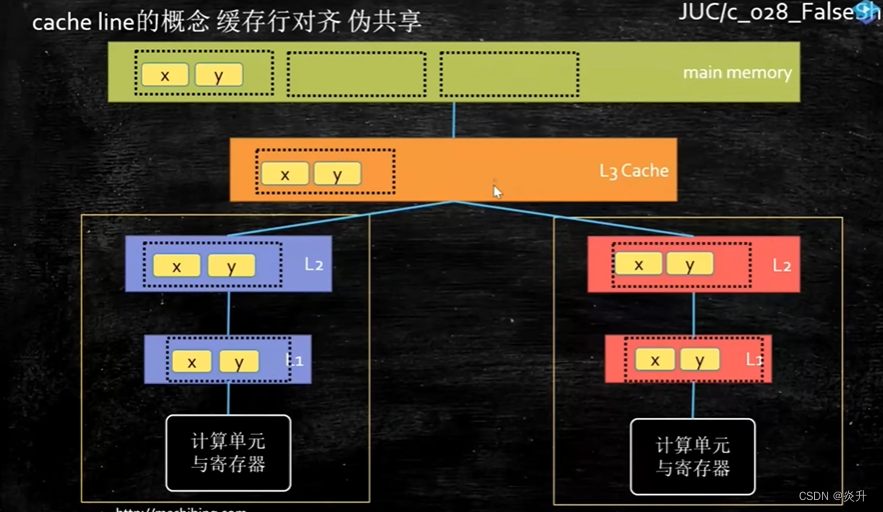
Cache Line可以简单的理解为CPU Cache中的最小缓存单位。前主流的CPU Cache的Cache Line大小都是64个字节。
CPU从内存读取数据时实际是按块读取的,有什么好处呢?程序局部性原理,可以提高效率,充分发挥总线CPU针脚等一次性读取更多数据的能力。因为多数情况下CPU处理完一个数据后会处理该数据旁边的数据,所以按块去读取时,将一块数据一起读过来放入缓存,这样CPU处理完一个直接从缓存中取下一个,不需要再去内存取,极大的提高了局部性空间效率。这一块数据就被叫做缓存行。
那一个缓存行能放多大的数据呢,目前业界都是用的64字节,这是一个经验值,缓存行越大,局部性空间效率越高,但读取时间慢;反之缓存行越小,局部性空间效率越低,但读取时间快,所以就取了一个折中值:64字节。
在多核CPU就会遇到这样一个问题,xy的数据在一个缓存行,第一个核将x改了,第二个核将y改了,他们再使用另一个值的时候,他们都不知道值变了,这就是缓存一致性的问题,怎么来解决这个问题呢? 看下面这个图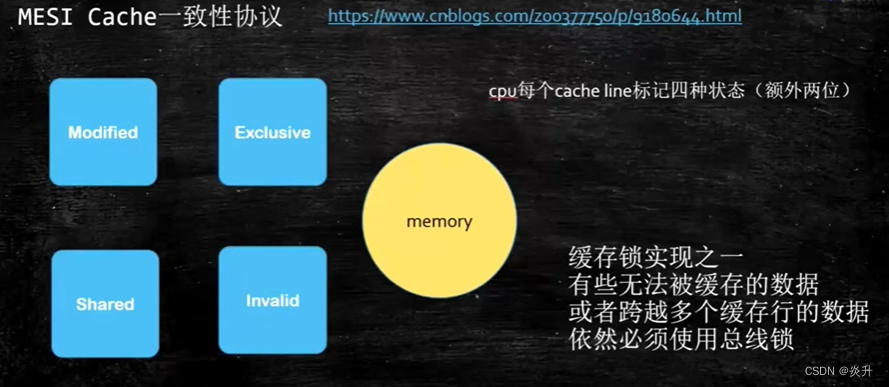
MESI (Modify+Eclusive+Shared+Inviled)cache一致性协议,这个是Intel的协议,不同的厂商有不同的协议,这里是给了缓存行四种状态:
- Modified--被修改了
- Exclusive--独占
- Shared--共享
- Invalid--无效的
这些协议是怎么生效的,如上图中x被改了之后他给自己标记成Modified,然后数据写回内存后通知其他核,给他们的这个缓存行状态改成Invalid,意思就是告诉他们我改过了,你们这个都无效了,如果需要用到最新数据,重新去内存中取。除了MESI 还有MSI,MOSI等缓存一致性协议。
缓存行示例代码:
/**
* 64位x86CPU,缓存行大小64B
*
* 测试一:23756 ms
* 测试二:5688 ms
* 性能提高4倍
*/
public class CacheLineTest {
private static final int NUM = 1000000000;
private static class T{
// private long t1,t2,t3,t4,t5,t6,t7;
private volatile long l = 0L;
// private long tt1,tt2,tt3,tt4,tt5,tt6,tt7;
}
public static T[] ts = new T[2];
static {
ts[0] = new T();
ts[1] = new T();
}
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch = new CountDownLatch(2);
long satrtTime = System.currentTimeMillis();
Thread th1 = new Thread("thread-1"){
@Override
public void run() {
for(int i=0;i<NUM;i++){
ts[0].l = i;
}
latch.countDown();
}
};
Thread th2 = new Thread("thread-2"){
@Override
public void run() {
for(int i=0;i<NUM;i++){
ts[1].l = i;
}
latch.countDown();
}
};
th1.start();
th2.start();
latch.await();
long endTime = System.currentTimeMillis();
System.out.println(endTime-satrtTime);
}
}

















 2102
2102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









